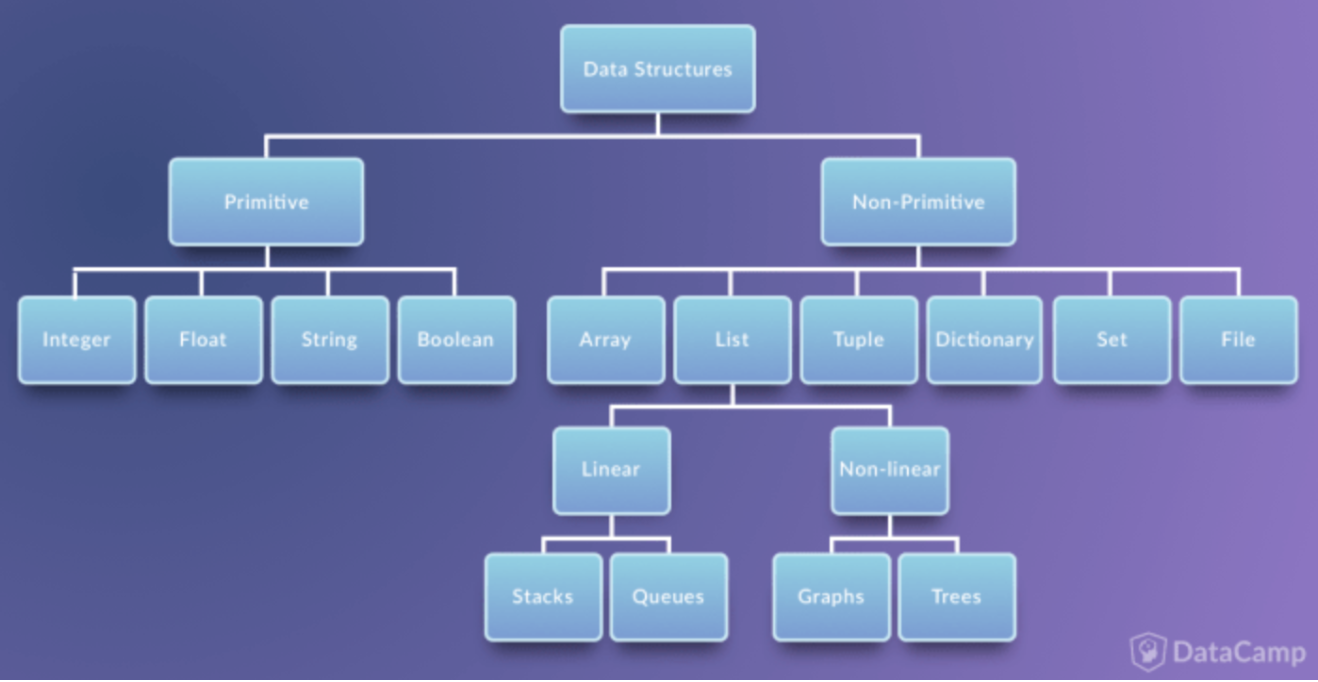
자료구조가 왜 필요한가?
https://stackoverflow.com/c/wecode/questions/184/185
우리가 짐을 싼다고 생각해보자. 캐리어에 넣을 수도 있고 파우치에도 넣을 수 있다. 어떻게 하면 효율적으로 할 수 있을까? 에 대한 고민과 같다. 각각에 정해진 법은 없지만 알맞는 곳에 넣어서 관리하는 것.
데이터를 알맞는 구조에 넣고 관리하는 것.
노트북을 쇼핑백에 넣는 것과 백팩에 넣는 것에 엄청난 차이가 있듯이, 데이터 또한 그러하다.
해당 데이터에 적합한 자료 구조들이 있고 그 자료구조를 적절하게 선택하는 것이 프로그래밍에 중요하다.
코딩은 알고리즘과 자료구조 두가지로 이루어진다고 할 만큼, 자료구조는 중요하다.
