Lecture 7 - Linked Lists
- Array-based list class로 stack이나 queue 그리고 deque의 ADT를 구현하였다. Python list 클래스가 최적화 되어있고 저장소로도 좋은 선택이지만 몇 가지 좋지 않은 점이 있다.
- dynamic array가 보통 저장하려는 원소들보다 많다.
- 실제 시스템에서 amortized bounds 는 받아들여지지 않는 경우가 있을 수 있다.
- 배열에서 삽입이나 삭제하는 위치에 따라 비용이 비쌀 수 있다 (시간복잡도가 높을 수 있음).
따라서 이 Chapter에서는 linked list 데이터 구조를 소개한다. Array-based 자료 구조와 linked-list 자료 구조 모두 자료의 순서를 서로 다른 스타일로 보존한다.
1 Singly Linked Lists
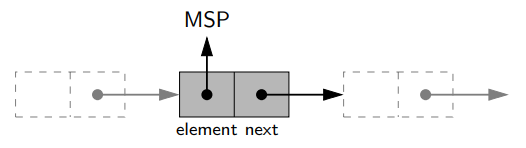
- Singly linked list 는 선형 형태로 연결된 nodes들의 집합이다. 각 node들은 시퀀스의 원소와 (element) 리스트의 다음 노드를 참조하고 있는 (next) 객체를 저장하고 있다.
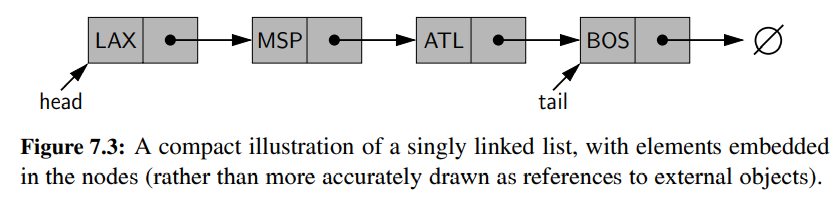
- linked list 는 첫번째 그리고 마지막 node를 head 그리고 tail라고 부르는데, head로부터 시작해서 각 node의 next reference를 통해 다른 node로 이동한다.
- 마지막 node의 next 참조가 None인 것을 통해서 그 node가 tail임을 확인한다.
- 위와 같은 과정을 linked list의 traversing (순회) 과정으로 부른다.
- next 참조가 다른 node에 대한 link 또는 pointer로 볼 수 있기 때문에 리스트를 순회하는 과정은 link hopping 이나 pointer hopping이라고 부른다.
Inserting an Element at the Head of a Singly Linked List
- linked list의 주요한 특성은 이것이 미리 정해진 고정된 사이즈를 가지지 않는다는 것이다. 따라서 linked list는 현재 저장된 원소의 수만큼만 비례해서 공간을 차지한다.
- linked list에서 삽입은 head를 통해서 쉽게 삽입이 가능하다. 예를 들어 가장 처음 자리에 노드를 삽입한다고 하면, 1) 새로운 노드 객체를 생성한다. 이 때, 노드의 next는 head가 가리키고 있는 참조를 같이 가리킨다. 그리고 list 의 head를 새로운 노드를 가리키는 포인터로 설정한다. 이를 수도코드로 나타내면 아래와 같다.
class Node:
__slots__ = "e", "next_" # make limit attribute
def __init__(self, e):
self.e = e
self.next_ = None
Algorithm add_first(L,e):
newest = Node(e) # 새로운 node 객체 생성
newest.next = L.head
L.head = newest
L.size = L.size + 1*보충 : 왜 special method slots 을 쓰는가?
- 요약하면 속성을 가져올 때, 더 빠르고 메모리를 절약할 수 있기 때문.
Removing an Element from a Singly Linked List
- Singly linked list에서 첫 번째 node를 제거하는 방법은 head가 현재 참조하고 있는 것을 다음으로 참조하게 함으로써, 더 이상 현재 head가 가리키고 있는 원소는 의미가 없어지도록 하여 제거한다. 이를 그림으로 표현하면 아래와 같다.
