최근 DR( Disaster Recovery, 재해복구)이 핫하다.
이글의 연재를 목표로 하고 있는 기간이 약 1년이니까, 글의 연재가 끝날때 쯤에는 핫하지 않을 수도 있다. 하지만, 어쨌던 DR은 필요하고, 한번쯤 정리를 해보고 싶었기에 이번 기회를 빌미로 한번 정리해보려고 한다.
예전부터 DR 그리고, 멀티리전 서비스에 대해서는 관심이 많았다.
그러나, 현실적으로도 일이 너무 바쁘고, 실제로 구현을 할 필요가 있을까.. 싶어서 계속 미뤄두기만 하던 와중에 카카오 사태가 발생을 하였다.
그래서, 더 이상은 미루지 않아도 되겠다 싶어서 1년을 기한으로 천천히 시작하려고 한다.
연재 글을 진행하기에 앞서, DR의 정의 그리고 어느정도까지 진행할지 바운더리는 잡아야 하기에 첫번째 글은 그러한 내용으로 할애를 하려고 한다.
우선 용어의 의미 부터 정의를 한다.
아무리 찾아봐도 이 부분에 대해서는 약간씩은 다르게 해석하는 부분이 있다.
가장 큰 이유는 돈을 지출하는쪽의 입장과 그 솔루션을 판매하는 입장이 다르고 여러가지 입장이 다르기에 다르게 해석하는것이 있다.
따라서, 나도 내 입맛대로 내 맘대로 해석하려 한다.
가장 낮은 수준의 DR : 백업 / Cold DR
현재 서비스 되고 있는 데이터를 안전을 위해 백업하는 수준이다.
이 부분은 사실 제일 쉬운 부분이고, 아무리 작은 스타트업이라고 해도 거의 대부분 하고 있을것이다.
최신의 DBMS들은 실시간 복제기능을 대부분 지원하고 있고, 실시간으로 원격지에 데이터를 복제/백업하는것도 대부분 지원한다.
예를들어, 서울에 메인시스템과 DB가 있고, 그 데이터들을 네트워크를 통해 실시간으로 부산에 있는 데이터센터와 싱가포르에 있는 데이터센터에 실시간백업을 한다.
응용프로그램의 경우에도 비슷하게 배포하는 단계에서 여러군데 복제를 해두면 재난시 손쉽게 복구가 가능한데, 이 부분은 아래에서 다시 언급할것이다.
다만, 이러한 방식으로는 재난시 실시간 복구는 당연히 불가능하고, 서버를 손쉽게 구할 수 있다는 전제하에, 서버들에 데이터를 옮겨 담는 시간 + 설정하는데 필요한 시간만큼의 재난복구(DR) 시간이 소요된다.
그래서 가장 권장되지 않는.. 그러나 비용도 노력도 제일 낮은 수준의 DR이다.
보통 수준의 DR : Warm DR
사전에 예비 데이터센터에 시스템을 구축해 놓은 형태이다.
메인 센터에 재난상황이 발생하기면 예비센터의 시스템들을 켜고, 즉시 사용 가능하도록 구축을 해놓은것을 의미한다. 물론 이때에도 DB의 경우에는 항상 켜져 있어서 실시간으로 동기화가 되어 있어야 한다. ( 그래야 데이터 손실이 없으니까.. )
서비스용 시스템은 구축만 되어 있는 형태로 가동을 안하는 형태고 언제든 빠르게 동작이 가능한 형태로 이해하면 된다.
높은 수준의 DR : Active DR
항상 켜져 있는 예비 센터라고 이해를 하면 된다.
사실상, LB (로드밸런싱/부하분산: load balancing )과 개인적으로는 구분이 되지 않는다.
관련된 이야기는 아래에서 다시 이야기 할꺼고...
우선 예비 데이터센터라고는 하나, 항상 서비스가 가능하고, 데이터는 당연히 실시간 동기화. 사용하는 용도에 따라서 트래픽을 항상 메인 센터에서 처리하되, 비상시에만 예비 센터로 돌리는 경우에는 DR이 되는것이고, 평소에도 트래픽이 균등하게 처리된다면, LB가 되는것이다.
내가 앞으로 연재할 내용의 범위는 다음과 같다.
