[Observability] Observability best practices at Amazon re:Invent 후기 3 - metrics, trace, logging Best Practice
Finding the root cause
앞서 2부의 내용에서 다룬 대시보드를 통해, 문제가 어떤 영역에서 발생하였는 지를 식별하게 되면, 이제 root cause를 찾기 위해 metrics를 Drill down하는 과정을 거친다.
metrics를 통해 세부적으로 분석하는 방법은 dimension 개념을 활용한다. 이에 앞서 용어를 짚고 넘어가자.
1. Observability 용어 정리
1. Metric이란?
수치화된 측정값이에요.
시스템에서 수집되는 성능 데이터의 값 자체입니다.
✅ 예:
• CPU 사용률: cpu_usage = 42.5
• HTTP 요청 수: http_requests_total = 1000
• 응답 시간: response_latency = 0.45
→ 시간(Time Series)과 함께 수집되며, 변화 추이를 관찰하기 위해 사용돼요.
2. Dimension (또는 Label)이란?
Metric에 속성을 부여하는 추가 정보(태그)를 뜻한다.
Metric을 구분하고 필터링할 수 있게 해준다.
Metric: http_requests_total
Dimension (Label):
- method="GET"
- status="200"
- service="auth"→ “auth 서비스에서 GET 요청 중 200 OK만 필터링” 같은 조건부 분석이 가능해짐.
즉, Cloudwatch log에서 추가적으로 표시할 수 있는 라벨로 볼 수 있다.
3. High Cardinality란?
Dimension 값이 너무 다양해서 조합 수가 많아지는 것을 뜻한다.
Dimension: user_id
- user_id = 100000개 → 매우 높은 cardinality→ 100개의 metric x 100,000명의 사용자 = 10,000,000개의 시계열 발생 가능 😱
효율적인 로그 조회(쿼리)를 위해 다음과 같은 규칙을 지키는 것이 좋다

2. Cloudwatch Logging Best Practice
어떻게 지표가 작동하고 어떻게 나타나는 지를 이해하기 위해 지표가 어디에서 나오는 지 Application 소스코드와 시스템의 mertrics에서 나오는 지에 대해 알아보자.

이는 Cloudwatch에 내장된 metrics format으로, 이처럼 구조화되어 로그 파일에 보관된다(이 로그 파일을 다양한 Format으로 custom 하는 방법은 많이 있다)

instrumentation이 한 곳에 모여있는 구조로 되어있다. 이를 통해 request 당시 무슨 일이 있었고, 무슨 내용이고, 우리가 무엇을 했는 지에 대한 사실을 알 수 있다.

그리고 여기에는 각 로그 레코드가 있는데, 이는 시스템에 사실을 어떻게 변환해야 하는 지, 어떤 사실로 변환해야하는 지, 어떤 방식으로 분류해야 하는 지를 알려줍니다.
다음으로 Application 소스코드에서 로그를 남기는 부분을 찾아보자.

다음 서비스를 가정해봅시다.
전자상거래 사이트를 위한 제품 정보 서비스. 제품을 가져오는 등 다양한 api를 제공하며 이는 사이트에 표시하기 위해 특정 제품에 대한 정보만 반환합니다.
이 코드는 이 서비스에서 무슨 일이 일어나고 있는 지 전혀 알 수 없다. 왜냐하면 요청이 실패하는 이유나, 속도가 느린 이유를 해결하려고 할 때, 그 요청이 무엇을 하려고 했는지, 누구를 위한 요청인지 전혀 알 수 없기 때문이다.

이 요청이 캐시에 저장됐나요? 캐시에서 유용한 정보를 얻었나요
아니면 데이터베이스로 다시 돌아가야 했나요?
그리고 이 두가지 중에 하나라도 실패했다면 그 이유는 무엇인가요?
Time out이 발생했나요?
디버깅 및 영향 완화를 시도할 때 발생하는 오류와는 시간 초과가 매우 다릅니다.
데이터베이스 쿼리를 실행하는 데 시간이 오래 걸렸나요?
뭔가 반환이 있었나요?
Best Practice는 다음과 같다

실제로 코드에 많은 것을 추가하지는 않지만, 정말 중요한 내용을 추가한다. (아마존은 회사 전체에서 공통적인 metrics library를 사용한다고 한다)


이 API Request가 어디서 동작하고 있는 지, 어떤 정보를 담고 있는 지 log에서 볼 수 있도록 Facts(dimension)를 추가한다.