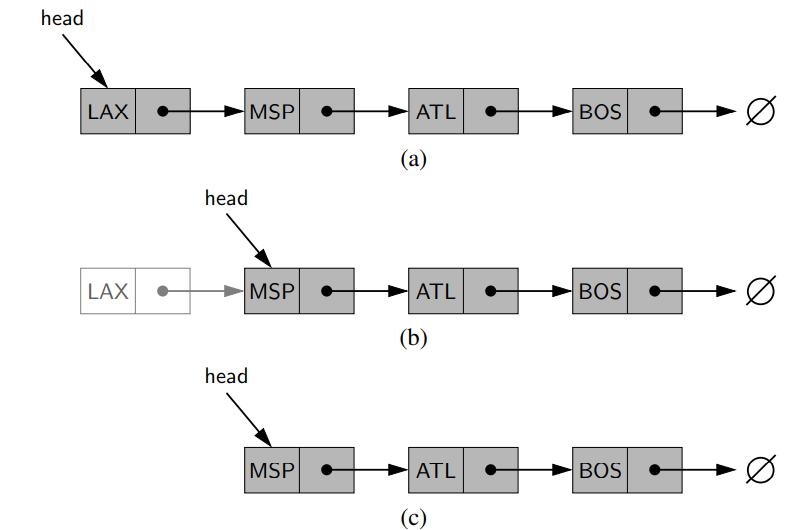
- 이를 코드 조각으로 표현한다.
Algorithm remove_first(L):
if L.head is None then
Indicate an error : the list is empty
L.head = L.head.next
L.size = L.size - 1- 첫 번째 노드는 쉽게 제거했지만, 만약 마지막 노드를 제거한다고 생각하면 single linked list 구조를 살펴보았을 때, head를 이용해서 마지막까지 순회한 후 제거할 수밖에 없다. tail에서는 반대로 next를 이용해서 이동할 수 없기 때문에 순회가 불가능하다. 이런 단점을 커버하기 위해서 doubly linked 리스트 구조가 소개된다.
1.1 Implementing a Stack with a Singly Linked List
class LinkedStack:
class _Node: # nested class
def __init__(self, element, next):
self._element = element
self._next = next
def __init__(self):
self._head = None
self._size = 0
def __len__(self):
return self._size
def is_empty(self):
return self._size == 0
def push(self, e):
self._head = _Node(e, self._head)
self._size +=1
def pop(self):
if self.is_empty():
raise Empty("Stack is empty!")
item = self._head._element
self._head = self._head._next
self._size -= 1
return item
def top(self):
if self.is_epmty():
raise Empty("Stack is empty")
return self._head._element- 아래는 push 에 대해 직접 도식화 한 것이다.
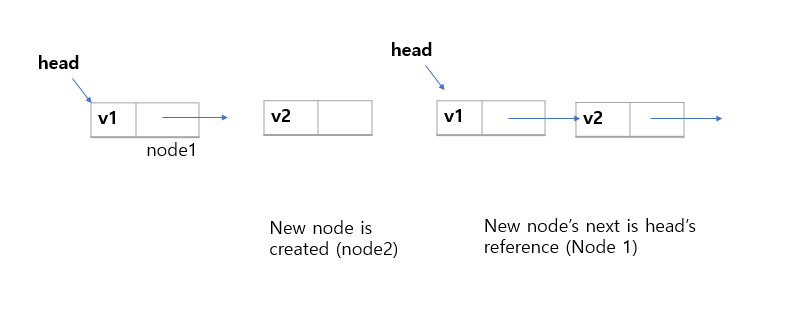
- 직접 구현해보면, linked list 자료구조를 이용한 스택의 경우 head를 이용하여 데이터가 삽입되고 삭제된다. 즉, 한쪽에서 데이터의 삽입과 삭제가 이루어지는 것을 확인할 수 있다. 그리고 먼저 삽입한 쪽이 링크되어 연결되고 삭제는 head가 가리키고 있는 것부터 삭제되므로 LIFO 정책을 따른다고 볼 수 있다.
- 마찬가지로 head를 이용하여 top, pop, push를 구현할 수 있다.
