"Transformer 논문 핵심 정리"
Introduction
-
sequence modeling, LM, NMT 문제를 해결하기 위해 RNN기술(GLU),encoder-decoder 구조로 향하고 있음. [38,24,15]
-
h(t-1)를 이용해서 h(t)를 생성하는 특성상 parallelization이 힘들고, longer sequence length 경우 memory constraints 제한. 다양한 방법시도하나 근본적인 구조적 문제 존재.
-
Transformer를 제안, recurrence를 피하고 attention mechanism만으로 input, output 사이의 global dependencies들을 끌어냄.
-
Parallelization, translation quality 측면에서 성능 향상을 이루었음.
3. Model Architecture
-
Attention mechanisms
-
대다수의 경쟁력 있는 sequence transduction model들의 경우 encoder-decoder 구조 취함. [5,2,35]
-
encoder : input sequence of symbol representations to
-
decoder : Given z, generates an output sequence
-
As each step, auto-regressive[10] next생성을 위해, 생성된 symbols과 additional input을 사용.
-
Transformer의 경우 encoder-decoder 각각 stacked된 self-attention과 point-wise fully connected layer들을 사용했다.
3. Model Architecture
- 3.1 Encoder-decoder stacks
Encoder
-
stack of N=6 identical layers(two sub-layer : multi-head, ffn으로 구성)
-
two-sub layer 간에 residual connection 적용, layer-normalization 적용(LayerNorm(x + Sublayer(x))) wrapping all in model
Decoder
-
stack of N=6 identical layers(three sub-layer : multi-head(2번째, encoder에서 넘어옴)ffn으로 구성)
-
