정규화(normalization)
관계형 DB 설계에서 중복을 최소화하고 데이터 일관성을 유지하기 위해 데이터의 구조를 조직화하는 프로세스이다.
주로 테이블을 작은 단위로 분리하여 중복을 제거하고, 이상 현상(anomalies)을 방지하는 데 사용된다.
Normal forms
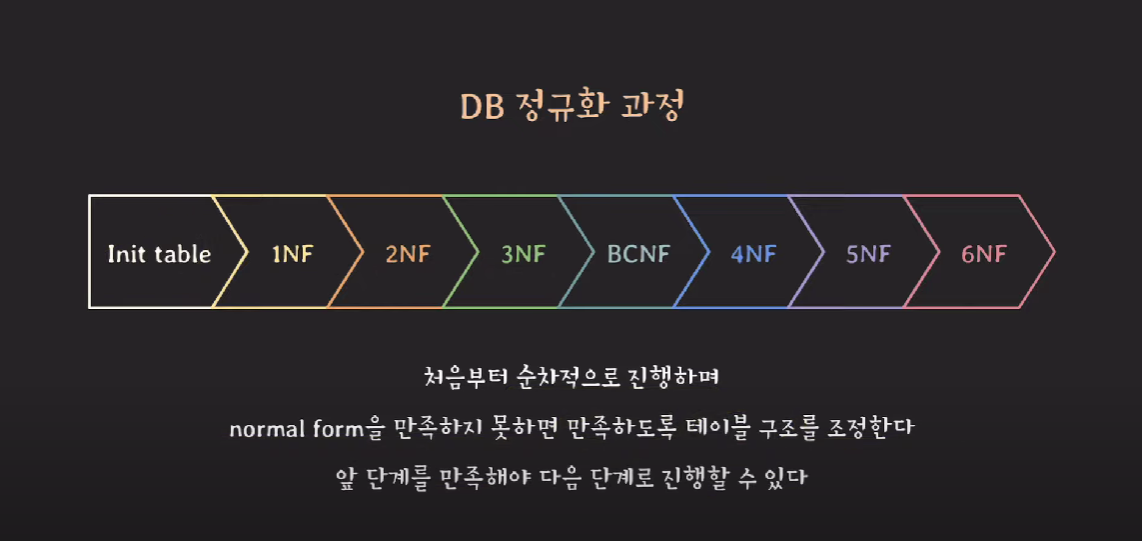
정규화 되기 위해 준수해야 하는 몇 가지 rule 들이 있는데, 이 각각의 rule 을 normal form(NF) 이라고 한다.
DB 정규화 과정
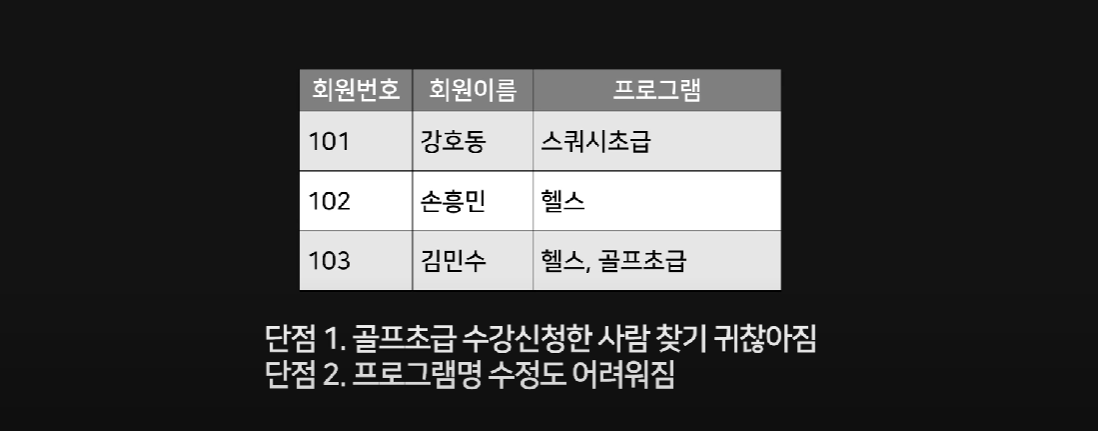
제1 정규형
원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 작업
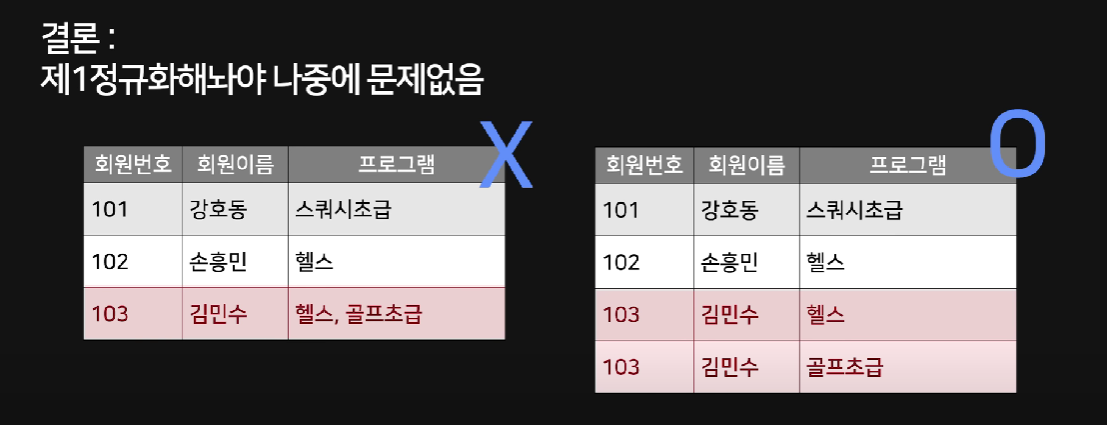
장점 : 데이터의 중복을 최소화하고 데이터 일관성을 유지할 수 있음