1.2 Implementing a Queue with a Singly Linked List
class LinkedQueue:
class _Node:
def __init__(self, element, next):
self._element = element
self._next = next
def __init__(self):
self._head = None
self.tail = None
self._size = 0
def is_empty(self):
return self._size == 0
def __len__(self):
return self._size
def enqueue(self, e): # tail을 이용하는 부분을 한번 더 체크.
#self._head = _Node(e, self._head) # head를 기점으로 계속 삽입할 수도 있지만,
# tail을 이용하여 삽입하면서, 마지막을 항상 가리키도록 유도한다.
new_node = Node(e, None)
if is_empty(): self._head = new_node
else: self._tail.next = new_node # tail이 마지막을 가리키고 있기 때문에 마지막 다음에 삽입해준다는 의미.
self._tail = new_node # 그리고나서, tail이 다시 마지막을 가리키도록 작업.
self._size += 1
def dequeue(self):
if self.is_empty():
raise Empty("Queue is empty!")
self._head = self._head.next
self._size -= 1
# tail 처리 (저장된 데이터가 1개인 경우)
if is_empty(): self._tail = None2 Circularly Linked Lists
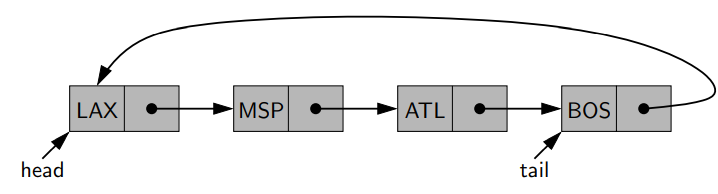
- 이미, 6.2에서 circular array에 대해 개념 소개와 구현을 진행했었다.
- cricular array의 경우 마지막 인덱스가 첫번째 인덱스로 다시 진전되는 것을 의미한다. linked list의 경우 linked list의 tail이 참조하는 것이 list의 첫번째를 가리키는 것으로 표현할 수 있다.
- Head, tail이 따로 없는 linked list의 경우 designated node를 사용한다. (교재 figure 7.8)
Implementing a Queue with a Circularly Linked List
- Circularly linked list의 경우, Queue에서처럼 head와 tail 둘 다 필요하지 않고, tail만 있어도 표현이 가능하다. tail의 next 가 head와 동일한 역할을 하기 때문이다.
- Round-robin scheduler가 대표적으로 고려되는데, 이는 컴퓨터에서 다양한 application에 CPU 시간을 동시다발적으로 할당하는데 이용된다.
class CircularQueue:
# _Node ADT 생략
def __init__(self):
#self._head = None
self._tail = None
self._size = 0
def
3 Doubly Linked Lists
- 리스트의 head에서 접근하는 것 뿐만 아니라 마지막에서 접근한다면 시퀀스 데이터에서 노드를 삽입 및 삭제하는 것의 효율성에 대해 소개했었다.
- 이전에는 이 노드의 앞 뒤를 알 수 없었기 때문에 이 노드를 무언가가 참조하고 있어서 제거하려고 해도 효율적으로 제거가 어려웠다. 하지만 각 노드가 그것의 이전 그리고 이후에 대해서 명확하게 참조하고 있다면 우리는 임의의 노드를 특정할 수 있다. 이러한 자료 구조를 doubly linked list 라고 부른다.
Header and Trailer Sentinels
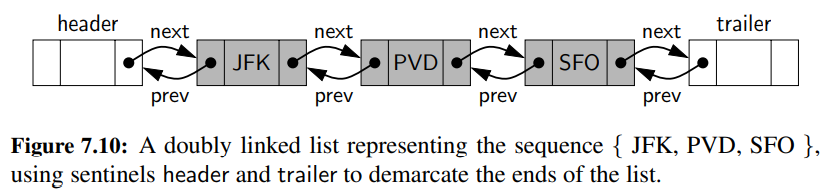
- linked list 머리에 header, 끝에는 trailer node를 붙인다. 그리고 이러한 dummy nodes들을 sentinels 라고 부른다.