sub-layer간에 residual connection 적용.(LayerNorm(x + Sublayer(x)))
-
decoder의 self-attention sub-layer에 masking 적용하여 position i가 i 미만의 position 결과들에만 의존하도록 함.*
3. Model Architecture
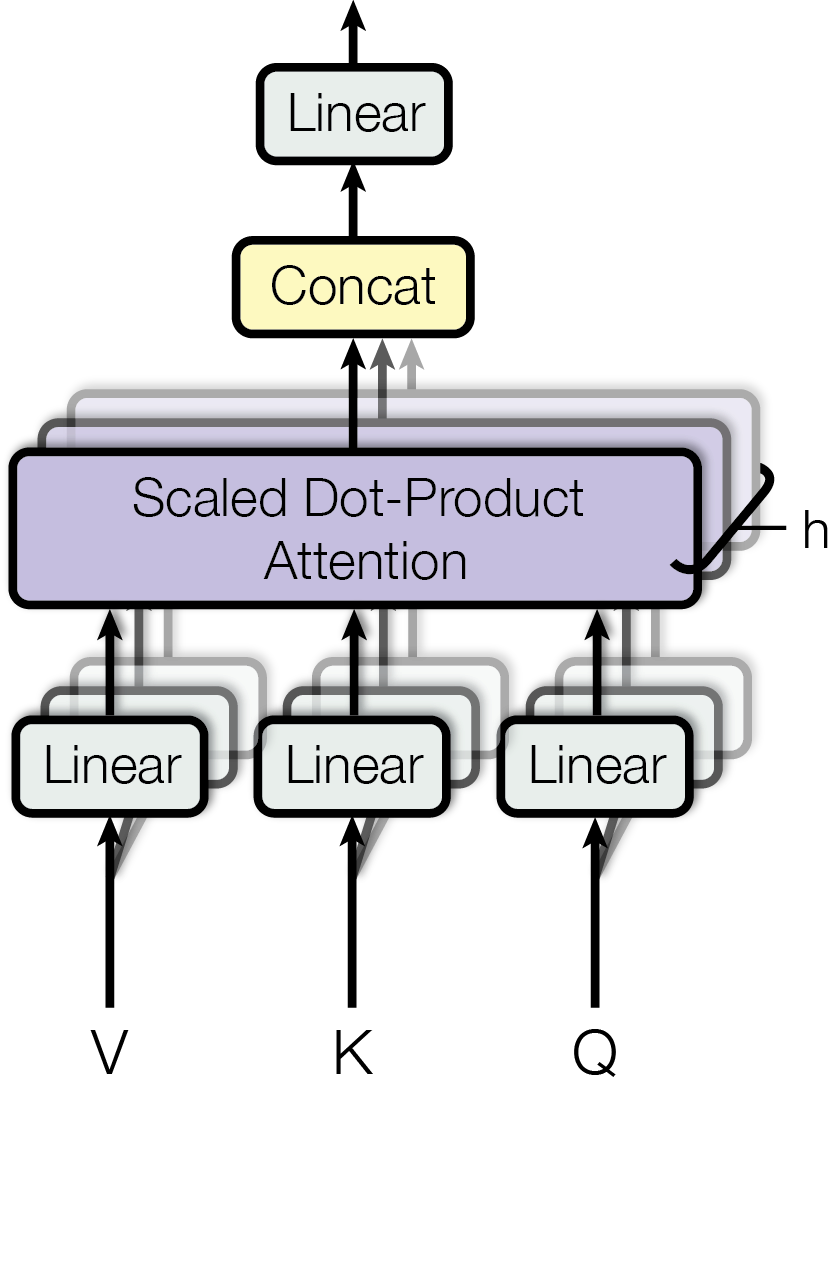
- 3.2 Attention / Scaled-dot product attention
-
Q,K,V는 다음을 의미한다.
-
여기서 는 입력 디멘션 크기로 스케일링을 역할을 한다고 볼 수 있다.
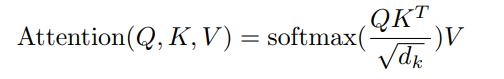
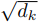
- Mapping a query and a set of key-value pairs to an output . output is computed as a weighted sum of the values( where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key. )
3. Model Architecture
3.2.1 Scaled Dot-Product & Multi-head attention
Multihead Attention
- 3.2.2 Multi-Head Attention
weighted sum 극복을 위한 convolution 방식(different linear transformation)의 multi-head attention
- single attention을 크기의 keys, values and queries에 적용하기 보다, 1) queries, keys and values 에 각각 linearly project 2) h times만큼
projected version의 queries, keys, values를 attention function => 크기의 output values concatenated 하고 한번 더 linear projected하여 final values를 만든다. - 모델에서는 로 조건을 주어 실험을 하였다.
*d(model) :embedding layer output of dimension.
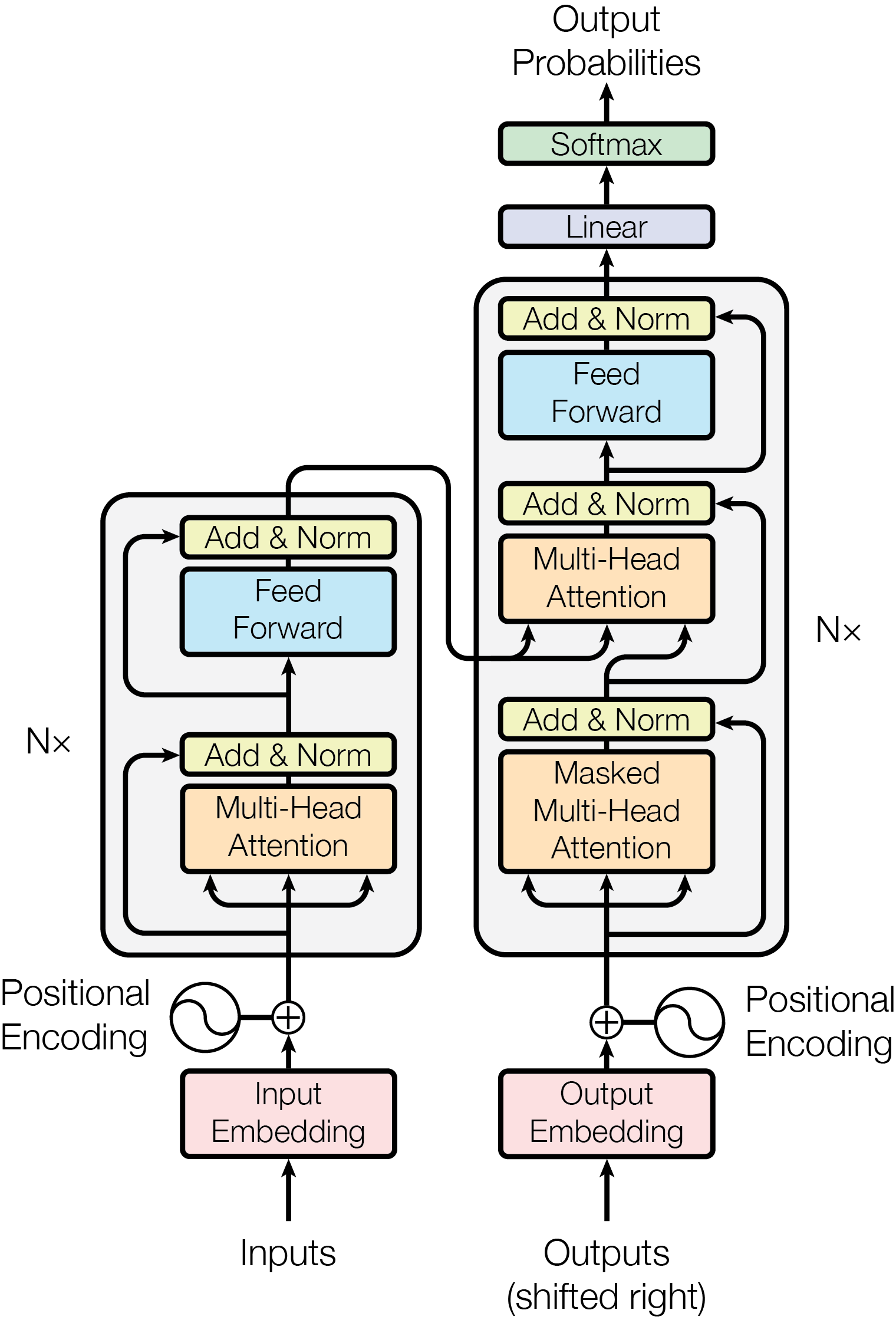
Transformer
- 개념적 분해 :Encoder- Decoder