단점 : 중첩된 데이터를 허용하지 않기 때문에 데이터 구조를 더 복잡하게 만들 수 있음
제2 정규형
현재 테이블의 주제와 관련없는 컬럼을 다른 테이블로 빼는 작업
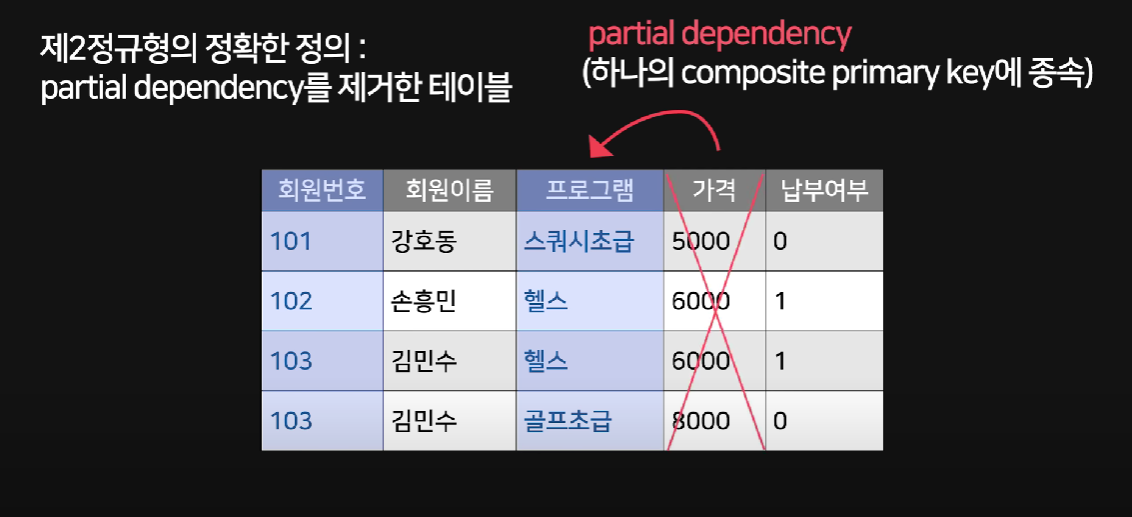
Partial Dependency : 부분적 종속
Composite Primary Key : 복합키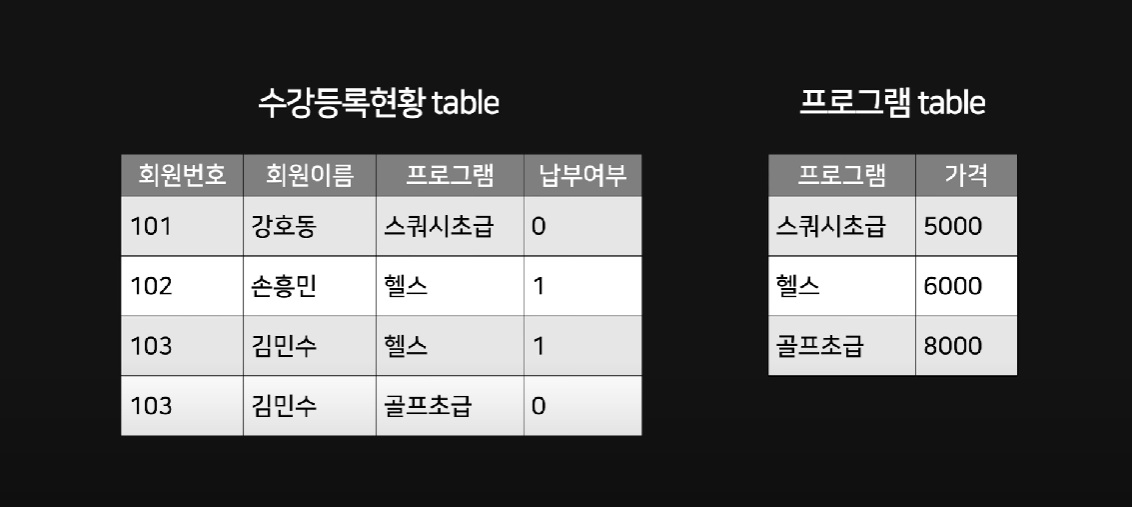
장점 : 데이터의 수정 작업이 편리해짐
단점 : 테이블의 분리로 인해 일부 쿼리가 복잡해질 수 있음
제3 정규형
일반 컬럼에만 종속된 컬럼은 다른 테이블로 빼는 작업
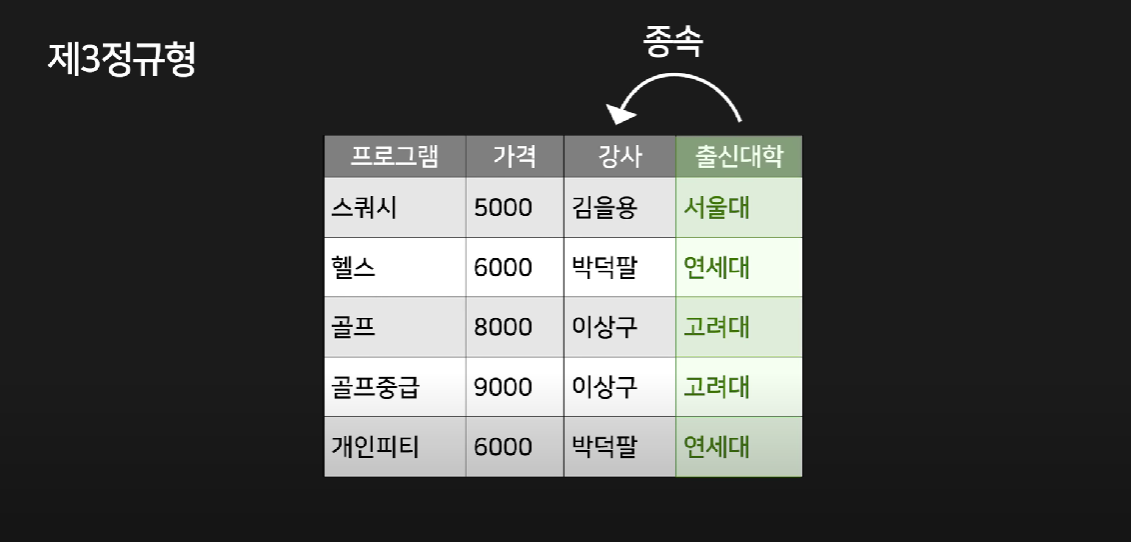
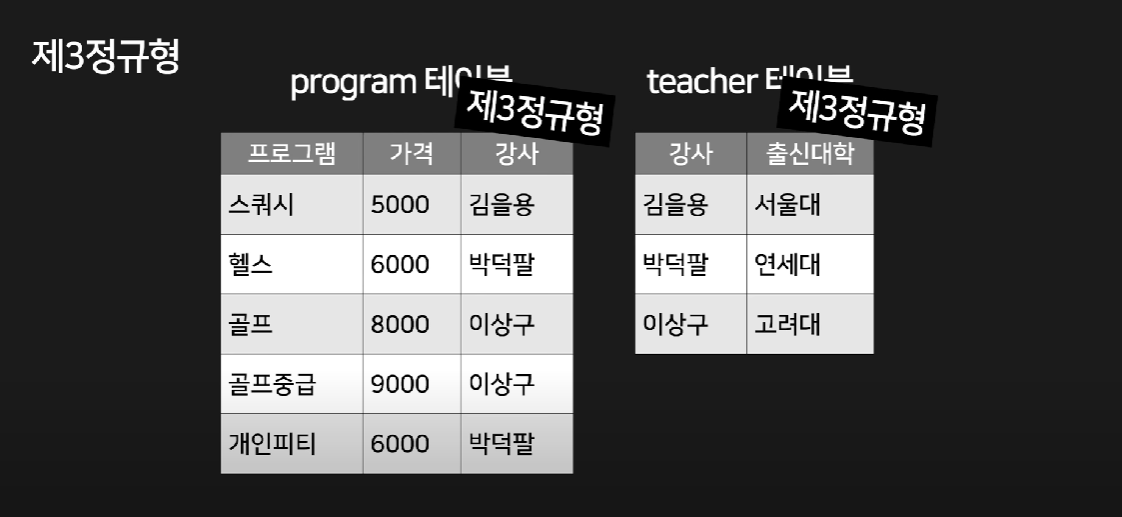
장점 : 데이터 수정 시 발생할 수 있는 이상 현상을 방지함