- 첫 번째, 그리고 마지막 노드들은 양 옆의 위치를 특정하기 위해서 돕기 위함으로 보인다.
- 삭제될 수 있는 모든 노드들은
3.1 Inserting and Deleting with a Doubly Linked List
- doubly linked list에서 원소를 삽입할 때, 더미 노드를 유지한다. 예를 들어 가장 첫번 째 원소를 삽입할 때, 언제나 header 뒤 헤더 다음 원소 앞에 삽입하게 된다.
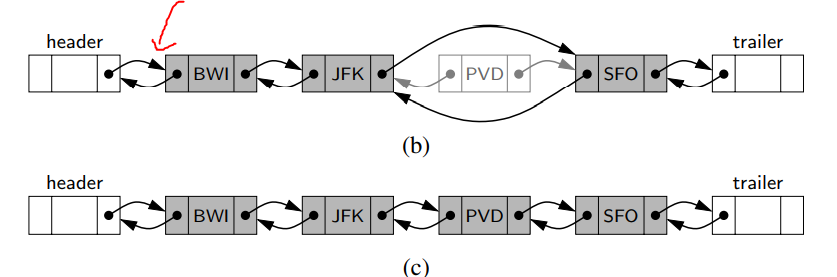
- 순서는 (1) 새로운 노드를 만들고 (2) 새로운 노드의 이웃들과 연결한다.
- 삭제는 비슷한데, 이와 반대이다. 삭제하는 과정은 삭제할 원소의 양 옆을 바로 서로를 참조하게 한다. 자세한 사항은 아래 _DoublLinkedBase 클래스에서 제거 및 삽입 메서드를 살펴보자.
- 이를 구현하여 베이스 클래스를 만들어보자. 이 베이스 클래스는 앞으로 소개할 Positional List 와 같은 링크드리스트의 부모 클래스가 될 것이다.
class Node:
__slots__ = "_element", "_prev", "_next"
def __init__(self, element, prev, next):
self._element = element
self._prev = prev
self._next = next
class _DoublyLinkedBase:
def __init__(self):
self._header = self. Node(None, None, None)
self._trailer = self. Node(None, None, None)
self._header_next = self._trailer # 서로를 가리키고 있는 최초 linked list 생성.
self._trailer._prev = self._header
self._size = 0
def __len__(self):
return self._size
def is_empty(self):
return self._size == 0
def _insert_between(self, e, predecessor, successor):
new_node = self._Node(e, predecessor, successor)
predecessor._next = new_node
successor._prev = new_node
self._size +=1
return new_node
def _delete_node(self, node):
predecessor = node._prev
successor = node._next
predecessor._next = successor
successor._prev = predecessor
self._size -= 1
element = node._element
node._prev = node._next = node._element = None # deprecate node
return element # node's element return - _delete_node 에서 삭제할 노드를 passing하고 다른 노드들끼리 연결한 후, 그 노드의 속성들을 모두 None으로 설정하여 Python의 가비지 콜렉션에 의해 참조되지 않은 인스턴스는 사라질 것이다.
3.2 Implementing a Deque with a Doubly Linked List
- Array-based 구현에서는 deque의 add_first, add_last와 같이 배열을 확장할 때, 때때로 드는 비용때문에 amortized O(1)으로 표현했다. 하지만 _Doubly linked list로 구현을 하게 되면, worst-case인 경우에도 O(1)로 표현할 수 있다. 구현한 _Doubly linked list로 Deque를 구현해보자.
- header에다가 원소를 저장하지 않는다. 마찬가지로 trailer에다가 원소를 저장하지 않는다.
class LinkedDeque(_DoublyLinkedBase):
def first(self):
if self.is_empty():
raise Empty("Deque is empty")
return self._header._next._element
def last(self):
if self.is_empty():
raise Empty("Deque is empty")
return self._trailer._prev._element
def insert_first(self, e):
self._insert between(e, self._header, self._header._next)
def insert_last(self, e):
self._insert between(e, self._trailer._prev, self._trailer)
def delete_first(self):
if self.is_empty(): # delete 시에는 항상 is empty를 체크해준다.
