도입
scaler는 서로 다른 scale의 feature을 비교가능하게끔 조정해준다.
조정한다는 것은, normalize, standardize 등의 단어를 고려해보았지만 내 지식으로는 아직 설명이 불가하였다.
현재까지 이해한 바,
scaler은 데이터의 범위를 조정하여 비교가능하게 해주는 것이고,
scaler 중 StandardScaler는 정규화(Standardize)를 한다.
정규화는 아무래도 정규분포와 연관짓는 듯하다.
반면, normalize는 뜻이 크게 달라진다.
데이터의 범위(range)를 조정하는 것이 아닌,
데이터의 분포(distribution)을 조정한다.
< 참고링크 >
Scikit-Learn의 전처리 기능
Scaling and Normalization
sklearn.preprocessing.StandardScaler
그려보기
# 모듈
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler, StandardScaler, Normalizer
# 랜덤 데이터 생성
size = 30
alfa = np.random.rand(size)
bravo = np.random.randint(-5, 5, size)
df = pd.DataFrame({ "A": alfa, "B": bravo })
sns.boxplot(df)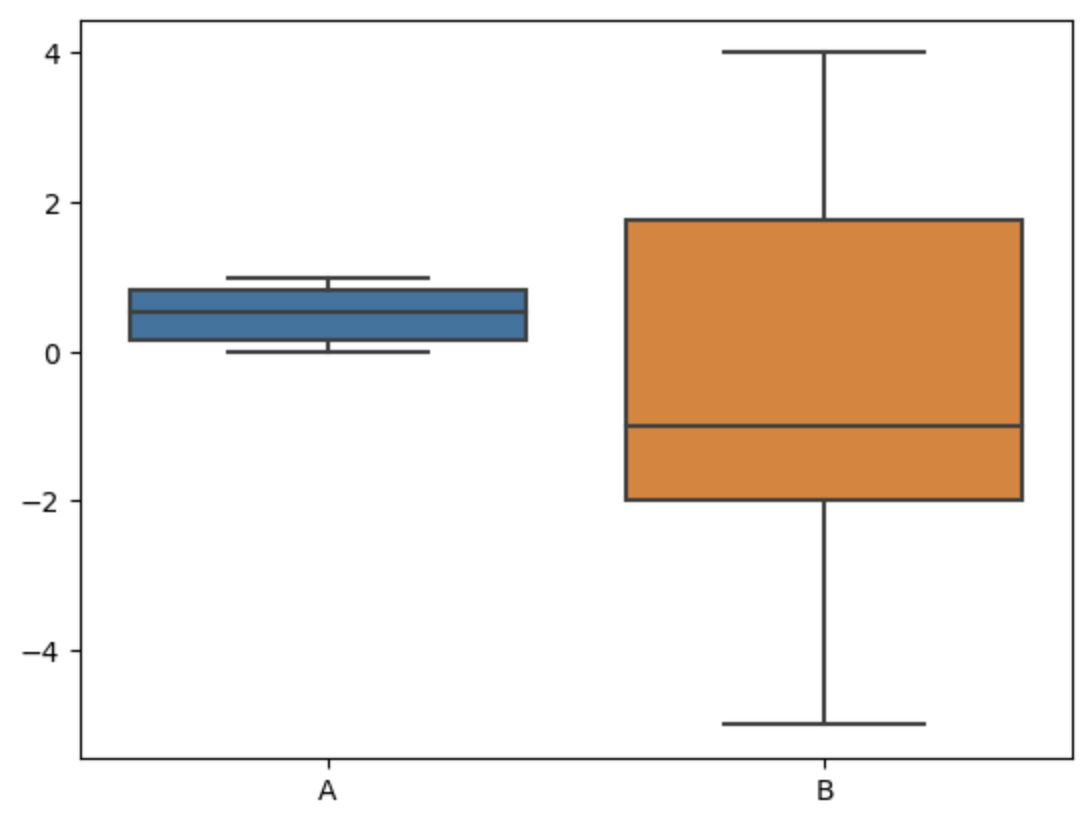
