목표: tensorflow 2.x object detection api로 생성한 saved-model을 tensorRT로 변환
tf에서 TF-TRT를 지원하지만 jetson 기기에서 사용하기에는 saved-model의 로딩시간이 상당히 길고 inference 속도도 tensorRT에 비해 느리다.
결과: mAP 하락 없이도 tensorRT가 빠르고 가볍다.
- tf 2.4 / tensorRT 7.1.3
- efficientDet
| unit: sec | saved-model | TF-TRT | TensorRT |
|---|---|---|---|
| loading | 350 | 350 | 7.5 |
| inference | 0.11 | 0.06 | 0.04 |
요약: tf 2.x saved-model ➡️ onnx ➡️ tensorRT
- saved-model ➡️ onnx: tf2onnx(tensorflow-onnx)
https://github.com/onnx/tensorflow-onnx - onnx 수정: onnx-graphsurgeon
- saved-model의 nms 과정 전체를 tensorRT에서 지원하는 NMS 노드로 치환
- BatchedNMS_TRT
- BatchedNMSDynamic_TRT
- saved-model의 nms 과정 전체를 tensorRT에서 지원하는 NMS 노드로 치환
- onnx ➡️ tensorRT
과정
0. tf 2.x는 saved-model ➡️ onnx ➡️ tensorRT 과정을 거친다.
https://stackoverflow.com/questions/66087844/jetson-nx-optimize-tensorflow-model-using-tensorrt
tensorRT developer guide에도 tf2.x에 대해서는 별다른 이야기가 없다.
1. saved-model ➡️ onnx
https://github.com/onnx/tensorflow-onnx
python -m tf2onnx.convert --saved-model model/effdet_512x512/saved_model/ --output effdet_origin.onnx --opset 11onnxruntime을 이용해 테스트하여 inference 작동 확인
2. onnx ➡️ tensorRT
nvidia에서 tensorRT를 받아 sample/python에 포함된 코드들을 참고해도 좋지만
잘 정리해주신 분이 계신니 참고하여 코드 작성.
https://blog.si-analytics.ai/33
import tensorrt as trt
# TRT 7.x
print('convert onnx to trt')
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt.init_libnvinfer_plugins(TRT_LOGGER, '')
EXPLICIT_BATCH = 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(TRT_LOGGER) as builder, \
builder.create_network(EXPLICIT_BATCH) as network, \
trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = (1 << 30)
builder.fp16_mode = True
with open('./effdet_origin.onnx', 'rb') as model:
if not parser.parse(model.read()):
for error in range(parser.num_errors):
print (parser.get_error(error))
engine = builder.build_cuda_engine(network)
buf = engine.serialize()
with open('./effdet_origin.trt', 'wb') as f:
f.write(buf)3. onnx 수정
사실 한방에 변환되지 않는다.
tensorRT에서 지원하지 않는 연산, 구조를 수정해야한다. 아래 참고
- onnx-graphsurgen: https://github.com/NVIDIA/TensorRT/tree/master/tools/onnx-graphsurgeon
- onnx operator: https://github.com/onnx/onnx/blob/master/docs/Operators.md
- netron: https://github.com/lutzroeder/netron
netron을 통해 그래프를 시각화하여 어디를 어떻게 고쳐야할지 찾아야한다.
3-1. error
❗️Unsupported ONNX data type: UINT8
- 보통 tf od api에서 모델을 생성할때 입력 타입의 디폴트가 uint8인데 tensorRT에서 지원하지 않음.
- float32로 변경한다.
❗️Resize node - transformationMode 변경
- 전처리 노드에 포함된 resize에 지원하지 않는 모드가 기본값. 전처리 노드를 없애버리니 생략한다.
❗️[TensorRT] ERROR: INVALID_ARGUMENT: getPluginCreator could not find plugin NonMaxSuppression version 1
- tensorRT에서 onnx의 nms를 지원하지 않는다.
