VIEW & INDEX
뷰(view)란?
🔎 하나의 가상 테이블이라고 생각
🔎 작업시 자주 조회하는 데이터들이 있다. 한 테이블에 데이터가 있으면 조회하기 편하겠지만 그렇지 않은 경우가 있다.
🔎 여러 테이블을 join을 사용하여 가져오고 쿼리가 복잡한 경우도 있다.
🔎 이런 경우 쿼리를 뷰로 만들어 놓고 사용하면 편리하다.
🔎 보안에도 유리
🔎 테이블에 데이터를 노출시키고 싶지 않을 때, 뷰를 사용하여 보유줄 데이터만 뷰로 제공할 수 있다.
뷰의 사용목적
🔎 뷰를 만들어 놓으면 복잡한 쿼리를 쉽게 작성 가능
🔎 원하는 컬럼만 공개하여 원천데이터 테이블 비공개 가능성, 보안에도 유리
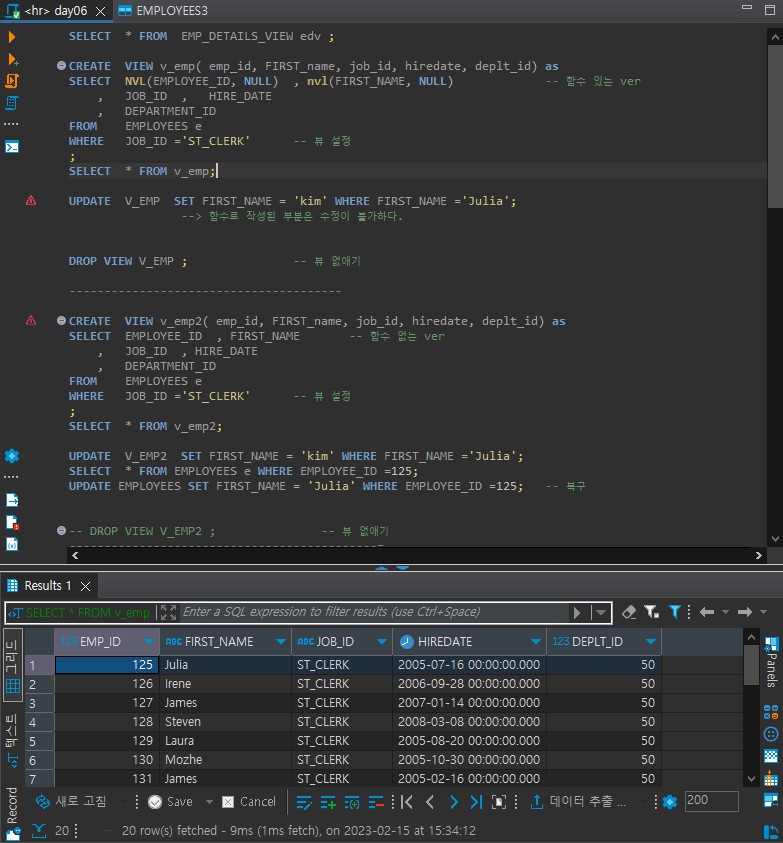
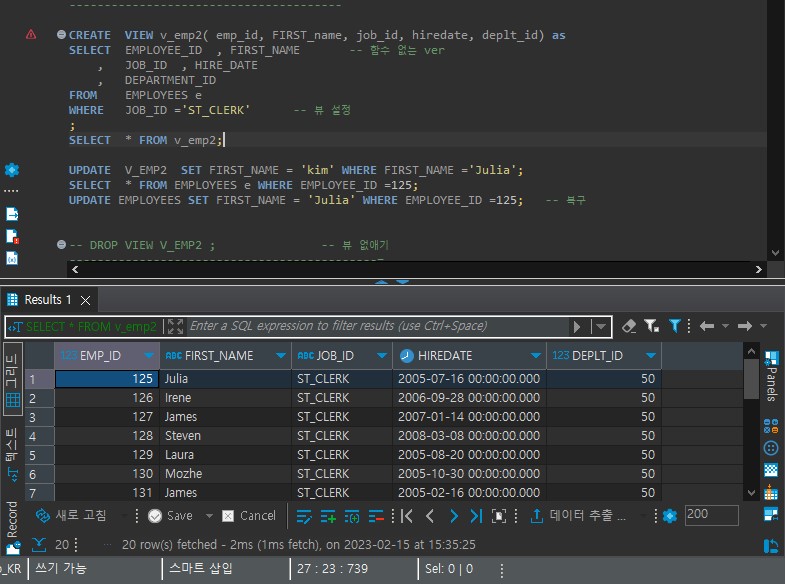
뷰의 특징
🔎 원천 데이터가 변경되면 view 데이터도 자동으로 변경
🔎 뷰의 검색은 자유로우나, 삽입, 수정, 삭제는 제약이 있다.