# plot MinMaxScaler
def scale_minmax(df):
scaled = MinMaxScaler().fit_transform(df)
sns.boxplot(scaled)
scale_minmax(df)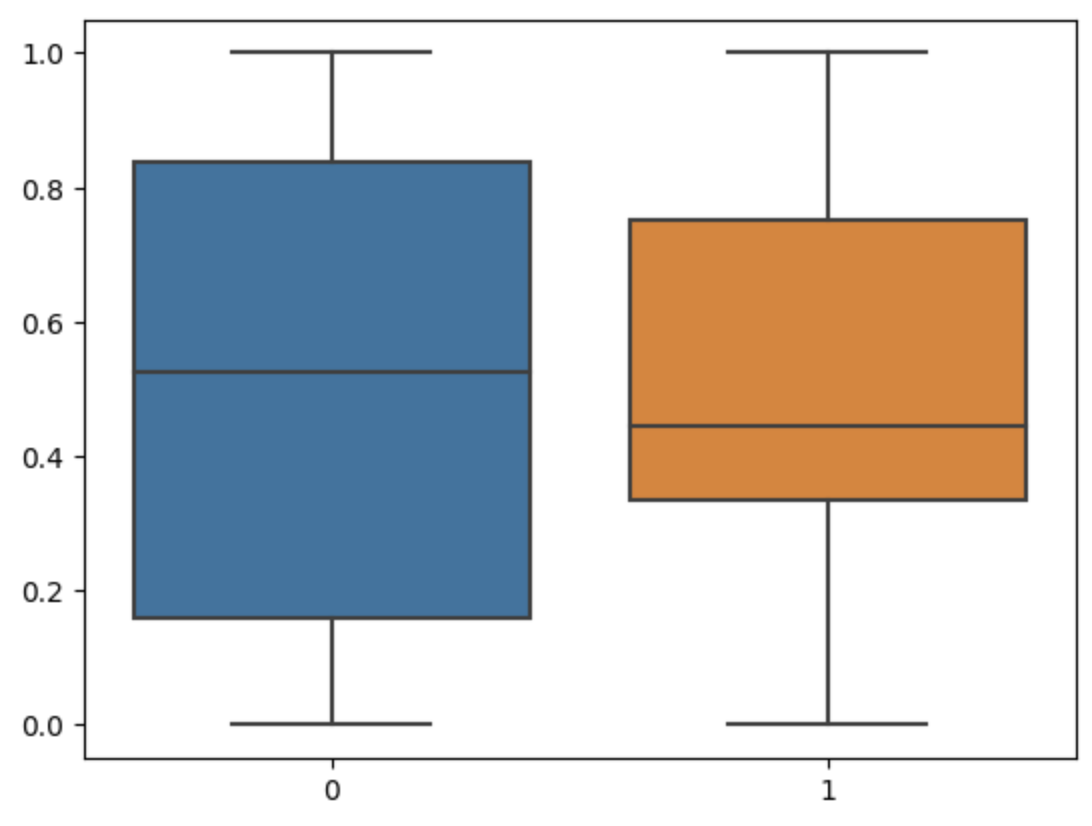
# plot StandardScaler
def scale_standard(df):
scaled = StandardScaler().fit_transform(df)
sns.boxplot(scaled)
scale_standard(df)
# Normalize
def normalize(df):
normalized = Normalizer().fit_transform(df)
sns.boxplot(normalized)
normalize(df)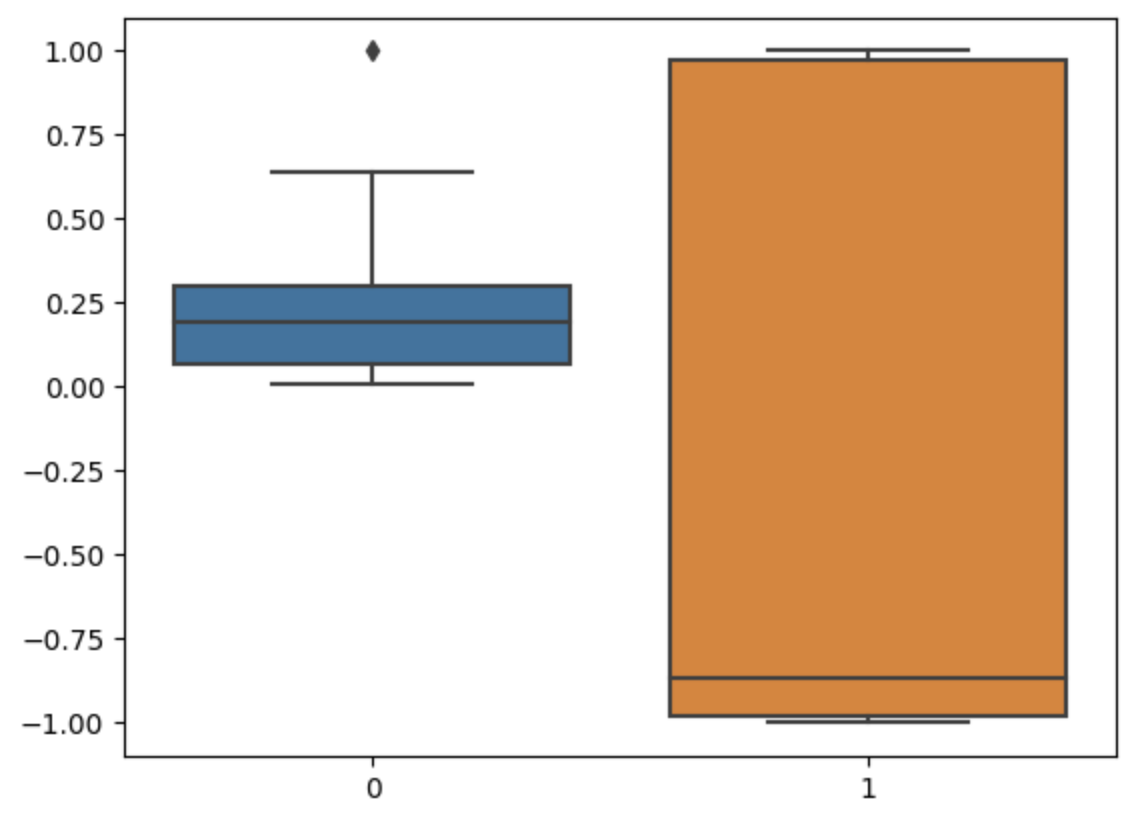
기타
참고로, 하나의 pandas series 대상으로 scikit-learn의 Scaler을 사용할 수 없다.
그럼 하나의 pandas series를 scaling 할 수는 없는 것인가? 그렇진 않으나,
하나의 series를 굳이 scaling 할 필요도 없긴 하다. (비교하려고 scaling을 하는 것이니)
다만, 정 필요하다면 numpy의 reshape(-1, 1)을 활용하자.
또한, 굳이 instantiation을 하지 않고 쓸 수 있는 scaler도 존재하나,
이 경우 Pipline을 활용할 수 없다.

Impact