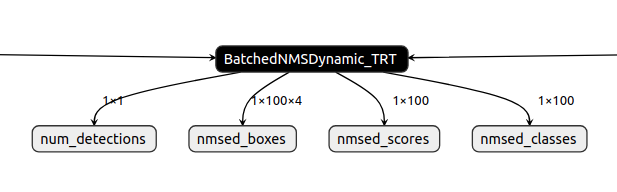
- tensorrt에서 지원하는 BatchedNMS_TRT / BatchedNMSDynamic_TRT 로 nms 노드를 교체해야한다.
- 먼저 tf od api에서 nms를 어떻게 처리하는지 확인해보자
- https://github.com/tensorflow/models/blob/2de518be2d6a6e3670b223a4582b1353538d3489/research/object_detection/core/post_processing.py#L1070
- box prediction과 각 class score로 nms를 수행한 후, 전체 nms 결과를 모아 스코어 순으로 내림차순 정렬한 후 상위 max_total_size 만큼을 취한다. netron으로 그래프를 시각화한 후 nms 부분을 보면 실제로 클래스 수만큼의 nms노드가 존재함을 확인할 수 있다.
.png)
- tensorRT의 BatchedNMS_TRT도 동일하게 작동한다.
- input:
- boxes: (batch_size, num_boxes, 1, 4)
- scores: (batch_size, num_boxes, num_classes)
- input:
- 위의 그림의 모든 노드 역할을 BatchedNMS_TRT로 치환해야하므로 그래프의 raw_detection_boxes와 raw_detection_scores를 알맞게 shape를 수정한 후 BatchedNMS_TRT로 연결해준다.
❗️[TensorRT] ERROR: Network has dynamic or shape inputs, but no optimization profile has been defined.
- dynamic shape를 사용하려면 별도의 설정이 필요한 듯.
- 난 batch_size가 1 이므로 shape를 지정했다.
❗️[TensorRT] ERROR: ../builder/myelin/codeGenerator.cpp (114) - Myelin Error in addNodeToMyelinGraph: 0 (map/while/TensorArrayV2Read/TensorListGetItem operation not supported within a loop body.)
- loop 안에 Gather 노드가 허용되지 않는다.
- 전처리 노드를 다 날려버리고 onnx로 전처리 과정을 추가하여 붙여주었다.
- efficientDet 전처리: https://github.com/tensorflow/models/blob/2de518be2d6a6e3670b223a4582b1353538d3489/research/object_detection/models/ssd_efficientnet_bifpn_feature_extractor.py#L190
- 수정 후
.png)
3-2. onnx 수정
import onnx
import onnx_graphsurgeon as gs
import numpy as np
graph = gs.import_onnx(onnx.load('effdet_origin.onnx'))
nodes = graph.nodes
tensors = graph.tensors()
# set input_tensor shape & dtype
input_tensor = tensors['input_tensor']
input_tensor.dtype = np.float32
input_tensor.shape = [1, 512, 512, 3]
# # resize mode
# # 전처리 Loop 노드 내부에 서브 그래프가 존재함. - node.attrs['body']로 접근
# preprocessing_node = nodes[2]
# resize_node = [node for node in preprocessing_node.attrs['body'].nodes if node.op == 'Resize'][0]
# resize_node.attrs['coordinate_transformation_mode'] = 'half_pixel'
# replace preprocessing node
# efficientNet 전처리 과정 구현
scale = gs.Constant(name='scale', values=np.array([1./255.], np.float32).reshape(1,))
input_scaled = gs.Variable(name='input_scaled', dtype=np.float32)
node_scale = gs.Node(op='Mul', inputs=[input_tensor, scale], outputs=[input_scaled])
nodes.append(node_scale)
ch_offset = gs.Constant(name='ch_offset', values=np.array([0.485, 0.456, 0.406], np.float32).reshape(1, 1, 3))
input_ch_shifted = gs.Variable(name='input_ch_shifted', dtype=np.float32)
node_ch_shift = gs.Node(op='Sub', inputs=[input_scaled, ch_offset], outputs=[input_ch_shifted])
nodes.append(node_ch_shift)
ch_scale = gs.Constant(name='ch_scale', values=(1./np.array([0.229, 0.224, 0.225], np.float32)).reshape(1, 1, 3))
input_ch_scaled = gs.Variable(name='input_ch_scaled', dtype=np.float32)
node_ch_scale = gs.Node(op='Mul', inputs=[input_ch_shifted, ch_scale], outputs=[input_ch_scaled])
nodes.append(node_ch_scale)