- 구성요소별 분해 :
- Positional Encoding
- Sub-layer
- multi-head attention
- scaled dot-product attention
- position-wise FFN
- multi-head attention
- Residual connection
3. Model Architecture
Application of attention in our Model
-
Transformer의 경우 multi-head attention을 3가지 다른 방법으로 사용했다.
-
encoder-decoder attention layers : queries는 이전 decoder layer에서, memory keys와 values는 encoder outputs 에서 가져옴 (이를 통해 decoder는 position마다 input sequence 모든 position 정보를 반영).
-
encoder의 경우, self-attention layer를 통해, keys, values, queries를 encoder의 이전 레이어에서 받아서 사용(이를 통해서 encoder의 각 부분은 이전 레이어의 모든 position을 attention 함).
-
decoder의 경우, decoder input에 self-attention layers 통해, 모든 position 정보를 attend할 수 있게 함 (다만, AR 특성을 유지하기 위해 scaled-dot product attention 시, illegal connection에 대해선 -inf로 처리).
3. Model Architecture
3.3 Position-Wise Feed Forward Networks
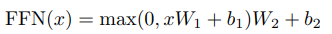
- encoder와 decoder에 있는 각 layer들은 fnn을 적용한다. each position에 개별적으로 또 동등하게 적용, 위의 식으로 적용된다. linear transformation을 다른 position마다 적용하고, layer마다는 다른 parameter 사용하였다.
3. Model Architecture
3.4 Embedding and Softmax
- 다른 sequence transduction model들과 비슷하게 input, output token들을 d(model)차원의 vector로 바꾸기 위해 학습된 embedding 가중치를 사용하였다.