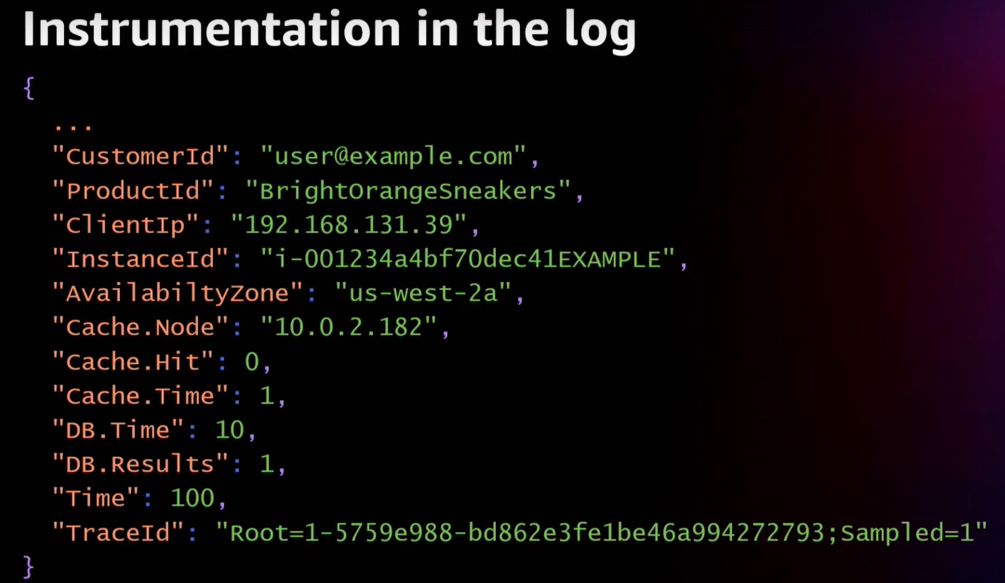
이로 인해 실제 로그는 다음과 같이 남게 된다.
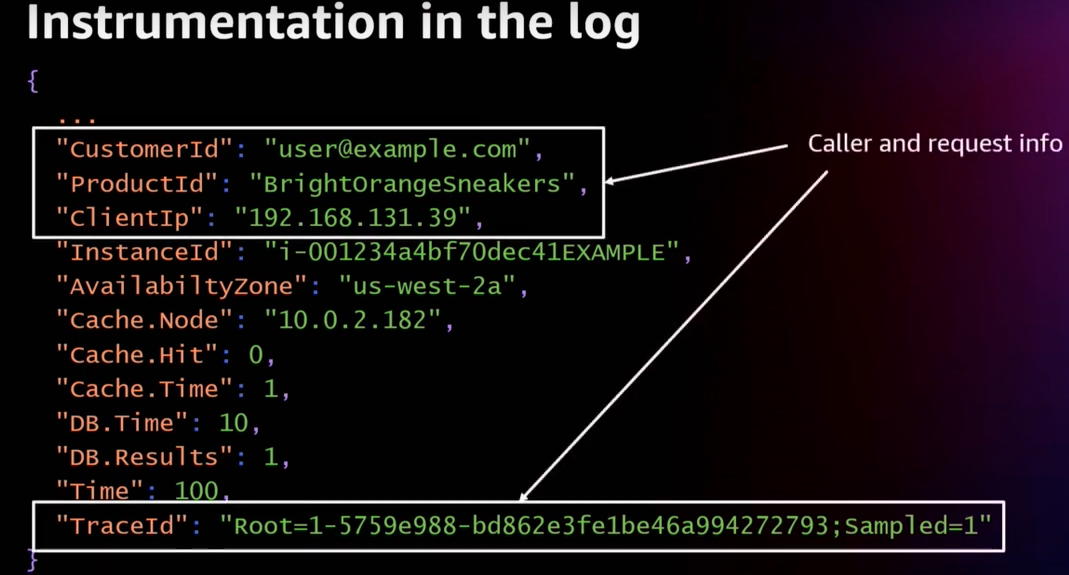
우리에게 이런 요청을 한 사람이 누구였을까요? -> CustomerId
그들은 어디서 왔을까? -> ClientIP
요청을 처리한 인프라에 대한 정보가 있습니다. -> InstanceId
그리고 요청을 추적할 수 있는 정보 -> TraceId
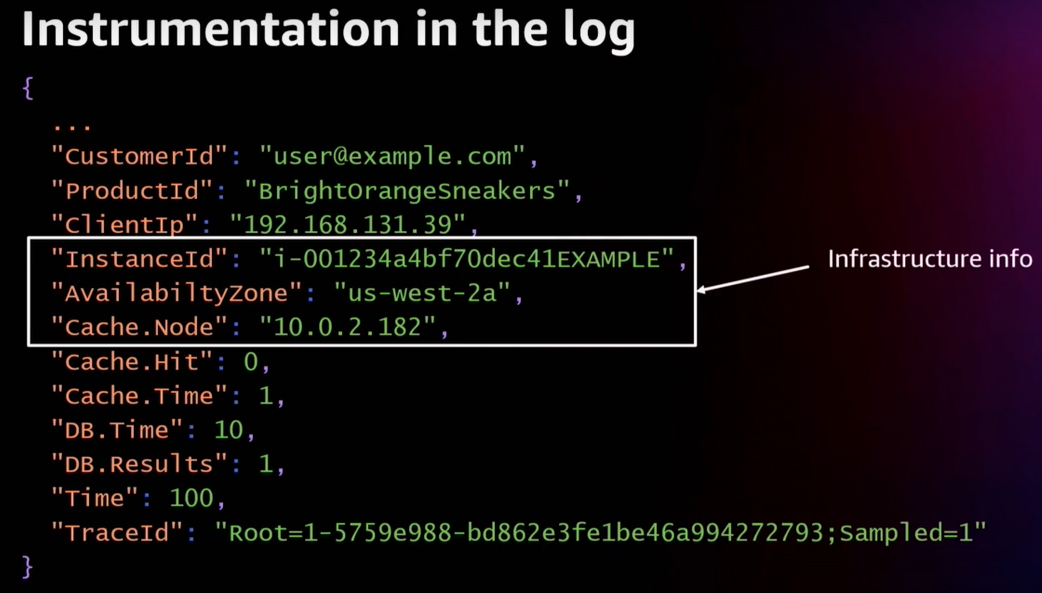