-
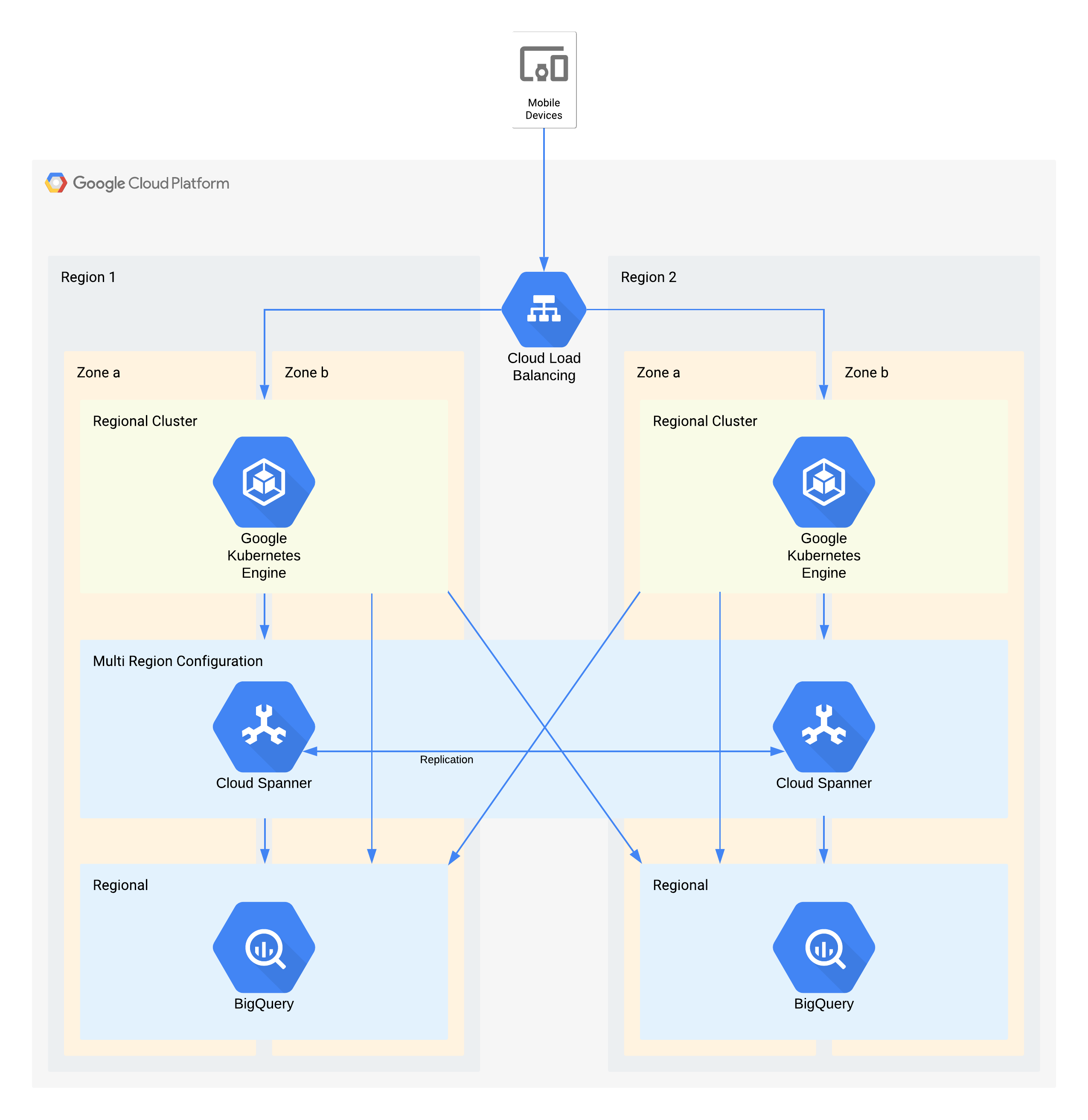
우선 모든 시스템은 GCP(Google Cloud Platform)에서 구축한다.
현재 우리회사에서 사용하는 시스템은 GCP이기에 GCP베이스로 모든것을 이야기 할것이다. 사실 타사 클라우드도 기본 내용은 동일하다. 일부 용어가 미세하게 다를 순 있는데, 구글의 시스템이 워낙 업계 공용에 가까운 기본용어라, 누구나 쉽게 이해할 수 있다. 그러나, 온프렘으로 하는 경우와는 완전히 다를것이다. 클라우드의 특성상 매우 짧은 시간에 서버를 빌릴 수도 있고, 사용을 안하면 손쉽게 삭제도 가능하기 때문이다. 여러가지 다양한 부가 서비스도 제공하고, 전세계 수많은 리전 ( 글을 쓰는 이 시점에 35개 리전, 그리고 앞으로 계획된 10여개의 추가 리전 )들이 있기에 다양한곳에 데이터를 분산 저장할 수 있으며, 극단적으로 데이터센터에 소행성이 떨어지거나 지진이 발생한다 하더라도, 멀티리전 시스템을 구축해 놨다면, 정상적으로 동작이 가능하기 때문이다. -
멀티리전 서비스
앞에서 언급했듯이 여러개의 리전에서 동시에 동작하는 형태의 서비스를 준비한다.