단점 : 정규화된 데이터베이스는 조인을 많이 필요로 하므로 읽기 작업이 많은 시스템에서 성능 문제가 발생할 수 있음
관계형 DB 들은 정규화를 해두는게 일반적이지만 비관계형 DB 들은 정규화를 안하는 경우가 많다.
역정규화 (Denormalization)
역정규화는 성능을 향상시키기 위해 정규화된 DB 를 다시 중복을 포함하는 형태로 변경하는 프로세스이다.
테이블을 너무 많이 잘게 쪼개면 여러 테이블들이 모두 동시에 조인을 하게 되기 때문에 성능이 느려지는 이슈가 발생할 수 있고, 관리하기 어려워질 수 있다.
-
일반적으로 쿼리의 성능을 향상시키기 위해 사용되며, 특히 읽기 작업이 많은 시스템에서 유용하다.
-
데이터의 일부를 중복 저장하거나 중복 인덱스를 생성함으로써 데이터에 대한 읽기 액세스를 최적화한다.
-
하지만 데이터 일관성을 유지하기 위해 조심스럽게 사용되어야 한다.
정리
정규화는 데이터 일관성과 구조를 유지하고 중복을 최소화하기 위해 데이터를 정리하는 반면, 역정규화는 읽기 성능을 향상시키기 위해 중복을 허용하는 방향으로 데이터를 재구성하는 것이다.
DB 를 설계할 때 과도한 조인과 중복 데이터 최소화 사이에서 적정 수준을 선택할 필요가 있다.
출처
데이터 정규화가 뭔지 설명해보세요 (개발면접타임)
https://youtu.be/Y1FbowQRcmI?si=qohrNhajyETA2evF
(1부) DB 정규화(normalization)는 DB를 설계하는 공식적인 방법이죠~ 1부에서는 정규화 개념과 정규화 과정의 앞 부분인 1NF, 2NF를 설명합니다 :)
https://youtu.be/EdkjkifH-m8?si=aEX_ni05tFE1jQPj
(2부) DB 정규화(normalization) 2부입니다!! 3NF, BCNF와 2NF 참고 사항, 역정규화(denormalization)까지 설명합니다!!
https://youtu.be/5QhkZkrqFL4?si=aUKZ81mNL7mLalSJ