다음은 infra resource 정보이다. 어느 AZ의 EC2인지 바로 식별이 가능하다. 또한 어떤 캐시 노드를 호출하는 지 알 수 있다.

그리고 작업이 얼마나 걸렸는 지, 얼마나 많은 작업이 처리되었는지 등과 같은 타이밍과 기타 측정 항목이 많이 있습니다.

더 상세하게 살펴보면, 이벤트가 발생하였는 지를 알 수 있는Facts(=Dimension)과 숫자로 표현되는 정보가 있으며,

문자열로 표시되는 속성(attribute) 정보들로 나뉜다.

그리고 다시 log Format으로 돌아가면, Metrics Definition 안에 Namespace, Dimensions, Metrcis가 있으며 시간의 단위를 측정할 수 있다. (현재 Dimensions는 비어있음)

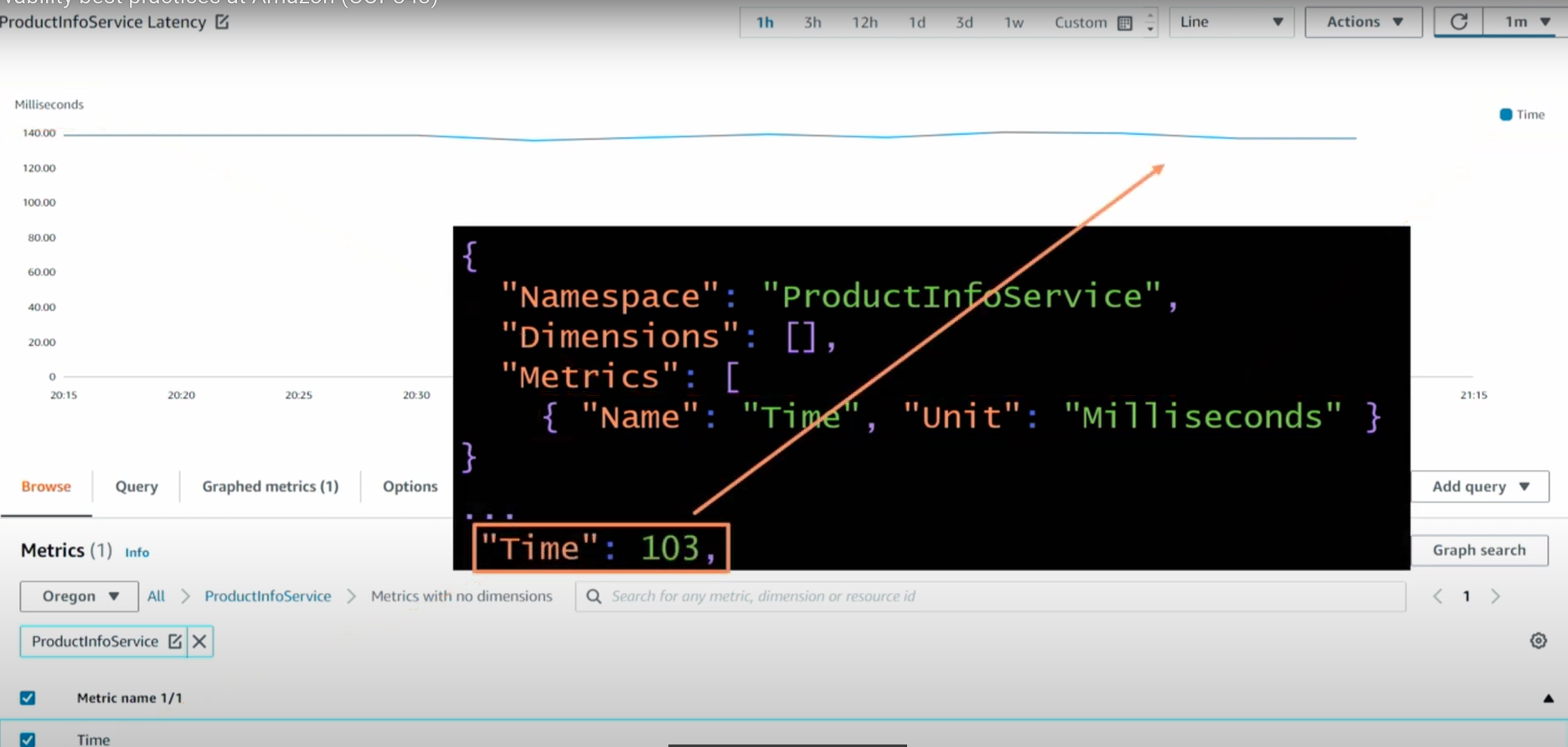
이 의미는 수행된 Time을 측정하여 metrics로 변환하는 내용이다.
그러면 어떤 결과가 나타날까?
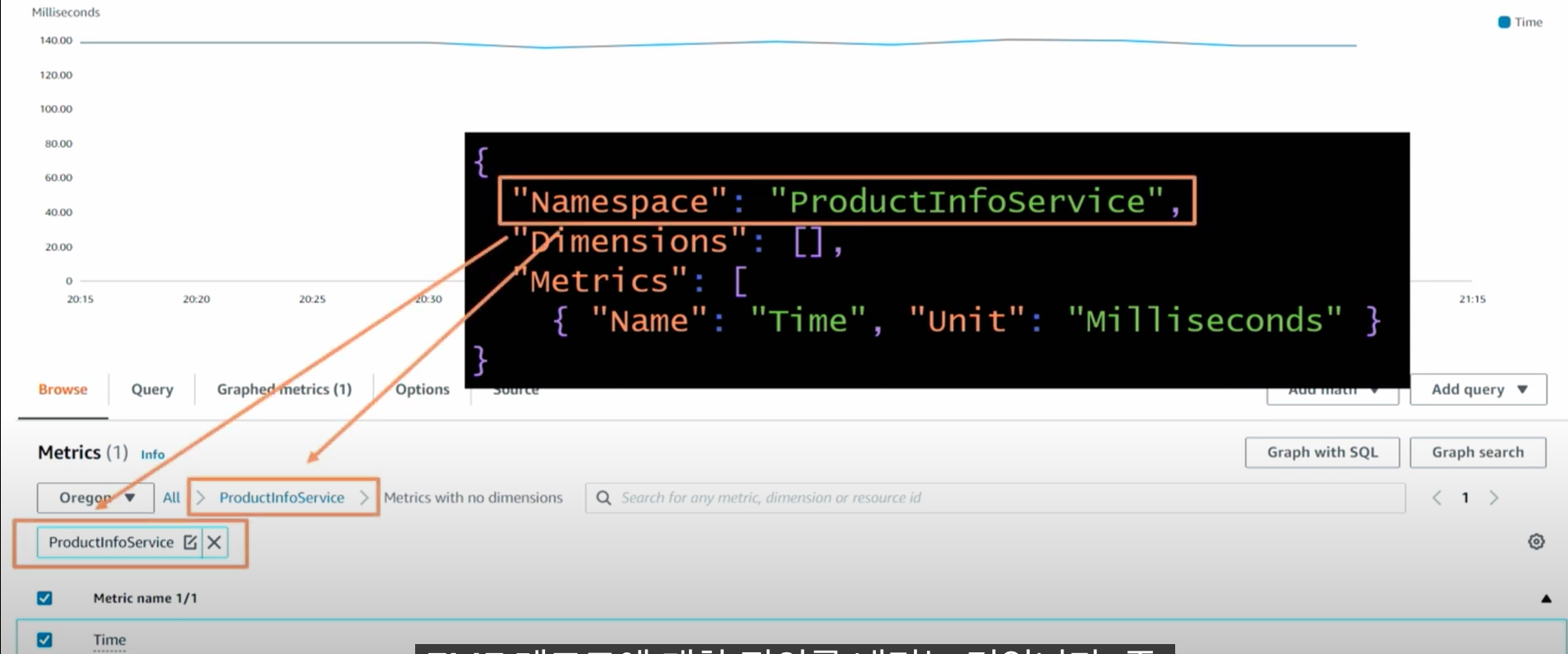
다음과 같이 Cloudwatch에서 해당 Metrics를 검색하여 조회할 수 있다. 위는 Namespace "ProductInfoService"를 조회한 모습이다.