Array ( list)
배열
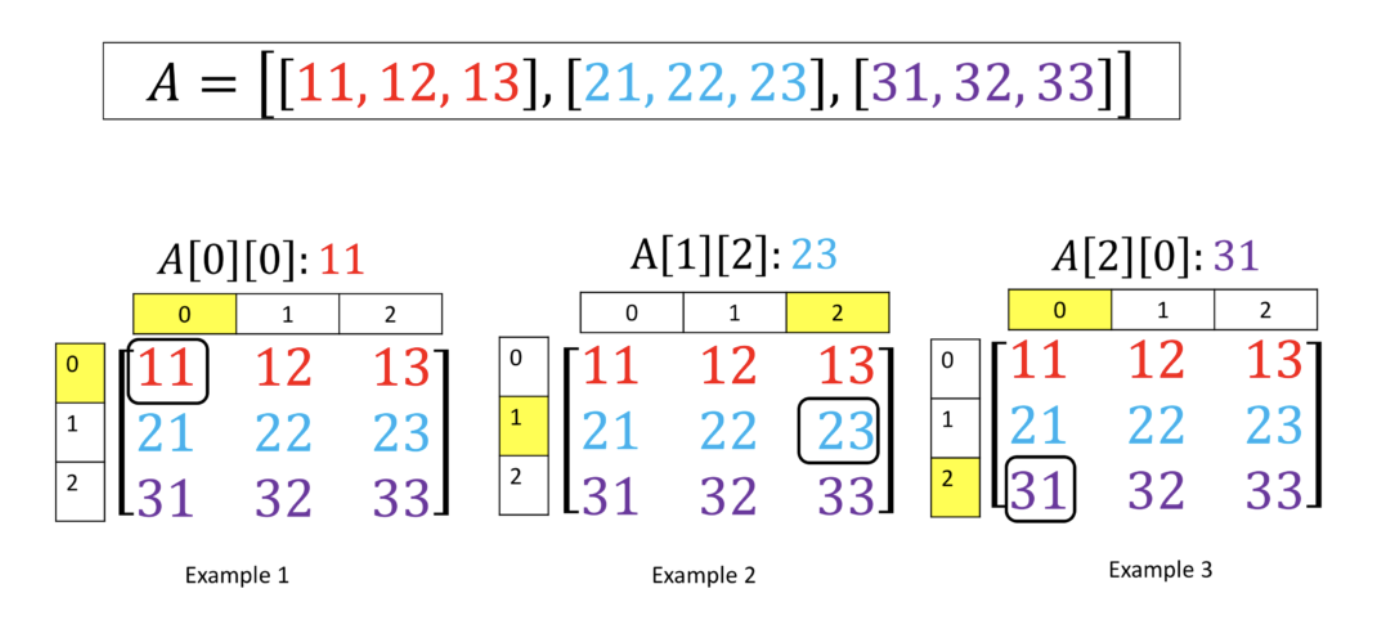
order( index) 순서가 있는 자료
그럼 왜 순서가 있는가? 물리적으로 저장될 때 순서대로 저장된다.
- 0이 저장되면 1이 저장, 1이 저장되면 2가 저장. ( 메모리상에서 옆에 붙어서 저장되기 때문에)
- 순서가 있다 보니까 인덱스가 가능한 것.
- 인덱스가 있기 때문에 특정 몇번째 엘리먼트만 뽑아낼 수 있는 것 ( 19번째만 할거야! slice 할거야 ( 10번째에서 20번째까지 할거야)
어떤 데이터를 저장할 때 array를 사용할까?
값보다는 순서가 중요한 데이터일때( 이미지, 주식 정보 )
Multi Dimentianl Array 리스트 안에 리스트가 있을 때
장단점
장점
순서가 있다.
단점
뭔가를 삭제할때 큰 단점이 있다. 중간에서 뭔가를 삭제해야 한다.
100개중에서 49번째를 삭제하면 뒤의 모든 데이터들을 하나씩 당겨야 한다.
중간에 비면 안되기 때문에 붙여주어야 한다.
코드상에서는 간단하지만 그 뒤에서 일어나는 일은 엄청나게 많다.
중간의 뭔가를 자주 삭제해야 하는 데이터의 유형이면 좋지 않다. ( 효율적이지 않고 , 비싸다)
삽입하는 것 또한. ( append) 순서대로 되어 있어서 뒤에 붙이면 편하다. 하지만 중간에 뭔가를 넣으려고 한다면 전체적으로 영향을 준다.
중간에 계속 넣어야 하는 경우에도!
resizing에 문제가 있다.
10개가 저장되어 있고 그 다음에 하나를 추가한다고 하면 메모리 상에서 하나를 뒤에서 넣는 것이다.
만약 이미 10개가 다른 곳에 저장되어 있다면?
메모리에는 여러가지의 다양한 데이터를 가지고 있다. 허용되는 메모리 안에서는 자유롭게 저장될 수 있지만 내 배열은 바로 다음에 붙어야 하는데 다른 것이 쓰고 있다.
애초에 array를 만들면 어느정도의 메모리를 확정하고 리스트가 만들어진다.
200개면 한 그정도의 사이즈를 정해놓고 만들어진다.
201번째를 넣으려면 재할당을 해야 한다. 그 두배의 메모리를 할당하고 그 전의 것을 넣은 후에 추가된 것을 넣는다.
