
📚 시작하며
지난번 Event Publisher를 사용하여 비동기적으로 조회수 이벤트를 처리한 글을 작성한 이후, 아래와 같은 질문을 받았습니다.
"10만 명의 사용자가 동호회를 접속했을 때, 조회수가 10만 만큼 올라가나요?"
조회수 증가 로직이 실패하는 경우가 언제일까 고민해보다가 동시성 이슈가 가장 먼저 떠올랐습니다.
그래서 이번 글에서는 아래의 질문에 대해 고민하고 해결해나가는 과정을 담아보려고 합니다! 😄
다수의 사용자가 하나의 동호회를 동시에 조회했을 때, 조회수가 정상적으로 올라갈까?
🖍️ java.util.concurrent
동시성 문제를 어떻게 경험하고, 테스트 할 수 있을까요?
자바의 java.util.concurrent 패키지를 살펴보도록 하겠습니다. 해당 패키지에는 ExecutorService 및 CountDownLatch와 같은 여러 동기화 장치가 포함되어 있습니다.
ExecutorService란?
스레드풀을 제공하며, 각각의 스레드에 작업을 할당할 수 있습니다.
Future<?> submit(Runnable task);주어진 작업(task)을 실행하고, 모든 작업이 완료되었을 때 작업 상태와 결과를 보유한 Future 리스트를 반환합니다.
executorService.shutdown();스레드 풀을 종료하여 리소스를 해제합니다.
CountDownLatch란?
CountDownLatch를 사용해 다른 스레드들이 주어진 일을 완료할 때까지 특정 스레드를 대기 상태에 들게 할 수 있습니다. 이는 각각의 스레드가 작업을 종료하면 1씩 감소하는 counter field입니다.
CountDownLatch latch = new CountDownLatch(numberOfThreads);생성 시 초기 카운트 값(정수)을 설정합니다. 이때 numberOfThreads는 작업할 스레드의 개수와 동일한 값으로 설정합니다.
latch.countDown();latch의 카운트 값을 감소시킵니다. 만약 현재 카운트 값이 0보다 크다면, 1 줄어듭니다.
latch.getCount();현재 카운트 값을 반환합니다(long 타입). 디버깅 또는 테스트 용도로 활용할 수 있습니다.
latch.await();카운트 값이 0이 될 때까지 스레드를 대기 상태로 유지합니다. 모든 스레드가 작업을 완료하여 카운트가 0이 될 때까지 메인 스레드가 대기합니다. 카운트 값이 0이 되면, 대기 중이던 모든 스레드가 깨어나고 대기 상태에서 해제됩니다.
✍️ 테스트 코드 작성
자, 이제 테스트 코드를 작성해보도록 합시다!
- 테스트 시나리오
100명의 사용자가 동시에 UUID가 club_token_1인 동호회를 조회하는 상황을 가정해보겠습니다. 해당 동호회에 대한 조회수는 100만큼 올라야 합니다.
@SpringBootTest를 사용하여 통합 테스트를 진행하였습니다.
@SpringBootTest(classes = BadmintonApplication.class)
@ActiveProfiles("test")
@Transactional
public class ClubReadConcurrencyTest {
@Autowired
private ClubStatisticsRepository clubStatisticsRepository;
@Autowired
private ClubStatisticsService clubStatisticsService;
@Test
void 동호회_조회_동시성_테스트() throws InterruptedException {
///given
ExecutorService executorService = Executors.newFixedThreadPool(20);
CountDownLatch latch = new CountDownLatch(100);
//when
for (int i = 0; i < 100; i++) {
executorService.submit(() -> {
try {
clubStatisticsService.increaseVisitedClubCount("club_token_1");
} catch (Exception e) {
e.printStackTrace();
} finally {
latch.countDown();
}
});
}
latch.await();
executorService.shutdown();
//then
int visitedCount = clubStatisticsRepository.findByClubClubToken("club_token_1").getVisitedCount();
assertThat(visitedCount).isEqualTo(100);
}
}😵💫 CountDownLatch, latch.await() 대체 뭐야?
이 개념이 저에게는 다소 어려웠기 때문에, 설명을 하고 넘어가려고 합니다. 이미 알고 계시다면 내용이 조금 길기 때문에 넘어가주세요 ... 🙏
테스트 코드를 실행하는 Test Worker 스레드, 비동기적으로 실행되는 20개의 스레드
System.out.println("스레드 이름: " + Thread.currentThread().getName());중간 중간에 스레드의 이름을 찍어 보면 아래와 같이 출력됩니다.
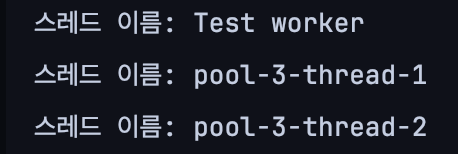
Test Worker는 테스트 코드 실행을 위해 만들어진 스레드입니다. 이 스레드는 JUnit과 같은 테스트 프레임워크가 테스트를 실행할 때 기본적으로 사용하는 스레드 이름입니다.
그럼 그 아래 pool-3-thread로 시작하는 스레드는 무엇일까요?