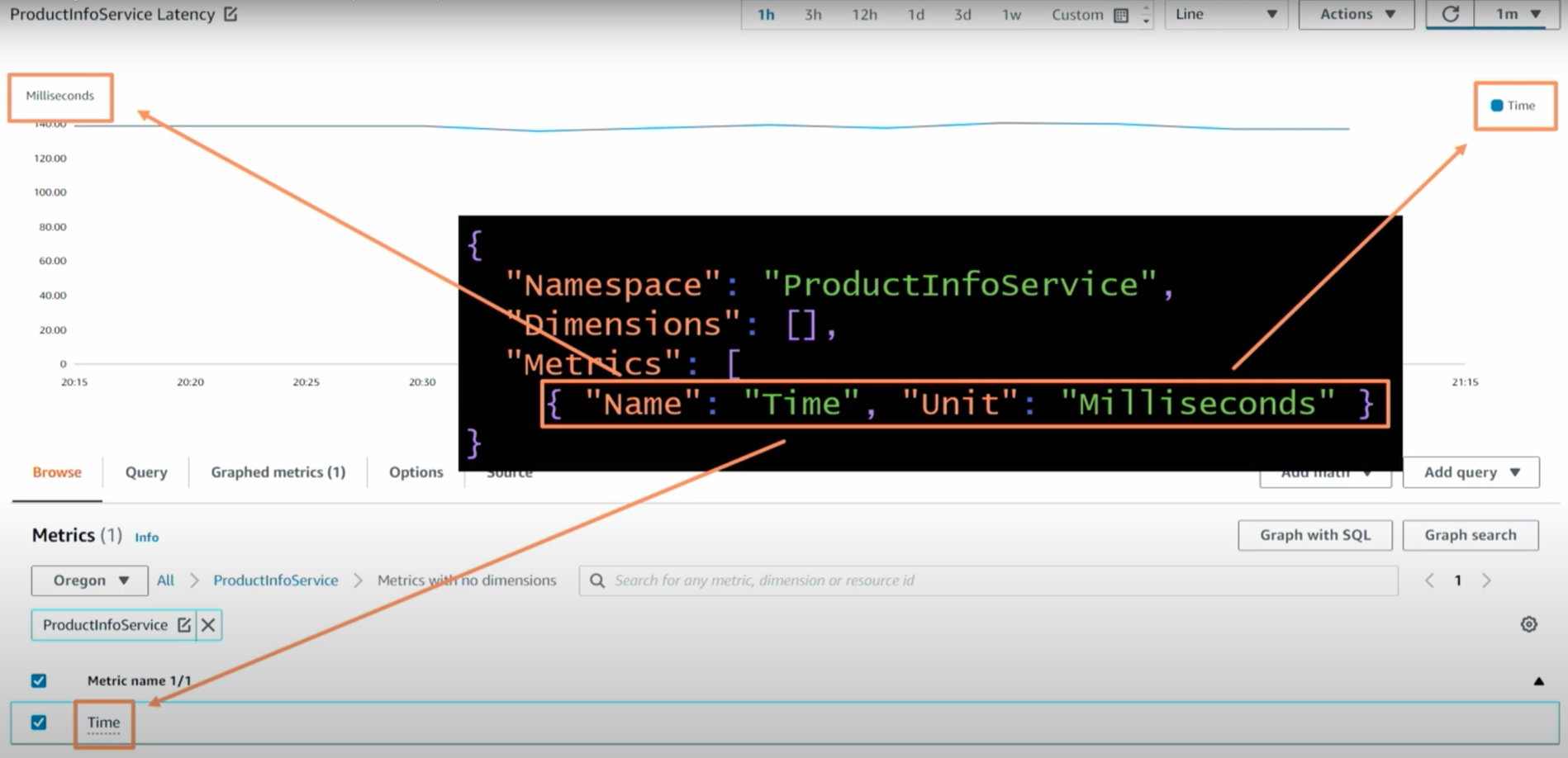
위는 Time 속성(Attribute)를 사용하는 모습이다. 지연 시간을 보기 위한 설정이다. milliseconds가 100 단위(Unit)로 표기되는 모습이다.