raise Empty("Deque is empty")
return self._delete_node(self._header._next) # dobuly linked list 또한 head 또는 trailer로 접근한다.
def delete_last(self):
if self.is_empty():
raise Empty("Deque is empty")
return self._delete_node(self._trailer._prev)4 Positional List ADT
- 위 섹션들의 큐나, 스택 등은 시퀀스의 끝에서 주로 operation들이 일어난다. 본 책에선 조금 더 현실 예제를 들면서 특정 위치에 접근 가능한 linked list에 대해서 필요성을 이야기한다. (예를 들어 티켓 줄에서 갑자기 줄이 끊어진 경우, 마지막과 끝에서 접근하지 못한다.)
- cursor 를 통해 정수 인덱스 없이 위치를 명시할 수 있다. 또한, 특정 위치의 원소를 제거하거나 cursor 뒤의 원소를 제거할 수 있다.
- doubly linked list에서도 정수로 인덱싱을 한다고 생각해보자, 아무리 header나 trailer로 순회를 통해서 앞뒤로 인덱스를 특정한다고해도, 삽입과 삭제가 자유롭게 일어나는 linked list에서는 그 정수가 계속 바뀔 것이다. 우리는 특정 사람이 빠져나간 자리에 바로 다른 사람을 삽입할 수 있는 유연한 자료구조를 원한다.
A Node Reference as a Position?
- linked list 자료구조는 임의의 위치에서 삽입과 삭제가 O(1)으로 자유롭다는 점에서 가장 강력한 이득을 가진다. (*이 때, 리스트에서 관련 노드를 참조하고 있을 때를 가정한다.)
- 아래 ADT를 살펴보면 대부분 포지션 p를 반환하는 것을 알 수 있다. (예를 들어 deque에서 first() last() 메서드는 element를 반환하지만 여기서는 position을 반환한다.)
- 연두색 부분은 위치를 알려주는 기능을 하는 메서드들의 집합이다. 주황색 부분은 Linked list의 기본적인 기능 영역이며, 노란색 영역은 L을 업데이트하는 역할을 한
4.1 The Positional List Abstract Data Type

- Positional List L의 작동방식을 살펴보자. p, q, r, s와 같은 경우는 Position 클래스의 생성자로 포지션을 의미한다. 여기서는 int형 자료를 element 로 넣고 있는데 따라서 8p, 5q와 같은 형태로 표현된다.

4.2 Doubly Linked List Implementation
- 이를 구현하면 다음 아래와 같이 구현된다.
class PositionalList(_DoublyLinkedBase):
class Position:
def __init__(self, container, node):
self._container = container
self._node = node
def element(self):
return self._node._element
def __eq__(self, other):
return type(other) is type(self) and other._node is self._node
def __ne__(self, other):
return not(self == other) # 왜 self != other 이라고는 표현하지 않는걸까?
# --------------- utility method ------------- #
# we want to verify that the position is valid.
def _validate(self, p):
if not isinstance(p, self.Position):
raise TypeError( "p must be proper Position type" )
if p._container is not self:
raise ValueError("p does not belong to this container")
if p._node._next is None:
raise ValueError( "p is no longer valid" )
return p._node
# we determine the underlying node associated with the position.
**def make_position(self, node):
if node is self._header or node is self._trailer:
return None # If node is put on first or last...
else: return self.Position(self, node)**
# --------------accessors--------------------- #
def first(self):
return self._make_position(self._header._next) # position을 return 함.
def last(self):
return self._make_position(self._trailer._prev)
def before(self, p):
node = self._validate(p)
return self._make_position(node._prev)
def after(self, p):
node = self._validate(p)
return self._make_position(node._next)
def __iter__(self): # L의 모든 커서들에 대해
cursor = self.first()
while cursor is not None:
yield cursor.element()
cursor = self.after(cursor)
# -------------- mutators -------------------- #
def insert between(self, e, predecessor, successor):
node = super()._insert_between(e, predecessor, successor)
return self._make_position(node)
def add_first(self, e):
return self._insert_between(e, self._header, self._header._next)
def add_last(self, e):
return self._insert_between(e, self._trailer._prev, self._trailer)
def add_before(self, p, e):
original = self._validate(p)
return self._insert_between(e, original_prev, original)
def add_after(self, p, e):
original = self._validate(p)
return self._insert_between(e, original, original_next)
def delete(self, p):
original = self._validate(p)
return self._delete_node(original)
def replace(self, p, e):
original = self. validate(p)
old_value = original._element
original._element = e
return old_value5 Sorting a Positional List
- 이전 챕터에서, Array 기반의 자료 구조를 이용해서 insertion-sort를 구현했었다.