- decoder 결과를 predicted next-token probabilities로 바꾸기위해, linear transformation, softmax function 사용하였다. 또한, 두 개의 embedding layer들 간에 same weight matrix 공유한다.
3. Model Architecture
3.5 Positional Encoding
- convolution 활용하거나 recurrent한 layer을 사용하지 않았기 때문에 position을 표현하기 위해서 embedding 을 변형 하였다.
- “positional encoding’을 input embedding(encoder, decoder bottom)에 더하였다.
- 다른 주기를 활용해서 sine, cosine function 사용하였다.
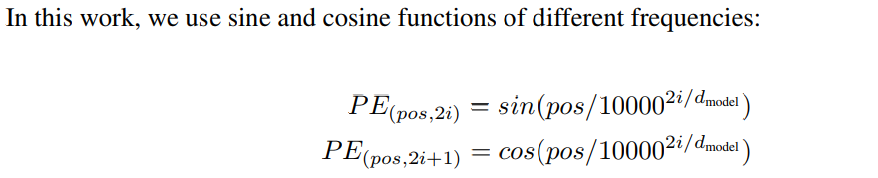
위 수식에서, d model : dimension of model, pos : position , i : dimension 을 나타낸다.
- 예시
I am going to go shopping.
0 1 2 3 4 5
*max_len = 5(no pad)
*d(model) = 100
*i= embedding
(0,2,4,8,..100)
4. Why Self Attention
- self attention, recurrent, convolution layer들 간을 비교한다.
- 또한, layer마다의 계산 복잡도, 계산량(최소 필요한 연속 개수),long-range dependencies 비교한다.

- Maximum path len : 두 position간의 의존성 학습을 위한 connection 개수로 볼 수 있다.
5. Training
- 학습에 사용하였다고 서술된 논문의 정보는 다음과 같다.
(EN-GE)4.5 million sentence pairs. byte-pair encoding.
shared vocabulary of about 37000 tokens
8 NVIDIA P100 GPUs, 100,000 steps (base model)
Adam optimizer with beta1=0.9, beta2 = 0.98, eps=10^-9
Residual dropout = 0.16. Results
6.1 Machine Translation
- (base model) 5 checkpoints 사용, beam-search 사용 (beam-size=4, length penalty=0.6)
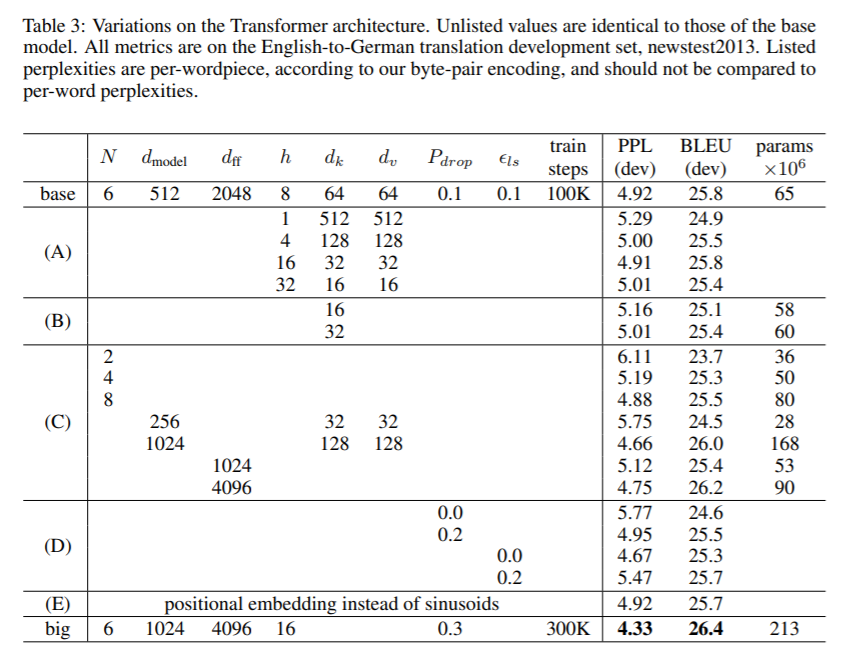
6.2 Model Variations
- number of attention heads 실험, attention key와 value dimension 크기를 바꿔서 실험하였고, single head attention 0.9 BLEU 하락하고, attention이 너무 많아도 BELU 하락하였다고 한다.
