머신러닝 공부 - 머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로
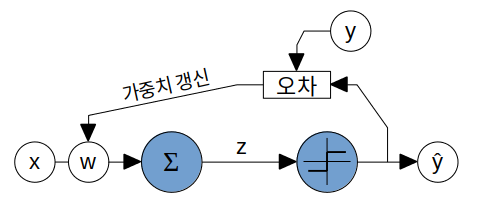
퍼셉트론 perceptron, 인공 뉴런 artificial neuron
- 이진 분류기: +1과 -1 분류
- 입력 x와 가중치 w의 내적값에 절편 w0를 더한 값이 0보다 크거나 같으면 +1, 작으면 -1 출력
x=⎣⎢⎢⎡x1⋮xm⎦⎥⎥⎤,w=⎣⎢⎢⎡w1⋮wm⎦⎥⎥⎤
z=w⊤x
Φ(z)={+1,z≥θ−1,otherwise
여기서 임계값 θ를 좌항으로 넘겨 w0=−θ 절편 정의
x0=1과 w0를 각각 x와 w에 추가하여 표기 간략화
z=w⊤x=w0+w1x1+⋯+wmxm
Φ(z)={+1,z≥0−1,otherwise
- 데이터가 선형 분리 가능해야 잘 작동한다.
퍼셉트론의 학습
- 가중치 초기화
- 훈련 샘플 x(i)마다 출력 y^ 계산, 가중치 w 업데이트
- 가중치 업데이트
w=w+Δw
Δw=η(y(i)−y^(i))x(i)
- Δw: 현재 가중치 w를 변화시킬 방향과 크기
- η 학습률: 가중치 변화의 크기를 조절하는 하이퍼파라미터
- (y−y^)x:
- 괄호 안의 경우 이진 분류결과가 맞다면 0, 틀리다면 레이블에 따라서 +2, -2 값이 된다.
- 예를 들어 -1이 target값인데 퍼셉트론이 +1로 예측한 경우, w,x의 wj,xj에 대해서
- z의 값을 감소시켜야하므로 wjxj의 값을 작게 만들어야한다.
- (y−y^)xj=−2xj
- xj가 음수인 경우 Δwj>0이므로 wj는 증가하게되고 그 결과 wjxj는 작아지게된다.
xj가 양수인 경우 Δwj<0이므로 wj는 감소하게되고 wjxj는 마찬가지로 작아지게된다.
- x: 가중치의 변화 방향과 크기에 관여. (퍼셉트론의 예측이 틀린 경우 큰 입력값이 z값에 크게 영향을 주기때문에 가중치도 입력값의 크기에 맞춰 조절하기위해 단순히 부호를 사용하지 않고 x를 쓴건가?)
- w를 0으로 초기화하는 경우?
- w=w+Δw=Δw=η(y(i)−y^(i))x(i)=η(y(i)−Φ(z))x(i)=η(y(i)−Φ(0))x(i)=η(y(i)−1)x(i)
- 가중치 업데이트 후 w는 0 또는 −2ηx(i)가 되며 x(i)에 의해서 크기, 방향이 결정되고 학습률η는 오직 크기에만 영향을 주게된다.
- ❓: y=−1인 샘플을 통해서 가중치가 업데이트되면 w=−2ηx 가 되니 그 다음 스텝부터는 상관없지 않나? 일단 붓꽃 데이터에 대해서는 잘 작동한다.
다중클래스 분류
- 일대다 one-versus-all: 클래스가 여러개인 경우 하나의 클래스를 +1, 나머지를 -1로 취급하여 각 클래스마다 하나의 퍼셉트론을 학습시킨다. 새로운 샘플 예측시에는 전체 퍼셉트론을 사용하여 z값이 가장 큰 분류기의 결과를 선택한다.
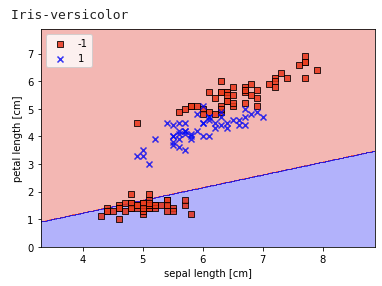
- 붓꽃 데이터는 선형 분리가 불가능해 다중 클래스 분류가 어렵다.
- 임의로 생성한 데이터
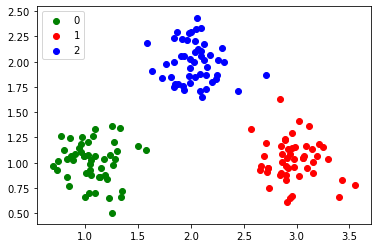
- 클래스별로 퍼셉트론 학습
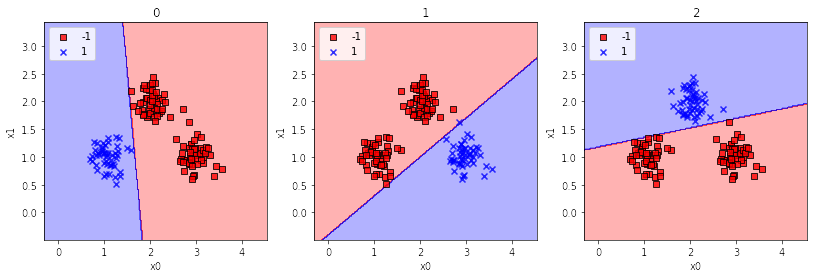
- 각 샘플마다 모든 퍼셉트론 중 가장 큰 z값을 내놓는 클래스를 선택한다.
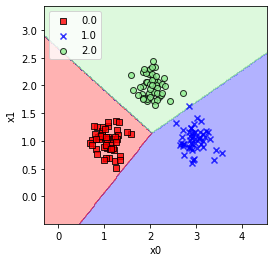
연습: https://github.com/canlion/ml_study - perceptron