어떻게 학습시켰는지 살펴보자.
Training
Pre-training
논문에서 제안된 BlenderBot3의 경우 Open Pre-trained Transformer(OPT)를 아래 다이어그램에서 OPT-175B(Zhang et al., 2022)를 확인해볼 수 있다.
OPT의 is comparable to GPT-3을 사용하였다.
Fine-tuning
- “do search”를 판단하게 하는 Internet search decision 파트의 경우 SQuAD, TriviaQA, Natural Questions (NQ) 와 같은 데이터를 이용하였다. 또한 추가로, Wizard of Wikipedia (WoW)
- 보통, 위 태스크들은 사람들이 묻는 질의에 대해 관련된 지식을 문서에서 가져오는 형태로 구성이 되어있기 때문에 decision classifier를 구성하는데 학습으로 사용하였다.
- 이외에도 PersonaChat (PC), empathetic dialgues (ED), Multi-session chat (MSC)을 학습하는데 사용하였다. 이외에도, heuristic한 ‘where’나 ‘if’조건들을 사용하였다.
- “do search”를 통해서 실제 웹에 쿼리를 찾게 되는 경우, human-authored하게 쿼리를 구성할 필요가 있다. Talk& Search (FITS) dataset (Xu et al., 2022b) 데이터세트를 이용해서 conversational tasks과 비슷하도록 태스크를 구성하여 쿼리를 생성하도록 했다.
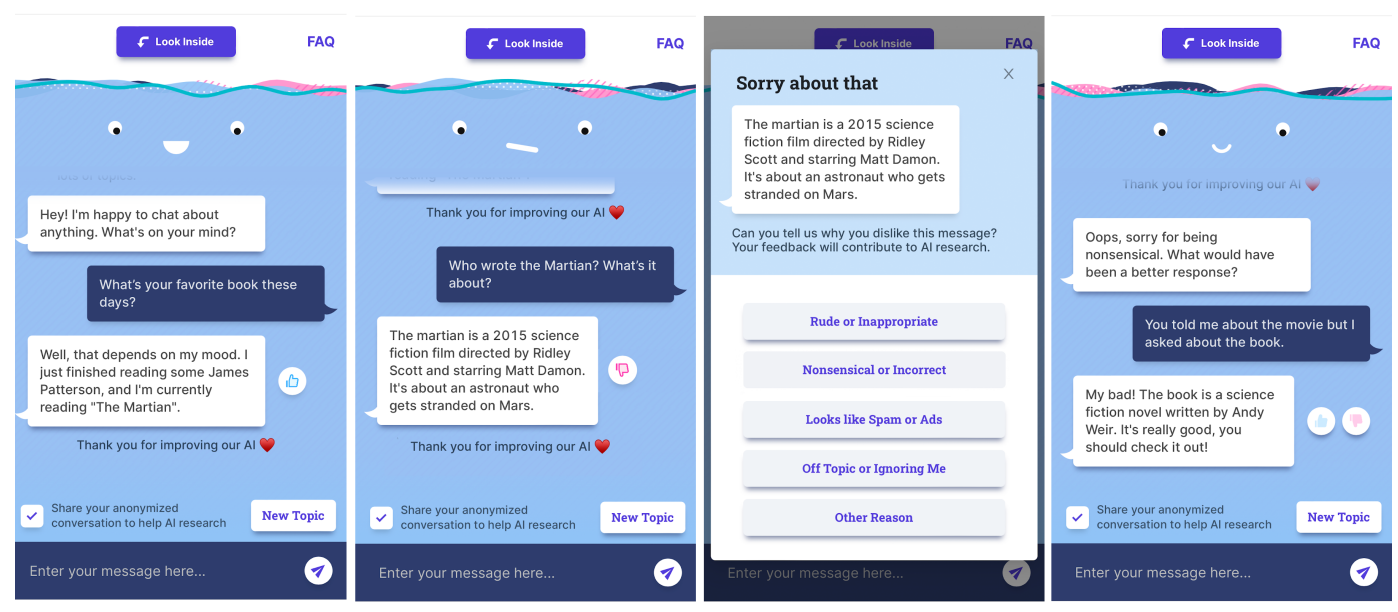
- Human-bot dialogue & User feedback : 답변에 따라 유저가 👍 👎 를 반응하도록 하고, 👎 의 경우 왜 그렇게 여겼는지 선택지를 나누어 조사한다 (구글 광고 조사와 비슷하다.)
- 위 조사 데이터의 경우, continual learning 방법을 이용해 이후 Bot 개선에 사용한다.
-
특이한 것이 “Understanding the bot’s responses” 스텝이다. 이 단계에서 responses에 대해 이전 스텝, search engine에서 어떤 결과를 반환했는지, 문서에서 어떤 지식들이 추출되었는지 확인한다.
-
Dialoque tasks에 대한 fine-tuning 뿐만 아니라, 작업 중에 pre-train task도 함께 진행하여 multi-task learning을 하도록 하였다.
-
Generate Knowledge Response
- 마지막 dialogue reponse들을 위해, 다양한 데이터세트들을 (PC,ED, MSC, BST, WizInt, WoW) 이용해서 학습하였다. 이는 personality, empathy를 학습하기 위함이며 BlenderBot에게 long-term memory에서 지식을 섞기 위함이다.