내가 확보한 사이즈를 초과하면 설정한 값만큼의 새로운 메모리를 다시 확보해야 한다.확보 - 복사 - 붙이기 - 추가
집이 다차서 새로운 곳으로 이사하는 것과 같음
어떨때 쓴다
-어떤 요소를 빠르게 읽어야 할때
-데이터의 사지으가 급변하지 않을 때
-요소를 자주 수정하거나 삭제하지 않을 때
tuple
있는 언어도 있고 없는 언어도 있는데 파이썬에는 있다.
어레이처럼 순서가 있는 구조인데 어레이는 많은 데이터를 순차저장할 수 있는데
tuple은 2개~5개 사이의 정보만 저장하는 용도로 많이 쓰인다.
한번 넣으면 수정할 수 없다.
그러면 왜 쓸까?
간단한 값들을 빨리 표현하고 싶을 때
( ex. 함수에서 리턴값을 두개~세개만 하고 싶을 때, 좌표 데이터)
단점
누가봐도 명확한 데이터일때
이런 단점을 없애기 위해서 named tuple
set
( 면접 질문 _ list와 set의 차이를 말해보아라)
순열 자료 구조. 여러가지의 자료들을 포함하고 있는데 list와의 가장 큰 차이는 순서가 없다는 것.
12345로 넣었어도 내가 읽을 때 집어 넣은 순서대로 나온다는 보장이 없다.
중복된 값을 허용하지 않는다.
12345 12 를 넣으면 12345로 나온다. ( 중복된 값은 삭제된다.)
값을 넣었는데 이미 있으면 새로 넣은 것으로 치환된다.
중복된 값들을 없애주기 위해서 편하게 하는 것
그러면 왜 set는 왜 순서가 없을까?
집어 넣은 값을 hash 한다. hash 값이 1234 라면, 1234에 해당하는 메모리 공간에 데이터를 저장한다. ( 이것을 backet)
데이터를 넣으면 해시 함수로 해시값을 만들어 저장
이렇게 하기 때문에 순서가 없다.
a -> 해시값 1234
나중에 a를 또 넣음. 해시값 1234
어 똑같네? 갈아 끼워 넣음
모든 class는 object.
그 object는 해쉬 함스를 가지고 있음
사실 set도,밑단이 array로 되어 있다.
해쉬충돌을 최소화 해야 한다.
해쉬값이 10자리라면 3자리를 가지고 인덱스를 구한다.
그래서 들어갔는데 이미 데이터가 정해져 있다면? 그럼 다음 3자리를 가지고 해쉬값을 구해서 빈자리를 찾아간다.
이게 파이썬이 디폴트로 가지고 있는 구조
그런데 충돌이 잦으면 인덱스 값을 계속해서 구해야 하기 때문에 비효율적이게 되는 것.
밑단에 있는 array에 아무것도 없다면 충돌될 확률이 낮다.
그래서 set도 어느정도 array가 어느정도 차면 resize를 한다. ( 충돌의 확률을 낮추기 위해서)
그러면 언제 쯤 찼을 때 resizing을 해야 할까? ( 약 70% )
object처럼 같은 키를 넣으면 그걸 바꾸고 순서가 없다.
그럼 언제 set를 써야 할까?
중복이 없어야 하는 것
중복된 데이터가 없어야 한다면, list와 set을 쓰는 차이가 엄청나게 차이난다. list는 하나씩 돌면서 새로운 배열을 계속 만들어야 하는 반면 set는 한번만 돌리면 된다.
Dictionary
키, value로 저장할 때

이게 어떤 데이터인지에 대한 설명이 필요할 때
쓰지 않으면 class를 써야겠지만, 그렇게 까지 할 필요는 없을 때
어떤 기능까지 포함해야 한다면 class
JSON
-set는 중복된 값을 허용하지 않는다.
Dictionary는 중복된 키를 허용하지 않는다.
cord(1,2) == cord(1,2)
false이다. 저장한 메모리의 주소가 다르기 때문에 (같은모양의 객체가 같지 않은것과 같음)
하지만 이것은 개발자에 의해서 그걸 조정할 수 있다.
1==1
'A' == 'A'
더 복잡한 데이터로 가면 그 과정이 복잡해짐
x, y, z 가 있는데 x, y만 같으면 같다고 치부하면, z의 값에 상관이 없게 되는 것.