# onnx의 Conv 노드의 입력은 NCHW 포맷이므로 이미지를 transpose한다.
input_transposed = gs.Variable(name='input_transposed', dtype=np.float32)
node_transpose = gs.Node(
op='Transpose',
attrs={'perm': [0, 3, 1, 2]},
inputs=[input_ch_scaled],
outputs=[input_transposed],
)
nodes.append(node_transpose)
# Conv 노드의 입력 중 Loop 노드로부터의 입력을 새로운 전처리 노드의 출력으로 대체한다.
conv_node = [n for n in nodes if n.name == 'StatefulPartitionedCall/EfficientDet-D0/model/stem_conv2d/Conv2D'][0]
conv_node.i(0).outputs.clear()
conv_node.inputs[0] = input_transposed
# raw_detection_boxes에 차원 추가
raw_detection_boxes = tensors['raw_detection_boxes']
raw_detection_scores = tensors['raw_detection_scores']
raw_detection_boxes_unsqueezed = gs.Variable('raw_detection_boxes_unsqueezed', dtype=np.float32)
unsqueeze_node = gs.Node(
op='Unsqueeze',
name='unsqueeze_raw_detection_boxes',
attrs={
'axes': [2]
},
inputs=[raw_detection_boxes],
outputs=[raw_detection_boxes_unsqueezed],
)
graph.nodes.append(unsqueeze_node)
# nms 노드 추가
num_detections = gs.Variable('num_detections', dtype=np.int32, shape=(1, 1))
nmsed_boxes = gs.Variable('nmsed_boxes', dtype=np.float32, shape=(1, 100, 4))
nmsed_scores = gs.Variable('nmsed_scores', dtype=np.float32, shape=(1, 100))
nmsed_classes = gs.Variable('nmsed_classes', dtype=np.float32, shape=(1, 100))
nms_node = gs.Node(
op='BatchedNMS_TRT',
name='nms',
attrs={
"shareLocation": True, # 같은 박스로 모든 클래스에 대해 nms를 수행
"numClasses": 6,
"backgroundLabelId": -1, # 백그라운드 인덱스. 없는 경우 -1로 설정
"topK": 4096, # 스코어 순으로 박스를 정렬하여 상위 4096개만 연산
"keepTopK": 100, # nms 결과 중 스코어순으로 100개만 취함
"scoreThreshold": 1e-8,
"iouThreshold": 0.5,
"isNormalized": True, # 박스가 0~1 범위인 경우 True, 픽셀값이면 False
"clipBoxes": True, # 박스를 0~1 범위로 clip
"scoreBits": 10, # 스코어 비트 수. 높으면 nms 성능이 높은 대신 느려진다.
},
inputs=[raw_detection_boxes_unsqueezed, raw_detection_scores],
outputs=[num_detections, nmsed_boxes, nmsed_scores, nmsed_classes],
)
graph.nodes.append(nms_node)
# 그래프의 아웃풋을 새로 정의
graph.outputs = [num_detections, nmsed_boxes, nmsed_scores, nmsed_classes]
# clearup: 아웃풋에 관여하지 않는 노드를 제거한다.
# toposort: 그래프의 노드들을 순서에 맞게 자동 정렬한다.
graph.cleanup().toposort()
onnx.save_model(gs.export_onnx(graph), 'effdet_modify.onnx')위의 코드로 수정한 onnx는 tensorRT로 변환이 되었다. 변환 성공!