- PositionalList를 이용해서 다시 insertion-sort를 구현한다.
- 다음과 같이 세 개의 variable이 운영된다. marker의 경우 현재 정렬된 리스트에서 가장 오른쪽을 가리키며 walk의 경우 pivot보다 큰 것이 있다면 marker로 부터 왼쪽으로 이동한다.
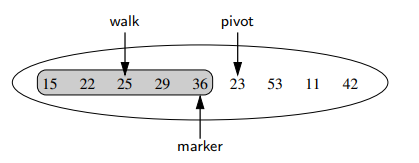
def insertion_sort(L):
if len(L) > 1:
marker = L.first()
while marker != L.last():
pivot = L.after(marker)
value = pivot.element()
if value > marker.element():
marker = pivot
else:
walk = marker
while walk != L.first() and L.before(walk).element() > value:
walk = L.before(walk)
L.delete(pivot) # pivot element는 이미 value로 저장.
L.add_before(walk, value)# 배열 insertion sort와 비교.
def insert_sort(arr):
for i in range(1, len(arr)):
temp = arr[i]
j = i
while j > 0 and temp < arr[j-1]:
arr[j] = arr[j-1]
j-=1
arr[j] = temp
return arr6 Linked-Based vs Array-Based Sequences
💡 Pros and cons of two data structuresArray-Based Sequences
Pros
- 배열 구조의 특성상 정수 인덱스로 요소에 접근하는데 O(1) 시간이 든다.
- 이 특성은 어느 k번째 요소에 접근하더라도 동일하다.
- 특정 자료 구조에서는 강점을 보인다. (e.g. ArrayQueue의 경우 인덱스 부여 시, 수학적 계산 덕분에 배열의 resize 이슈가 덜 발생하며, 오히려 LinkedQueue의 경우 같은 O(1) 시간이라 하더라도 link 를 연결하는데 더 많은 CPU operations이 필요하다.
Cons
- 삽입과 삭제를 할 때, 앞, 중간, 뒤에 따라서 시간이 소요되는 것이 다르며, 특히 앞에서 삽입 삭제를 하는 경우 자리를 모두 옮기면서 진행되기 때문에 소요되는 시간이 크다.
- 지정된 정해진 크기가 있어, 삽입 삭제 시에 따라서 지속적으로 크기를 조정해야하고, 이에 따른 시간이 소요된다.
Link-Based Seqeuences
Pros
- 링크드 리스트 구조에서 임의의 위치에 삽입과 삭제를 할 때, O(1) 시간이 소요되는 것을 지원한다. 특히, PositionalList 클래스에서 지원되는 기능은 매우 유용하다.
- array가 사이즈에 맞춰서 늘어나는 이슈들을 무시할 수 있다.
Cons
- 링크드 리스트의 경우 k번째 요소에 접근하기 위해서는 O(k) 시간이 소요된다. 뒤에서부터 순회하더라도 O(n-k) 시간이 든다.
- k에 접근하기 위해서 처음 또는 마지막부터 접근해야만한다. 체인을 생각하면 손쉽게 떠올릴 수 있다.
- Linked based representations 은 보통 메모리를 더 많이 사용하게 된다. 이는 referential structure까지 함께 저장해야하는 특성때문이다. 따라서 Array based 구조의 경우 사이즈 이슈때문에 2n개의 공간이 필요하다고 하면 link based 구조는 처음부터 2n개의 공간이 필요하다.
연습문제 풀이(짝수)

Seize the day!