다음으로 drill down하였는데 dimension 정보가 빠져있다. log를 남길 때 표기하지 않았기 때문이다.
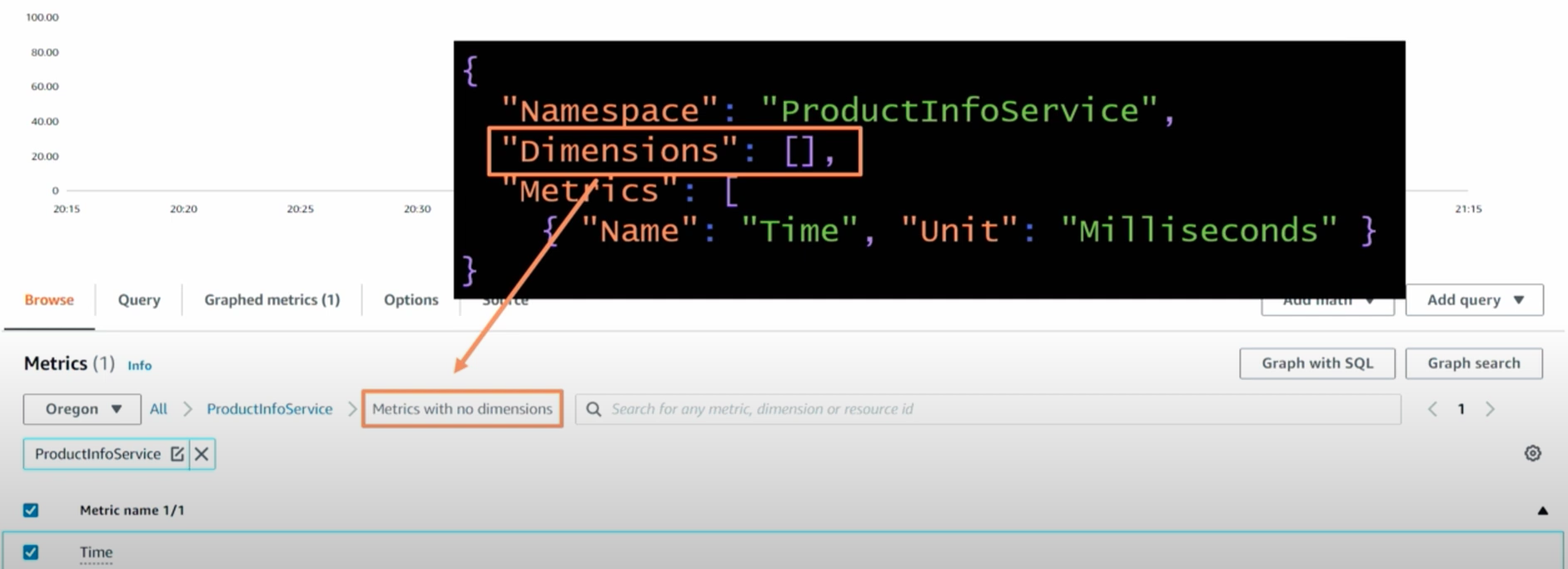
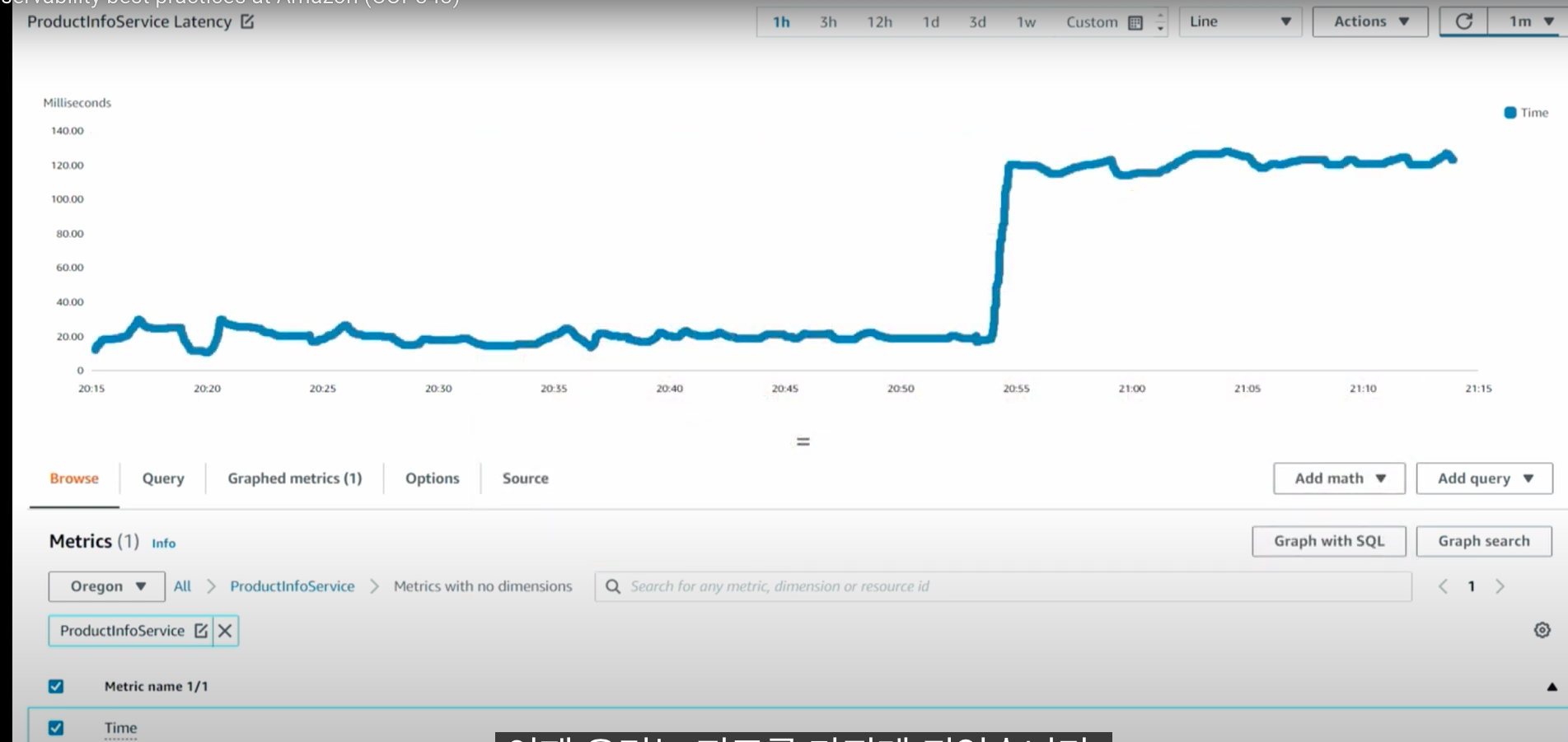
이 상태에서 그래프는 다음과 같이 표시된다. 