7. Conclusion
- sequence transduction model을 처음으로 recurrent layer를 attention으로 바꾼 모델에서 의의를 지닌다. 이를 통해, 번역 task에서 더 빨리 학습 가능하며 2014 WMT En-to-Ge SOTA 이외에 다른 task 및 데이터에도 attention-based model을 적용하는 확장 계획을 목적으로 Future work를 이야기하고 있다.
부록
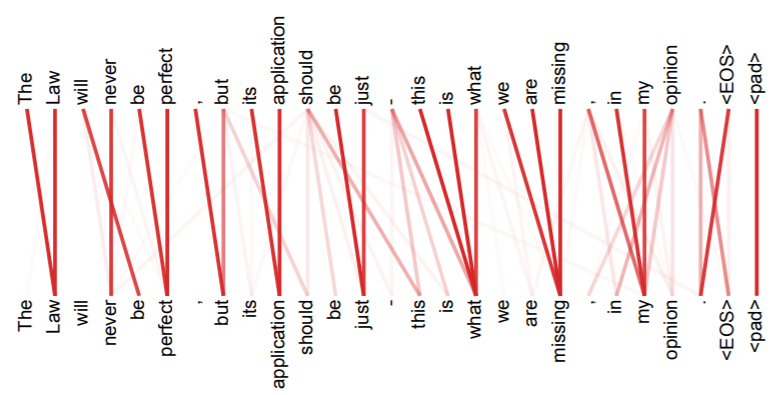
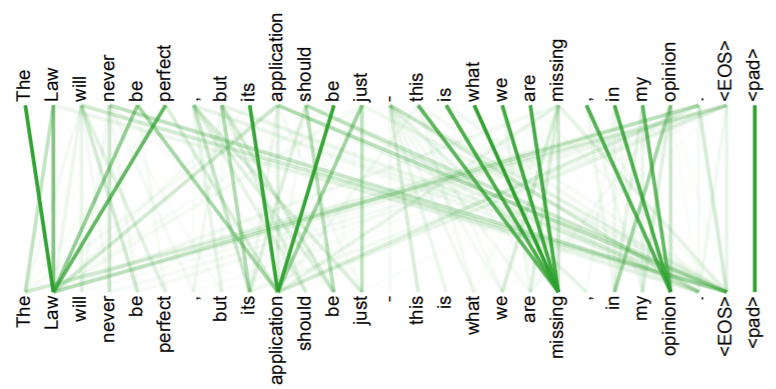
- attention head 개수와 structure of sentence와의 관계를 설명함.
- head의 개수가 많을수록, 다른 task를 학습하는 것으로 보인다고 설명함.