🔎 뷰생성 쿼리에 함수를 사용하면 반드시 alias를 지정해야 한다.
<예제>
1
2
시퀀스(Sequence)
🔎 연속적인 번호를 만들어주는 기능
🔎 시퀀스란 자동으로, 순차적으로 증가하는 순번을 반환하는 데이터베이스 객체이다.
🔎 보통 pk값에 중복값을 방지하기 위해 사용한다.
-> 데이터베이스에서 객체 순서대로 호출
index
index란?
🔎 조회 속도를 향상시키기 위한 데이터베이스 검색 기술
🔎 색인이란 뜻으로 해당 테이블의 조회 결과를 바르게 하기 위해 사용
🔎 얘가 확실히 많은양의 데이터 분야에서 검색이 빠르다
index원리
🔎 index를 테이블의 특정 컬럼에 한 개 이상 주게되면 index table이 따로 만들어지고, 인덱스 컬럼의 로우값과 rowid값이 저장되며 로우값은 정렬된 트리 구조로 저장시켜 두었다가 검색시 좀 더 빠르게 해당 데이터를 찾는데 도움을 준다.
🔎 모든 컬럼에 index를 걸면 안된다.
🔎 특정된 공통 조건이 존재하거나, 특정 조건에서 join을 할 때만 index 를 사용하는 것을 권장한다.
🔎 하지만 DML명령을 사용할 때는 원본 table은 물론 index table에도 데이터를 갱신시켜 주어야 하기때문에 update, insert, delete 명령을 쓸 때, 속도가 느려진다는 단점이 있다.
index 생성이 불필요한 경우
🔎 데이터가 적은 경우에는 index를 설정하지 않는게 오히려 성능에 좋다.
🔎 조회보다 삽입, 수정, 삭제 처리가 많은 테이블은 고민해볼만 하다.
DML 명령어를 이용했을 경우 취약점
🔎 insert : 두 개의 테이블에 동시 insert
🔎 delete : index에서는 데이터를 사용하지 않음으로 표시하고 데이터를 지우지 않는다.
🔎 update : index에서는 delete한 후 새로운 데이터를 insert 작업을 한다.
index 생성
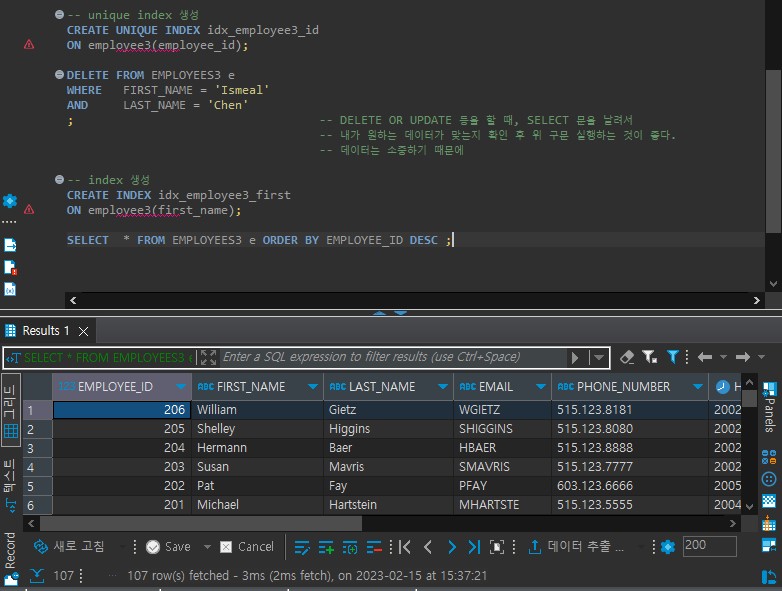
🔎 unique index
: 인덱스를 사용한 컬럼의 중복값들을 포함하지 않고 사용할 수
있는 장점이 있다.
create unique index 인덱스명 on 테이블명(컬럼);
🔎 non-unique index
: 인덱스를 사용한 컬럼의 중복 데이터 값을 가질 수 있다.
create index 인덱스명 on 테이블명(컬럼);