여기서 얻은 지표를 통해서 latency가 지연되고 있음을 알 수 있다. 하지만 그 이유를 어떻게 알아낼 수 있을까? 이를 위해서는 아키텍처를 확인해봐야 한다.
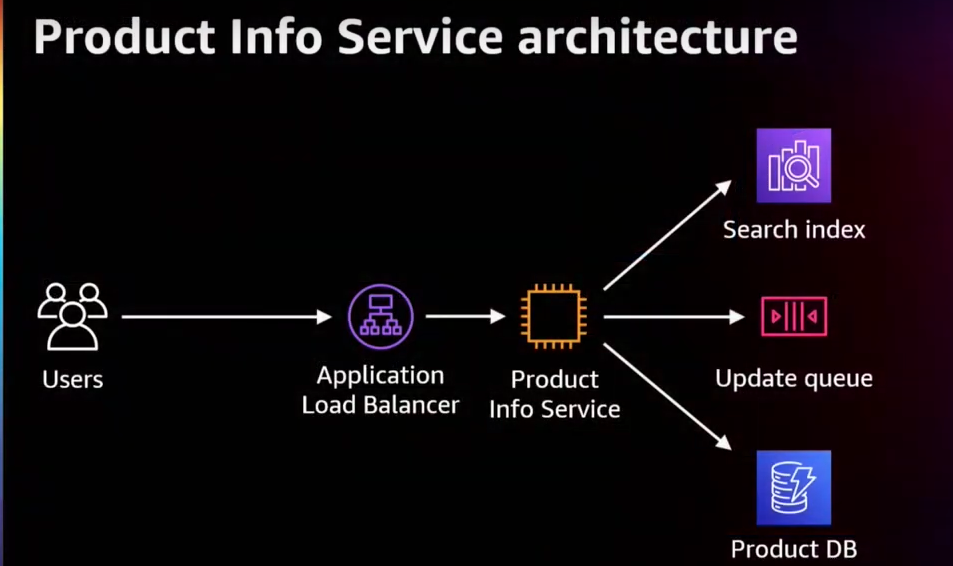
Dynamodb와 같이 데이터베이스에서 간단한 키 값을 조회하는 제품 가져오기와 같은 다양한 API가 있을 수 있습니다.