부록
Transformer와 Seq2seq with attention 차이

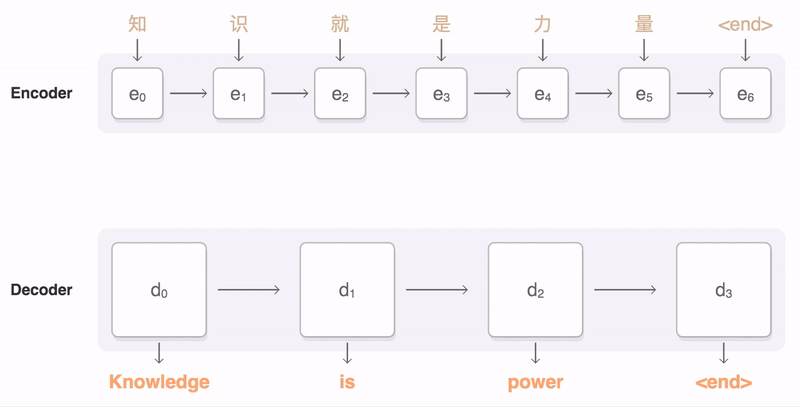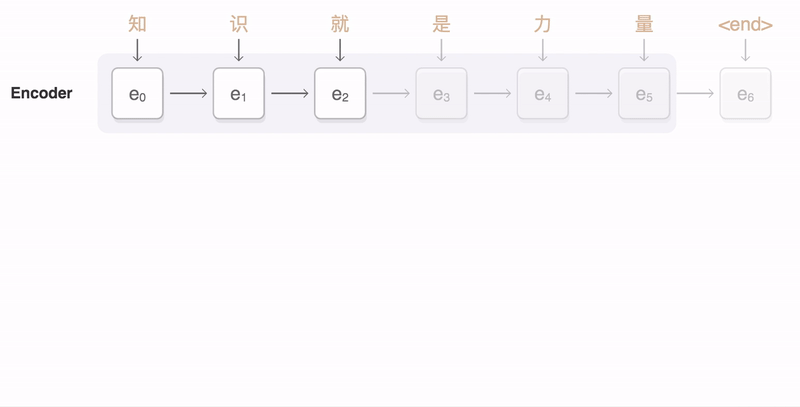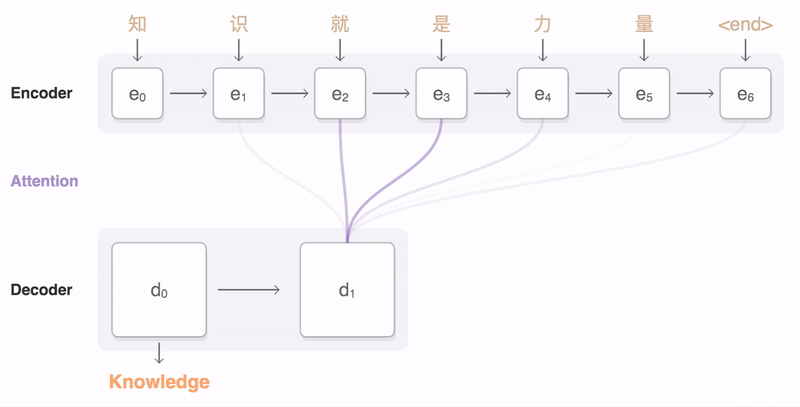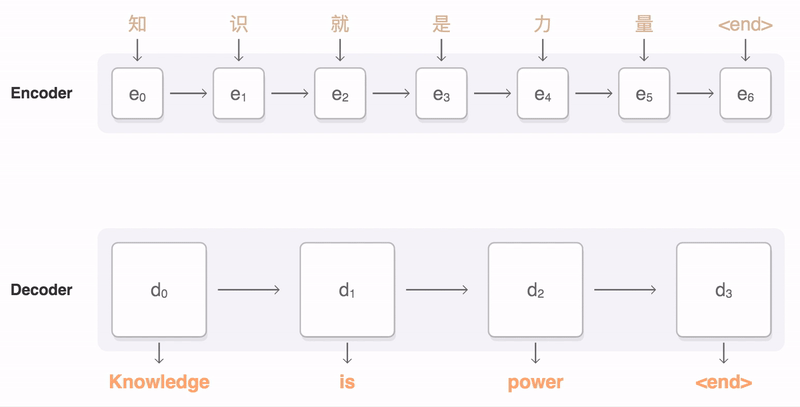
부록
- 프로젝션의 이미지화
Projection the function which maps the point
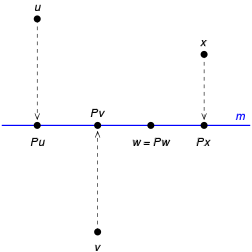
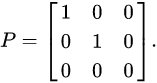
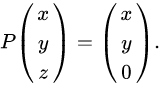
- (x,y,z) in three-dimensional space R^3 to the point
- (x,y,0) is an orthogonal projection onto the x – y plane.
This function is represented by the matrix