현재 회사에서 서비스준비중(런칭직전)인 서비스가 기본적으로 해외진출을 목표로 하고 있기도 하고, 멀티리전으로 구축해 놓은뒤 만약에, 하나의 리전자체에 큰 문제가 생기면 - ex: 일본 대지진으로 데이터센터가 파괴 - 다른 리전에서 즉시 복구가 가능할 수 있다.
구글에서는 그래서 데이터 저장 옵션에 멀티리전이라는것이 있다. 멀티리전을 선택하고 데이터를 저장하는 경우 최소 100마일(161Km) 이상으로 멀리 떨어진 데이터센터에 데이터를 복제하고, 해당 데이터를 이용해서 서비스를 하는 설정이 가능하다.
복잡한 설정없이도 간단하게 데이터저장 옵션에서 멀티리전만 선택해주면 자동으로 동기화가 되니 편리한 기능이다. 다만, 멀티리전을 할때 양쪽에서 동시에 데이터를 입력하는 부분은 조금 복잡하다. 그나마 데이터 파일의 경우에는 한곳에만 입력하면 자동으로 동기화하는게 매우 쉬운 편인데, DB의 경우에는 상당히... 고도의 복잡성을 요구한다.
이 부분은 연재를 하면서 이야기를 진행할것이다.
앞에서도 이야기 했지만, 서비스를 하는데 필요한 데이터는 크게 2가지이다.
하나는 각종 정보가 담긴 DB이고, 또 다른 하나는 실행 파일이다.
DB는 앞에서도 간단히 언급했지만 향후 자세히 다시 다룰 것이고,
실행파일의 경우에는 Docker Image의 형태로 만들어서 Artifact Registry (AR) 라는곳에 저장을 한다. 비공개되어 있는 Docker Hub 같은곳으로 이해하면 된다. AR에는 docker image도 저장가능하고, npm 도 저장가능하고, 경우에 따라 다양한 패키지 파일들이 저장가능하다. 앞에서 이야기한 데이터와 마찬가지로 Region 단위로 설정이 가능하고, 필요하면 대륙단위로도 저장이 가능하다.
멀티리전의 목표는 서울 혹은 도쿄 리전과 싱가포르 리전. 두군데에 구축하는것을 목표로 한다. ( 도쿄 리전과 싱가포르 리전을 선택하는 이유는 다른 아시아 리전들과 다르게 임대형 데이터센터가 아닌 구글의 자체 데이터센터이기 때문이다. 도쿄는 현재 임대중이나, 내년에 센터가 구축된다고 뉴스에 공개되었다. ) -
기본적인 시스템은 GKE( Google Kubernetes Engine )으로 구축된다.
GKE는 기본적으로 자체적으로도 로드밸런싱이나, DR등이 되는 시스템이다.
예를들면, 3대의 머신으로 서비스를 하는중 한대의 머신이 돌발상황으로 셧다운이 되면, 나머지 2대로 서비스가 동작하며, 가능하다면 새로운 머신을 스스로 켜서 구축을 한뒤 다시 3대로 서비스를 하는것을 목표로 만들어진 솔루션이다.
예시가 3대라서 티가 안날 수 있는데, 이게 30여대의 서버로 돌아가는 시스템이라면, 1대쯤 죽어도, 관리자가 전혀 신경을 안쓰고도 자동으로 복구된다는 의미이다. 게다가, 서버에 부하가 커지면 자동으로 스케일링도 가능해서 사용량이 많은 시간에는 50대까지도 늘렸다가, 사용량이 줄어들면 10대 정도로 자동으로 줄이는 설정이 가능하다.
나중에 다시 이야기 하겠지만 굉장히 다양한 재주를 가진 솔루션이다. 구글에서 직접 만들고, 오픈소스로 내놓은 훌륭한 제품.
정리를 하면, GCP 를 사용하여 멀티리전 서비스를 구축할 계획이다.
맨앞단의 로드밸런서는 Anycast를 지원하는 구글의 GCLB를 활용하고,
동작하는 서버 시스템은 GKE를 이용하여 멀티리전에 구축을 할 계획이다.
데이터 시스템은 기본적으로 Cloud SQL을 활용하고 장기적으로는 AlloyDB 를 생각하고 있다. 역시 자세한 이야기들은 연재를 하면서 풀어나갈 계획이다.
급하게 연재하지 않으려고 한다. 실제로 하나 하나 해가면서 서비스 구축이 가능한 수준으로 할것이기에, 난이도도 좀 있을것이고..
어쨌던 그동안 벼르고 벼르던 연재.. 재미있게 한번 해보자.