판매자가 등록한 상품에 대한 정보를 업데이트 할 수 있도록 상품 업데이트 API가 있을 수도 있습니다.
그리고 사람들이 사이트에서 사물에 대한 검색을 할 수 있는 검색 제품이 있을 겁니다.
그러면 보통 search index를 사용하고 다른 종속성은 사용하지 않을 수도 있습니다.
이러한 각 API에는 고유한 종속성 집합이 있을 수 있으며 잘못될 수 있는 사항도 있을 수 있습니다.
이 부분에서 Dimension이 유용하게 사용됩니다. Dimension을 사용하면 Latency 측정 항목을 더 세부적이고 인사이트 있게 표시할 수 있습니다.
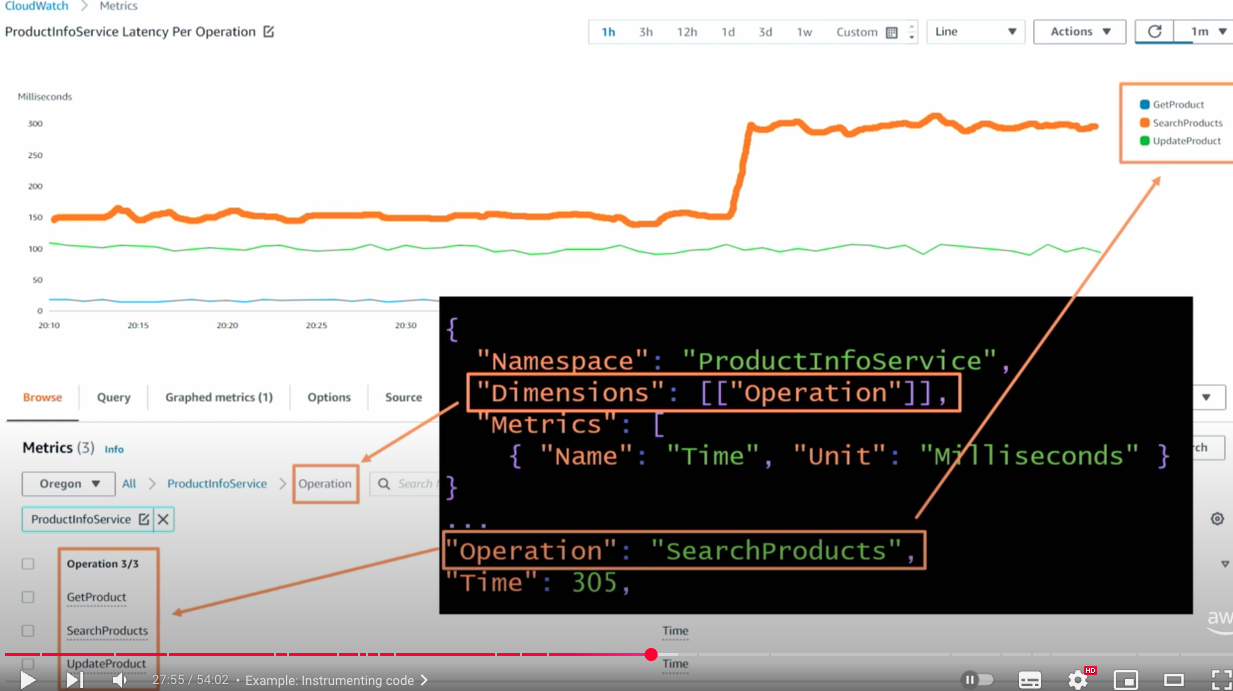
위는 Operation 이라는 Dimension을 통해 어떤 API 작업인지를 표시한 모습이다. Dimension 식별을 통해 Latency 지표 중에서 지연이 늘어난 대상이 SearchProducts API임을 식별할 수 있다.
따라서 좋은 Observability를 갖추기 위해서는 Application 소스코드에서 Dimension을 설정하는 규칙을 가져야 한다.