그래서 객체는 정말 완전히 똑같다고 볼 수 있으니까 치환하는 것
Stack과 Queue
stact
아래에서 부터 쌓아올리는 것
접시 쌓는 것과 비슷
먼저 넣은 것은 1번부터 하지만 빠지는 것은 10번 ( 마지막)
먼저 들어갔지만 마지막에 나올 수 밖에 없는 것
밑단에는 array를 가지고 있음. ( 어레이가 가장 효율적이기 때문에 . 여기에 약간의 로직을 더해서 다른 것을 만드는 것)
그러면왜 stact을 써야 할까?
first in last out
맨 마지막에 들어간게 처음으로 나와야 하는 것
함수를 생각해보면
무한루프에 잘못 걸렸을 때 stackoveflow
Queue
stack의 반대
줄서는 것에
fitst in first out
FIFO
밑단에는 array, 여기에 로직을 붙여서 먼저 간애가 먼저 나오게 하는 것
순서중의 우선순위
priority que
어떤 경우?
운영체제! cpu가 하나일때 ( 프로그램을 여러게 돌릴 때 계속해서 왔다갔다 실행 하는 것 / 긴급한게 있으면 그것부터 시작해야 하는 경우 )
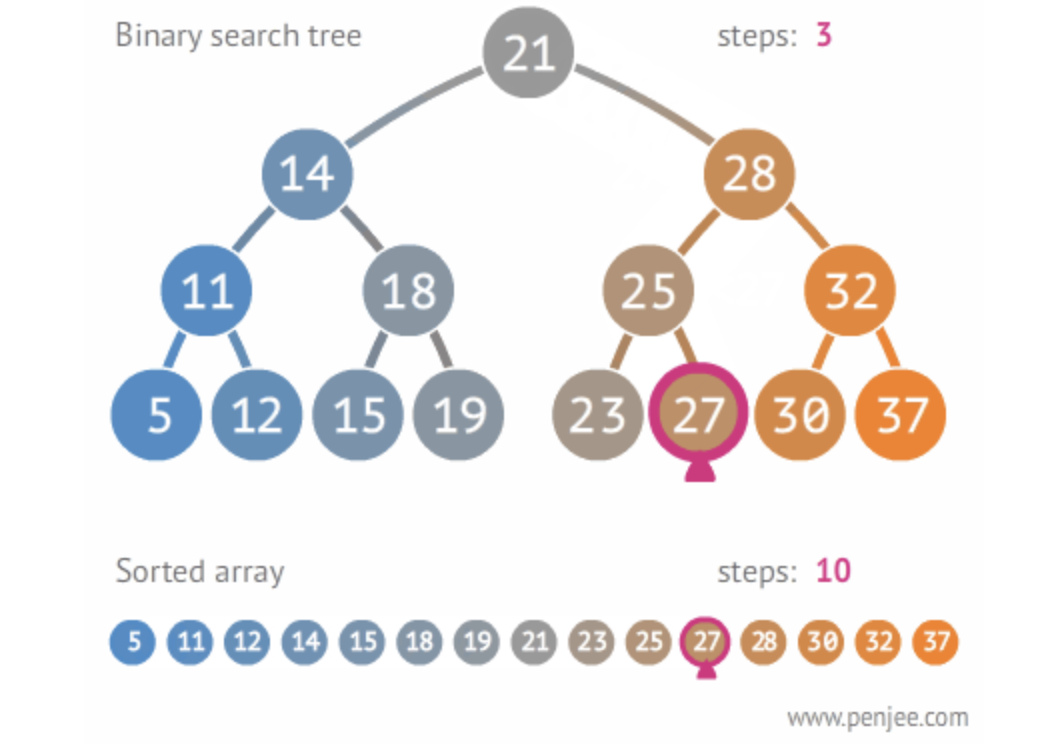
Tree
원에 두개가 붙는 것
Lookup이 빠르다.
-빠르게 찾아내야 할때
set도 빠른데 왜 Tree를 해야 할까?
작은 값은 왼쪽 큰 값은 오른쪽
linked list
array
물리적으로 순차적으로 저장하는 것이 array
그 물리적인 공간을 확보해야 하는 것이 단점이었다.-
그러한 제약을 없애면서 list로 저장하는 구조가 linked list
A - B가 아니라 계속해서 다른 주소를 참조하는 것.
어딘가에 다른 곳에 저장. 그리고그 다음에 저장할때 또 그 다른 주소를 참조
memory resizing의 문제는 없지만 한 값을 만드는 것에 대한 로직이 있어서 효율성이 떨어진다.
computer science 에서 만병통치약이 없다. 시간과 메모리 둘중 하나를 희생 시켜야 한다.
Q. set 과 list의 차이
-순서, 중복
-Set은 해쉬값을 통한 버켓 저장
Q. list는 어떻게 인덱스를 가질 수 있는가?
