Swish activation
-
Swish 함수의 모양
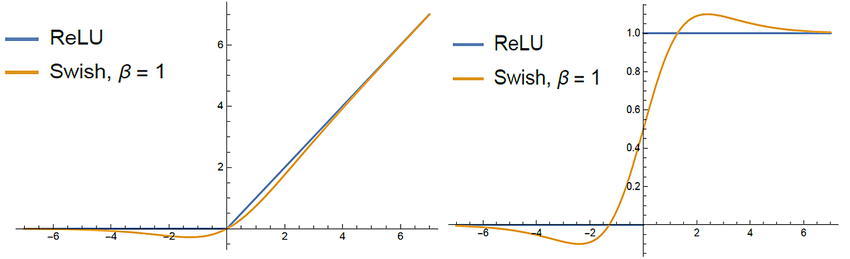
-
PaLM모델 학습 시, ReLU 대신 Swish 사용.
- 와 같이 사용.- 이 경우, 기존 ReLU, GeLU, Swish와 비교해서도 좋은 성능을 보임.
-
실제로 거대한 모델일수록 많은 양의 데이터, 여러 step에 걸쳐 학습을 하게 되므로 기존 Swish뿐만 아니라, W 및 V를 곱한 자기 자신을 다시 내적한 값을 활성화 함수로 사용한다는 것은 정보를 더 보존한다는 의미를 갖지 않을까 해석해봄.
I.I.D (independent and identical distributed)
- “독립적”이고 “동일한 분포”.
- N개의 random 변수들이 독립적이라는 뜻은, 샘플 데이터가 모두 독립된 사건임을 의미한다.
- 한 변수에 대한 정보가 다른 변수사 발생하는데 영향을 미치지 않음을 의미하며 반대의 경우도 동일하다.
- 또한, 동일한 분포에서 나온다는 점은 분포가 변동하지 않고 샘플의 모든 항목이 동일한 확률 분포에서 가져와짐을 의미한다.
출처 : https://en.wikipedia.org/wiki/Independent_and_identically_distributed_random_variables
First Moment, Second Moment
- 통계학에서 Moment를 적률이라고 해석한다.
- 적률은 분포의 모양을 설명하기 위해서 만들어진 개념이라고 보며, 보통 평균과 분산으로 분포의 모양을 많이 나타낸다.
- 따라서, 를 확률 변수 X의 k번째 적률 이라고 읽는다.
- First moment는 , second moment는 , 3rd moment 는 왜도(skewness) , 4th moment는 첨도(kurtosis)를 나타낸다.
- 분포의 모양을 moment들로 표현해볼 수 있고, 이는 분포 함수 그 자체와는 다르다.
출처:
https://en.wikipedia.org/wiki/Moment_(mathematics)
Deterministic vs Probabilistic Models
-
통계에서는 data를 기반으로 real world의 pattern을 찾아낸다. 따라서, 관찰된 데이터를 통해 상황에 대한 가정이나 이론적 확률을 기반으로 실제 상황의 모델을 만들고 이를 이용하여 예측하고 테스트한다.
-
모델을 만들 때, 임의성 요소가 포함되지 않으면 "deterministic model" 무작위 요소가 포함되는 경우 "probabilitistic model"으로 분류한다.
-
임의성 요소가 포함되지 않는다는 말은 동일한 초기 조건으로 모델을 실행하면 동일한 결과를 얻는다는 말이다.
-
대부분의 수학적 모델들은 deterministic한데, 예를 들어 300m의 열기구에서 떨어진 사과의 높이를 모델링한다고 하면 (t=time) 와 같이 식을 세우고, t=1일 땐 h=295, t=2일 땐 280 ... 이와 같이 정해져있고 변동이 일어나지 않는다.
-
probabilitistic model의 경우, 동일한 초기 조건에서도 다른 결과를 낼 수 있다. 예를 들어, 현금 인출기의 대기 시간을 계산하기 위한 모델링을 한다고 생각해보자.
