제로베이스 데이터 취업 스쿨 5주차 스터디노트 4호

관점
Iris 프로젝트를 하면서 가장 핵심이 되는 것은 이 말인 듯 하다.
"눈으로 봐서가 아니라, 꽃잎 / 꽃받침의 길이로 품종을 구분할 수 있을까?"
이게 데이터 분석가가 가져야 할 메인 관점이다.
강의에서 계속 언급되고, 프리토크 세션에서도 교수님이 말씀하신 내용이다.
EDA 세션의 서울시 범죄율 확인에서도,
"강남 3구가 대체로 안전하다."라는 말에 대해서 의문을 갖는 것이다.
정말로 안전할까?
인터넷과 프로그래밍이 전문가의 소유물인 시절에는,
위의 명제를 증명하려면 우리는 구청 같은데 가서 인구수 자료 요청하고,
경찰서 가서 범죄율 자료 요청 등 할일이 무척 많았을 것이다.
그러나 오늘날에는 카페에 앉아서,
파이썬으로 selenium & beautifulSoup를 돌리고,
공공API 등을 요청해서 데이터를 쉽게 모을 수 있다.
지식을 배우는 것도 좋지만,
고수의 관점을 받아들이는 것이 진짜 중요하다.
관점은 세상을 바라보는 방식을 바꾸어, 행동의 동기를 제공하기 때문이다.
Decision Tree
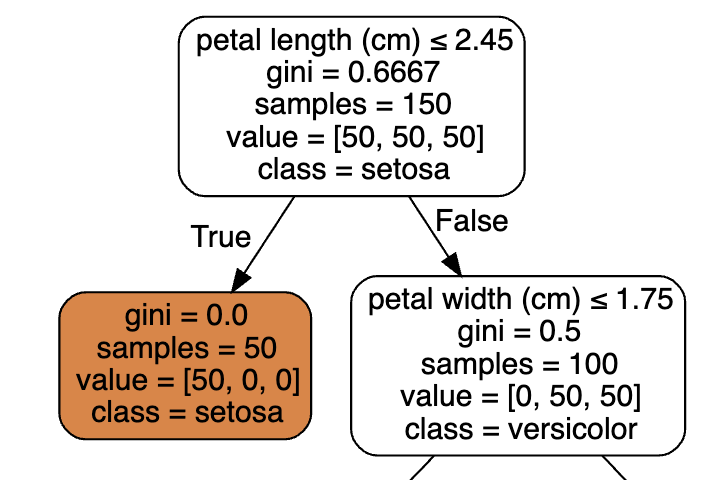
분류 문제에서, 데이터의 군집을 분류할 수 있는 기준을 반복적으로 제공하여 데이터의 군집을 분류하는 것이다.
Information Gain
Decision Tree에 있어,
Information Gain이란 split criterion을 제공함으로 인해
감소한 Information Entropy를 의미한다.
정보의 무질서도의 감소로 인해 얻은 이득을 의미한다.
깊게 들어가면 한도 끝도 없고...
(콜백-라이블러 발산이라는 개념이 있다고 한다)
여기선 이정도로 이해해야겠다.
Gini Impurity
Gini impurity measures how often a randomly chosen element of a set would be incorrectly labeled if it was labeled randomly and independently according to the distribution of labels in the set.
>>> wikipedia
예를 들어, 10개 공 중 8개가 파란 공이고 2개가 빨간 공이다. 눈을 가리고 공을 나열한 후, 색 비율을 알고 있는 상태에서 각 공의 색을 맞추는 것이다. 이 때, 틀릴 확률?을 지니계수라고 한다.
참고로, 경제학에도 지니계수가 있다. 그래서 그냥 지니계수라고 찾아보면 경제학의 지니계수만 줄줄히 나오니, "머신러닝 지니계수", 혹은 "Gini Impurity"라고 검색하자.