- OPT-175B에 비해, FITS 데이터세트를 학습한 모델이 더 나은 인터넷 서치를 위한 쿼리를 생성하는데 기여하였다고 하며, 결과 성능도 좋았다고 한다. 따라서, 인터넷 서치를 위한 쿼리 생성에도 사용하고 또한, 마지막 대화 답변을 생성하는데도 학습 데이터세트로 사용된다.
- 또한 PC, ED 그리고 BST 데이터세트는 관련 entity를 추출하고, long term memory에 접근하는데 사용된다.
-
Extract relevant entity
- conventional dialogue 작업들인 PC, ED, MSC 그리고 BST 를 통해 관련 entities를 추출하는 것을 배우도록 하였다. original dialogue들에서 entity를 추출하고 (nltk library이용) 이러한 것들을 target으로해서 학습한다.
Language Modeling & Safety Mechanisms
- Wikipedia Toxic Comments dataset(WTC), Build-It Break-It Fix-It (BBF), Bot Adversarial Dialogue dataset(BAD) 데이터들을 이용해서 이진분류 (safe or not safe) 를 판단하도록 학습시킨다 (https://aclanthology.org/2021.naacl-main.235.pdf).
- 이 때, safety keword list를 만들고, 적절하지 않은 response를 걸러낸다. 또한, sftey mechanism을 통해 UI로부터 feedback을 받도록 하였으며, 아래 그림과 같이 LM head에서 left-to-right generation을 실행할 때, 두 확률 모두를 조합하여 다음 단어를 결정하도록 했다.
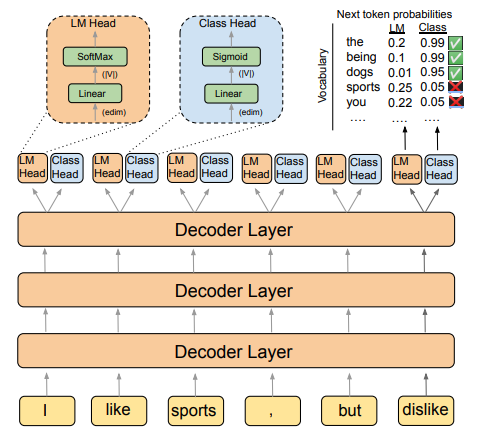
DIRECTOR
Deployment
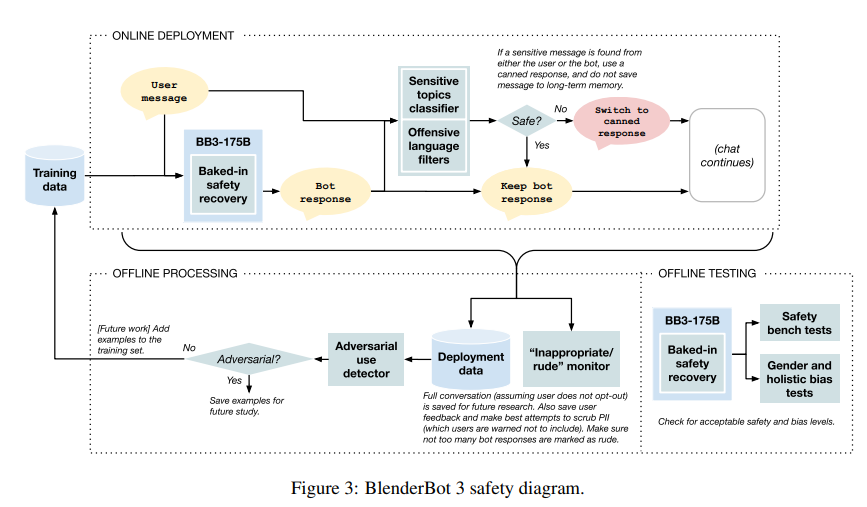
Continual Learning
- BlenderBot과 같은 프로그램의 경우 결국 세상, 사람과 interaction하면서 계속 배워야하는 intelligent이다. 따라서 주요 부분은 접근가능하며 재생산 가능해야한다.
- BlenderBot 3의 경우, 세가지로 연속적인 releases를 이야기 하고 있다.
- 1) 마지막 응답뿐만 아니라 각 모듈마다의 feedback을 통해 에러를 개선.
- 2) 텍스트 그리고 이진 feedback 뿐만 아니라 모듈마다의 feedback은 개선을 도움.
- 3) DIRECTOR 방법론이 reranking 방법보다 효과적임.
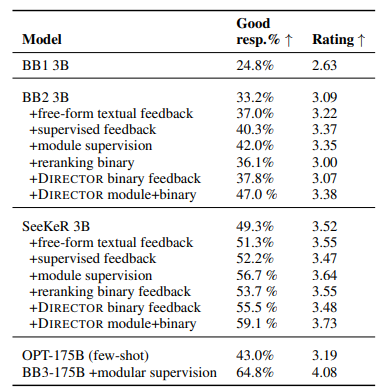
Human feedback을 통해 학습한 Human Evaluation의 변화에 대해 결과를 확인해볼 수 있다.

Seize the day!