-
고객은 인출기를 사용할 때마다 평균 2분씩 걸리고, 고객이 평균 2분마다 도착한다고 한다는 사전 정보를 얻고, 고객이 3분 이상을 기다려야할 확률을 구한다고 했을 때
-
probabilitistic 모델은 고객이 2분마다 한 사람씩 오는 것이 아니라 임의로 도착할 수 있다는 임의성을 주고, 계산을 위해 시뮬레이션을 한다.
-
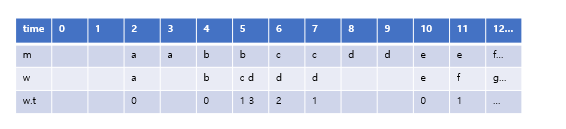
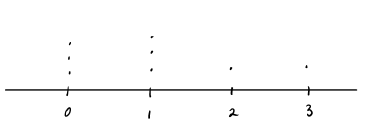
임의성을 가정하지 않는 deterministic 함수의 경우, m의 케이스라고 보면 되고 대기시간은 0이다. 반면, probabilitistic 모델의 경우 w의 케이스처럼 임의의 도착을 가정한다. 이 경우, 대기시간을 w.t (wait time) 아래와 같이 그려볼 수 있다.
Autoregressive decoder의 사용 의미
-
흔히 NLP 연구에서 decoder나 autoregressive나 많이 사용되는 용어이다. 이를 다시 인지해본다.
-
An autoregressive decoder is a decoder model which uses information from previous time steps of the decoder to generate the value at the current time step. An example of such an autoregressive decoder is a English-French machine translation model. While translating from English to French, the decoder will condition its current time step's prediction on the previously generated words (past time steps).
-
"Decoder" is a part that usually produces output from some hidden state.
-
"Autoregressive" means that this is a recurrent structure that uses prediction from a previous state to generate next step, e.g. use previous predicted output word to generate next output word during translation.
공통적으로 autoregressive 하다는 것은 현재-과거와 같은 시간적 개념이 추가된 것으로 현재 시점(t)에서 이전(t-1)의 hidden state를 다시 입력으로 사용한다는 의미를 지니며, decoder는 hidden state로부터 결과를 내는 모델을 지칭하는데 쓰이는 것을 알 수 있다.
출처 : https://stats.stackexchange.com/questions/287013/what-is-an-autoregressive-decoder
Markov chain
- Markov Cahin은 어떤 상태에서 다른 상태로 넘어갈 때, 바로 전 단계의 상태에만 영향을 받는 확률 과정을 의미한다.
- 현재(t) 상태가 바로 직전(t-1)의 상태에만 영향을 받고 그 이외에는 영향을 받지 않는다면 “마르코프 성질(Markov Property)를 가진다고 할 수 있다.
- 그리고 이 확률 과정을 Markov chain이라고 한다.
출처 : https://angeloyeo.github.io/2020/09/17/MCMC.html
Surrogate loss function
- 우리가 classification problem을 푼다고 하였을 때, 우리가 설정한 h(x) 함수를 학습하는데 penalty를 설정할 때, 일반적으로 Y=h(x) 면 0 그렇지 않다면 1 과 같은 식으로 설정하게 된다.
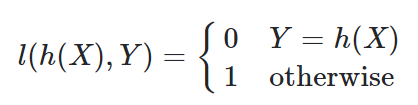
- 이 때, 0-1 loss function은 discontinuous 하다. 따라서 이런 경우, 기존 loss를 대체(surrogate)하여 더 잘 정량화 할 수 있는 방법을 고민한다.
- 예를 들어, hindge loss 개념을 이용하여 와 같이 continous 하게 바꿔볼 수 있다.
- Surrogate loss functions 로는 Risk--risk, classification-calibration, excess risk bounds 와 같은 것들이 있다. loss의 자세한 소개와 proof는 이곳을 참고하고, 다음에 더 자세히 다루도록 한다.