Test Worker 스레드는 아래의 코드를 실행합니다.
ExecutorService executorService = Executors.newFixedThreadPool(20);ExecutorService는 크기가 20인 스레드 풀을 생성합니다. 즉, 최대 20개의 스레드가 동시에 작업을 처리할 수 있습니다.
이제 submit() 메서드를 통해 스레드풀에 제출된 100개의 작업은 비동기적으로 처리됩니다.
latch.await()가 없다면?
Test Worker 스레드는 100개의 비동기 작업이 완료될 때까지 기다려주지 않습니다.
스레드풀에 제출된 100개의 작업이 아직 실행되고 있더라도, Test Worker 스레드는 아래로 쭉쭉 내려갑니다.
만약 latch.await()가 없었다면 Test Worker 스레드는 그 아래 executorService.shutdown()을 실행할 것입니다. 그럼 스레드풀이 종료되고 리소스가 해제되기 때문에 위에서 할당해준 작업들 또한 중단됩니다.
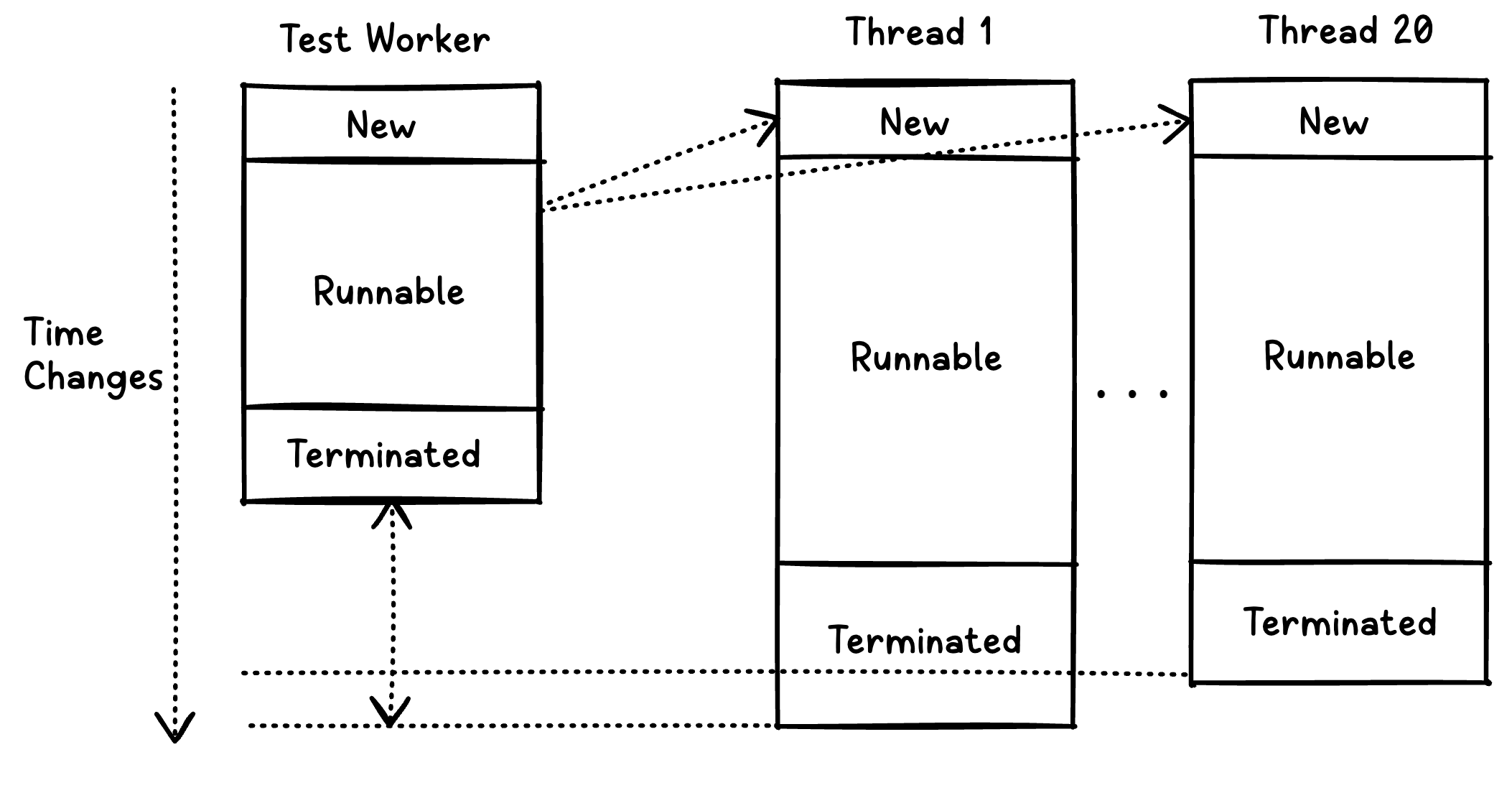
위의 그림을 통해 Thread1~20이 아직 작업을 처리 중인데, Test Worker 스레드는 실행을 마치고 종료된 모습을 확인할 수 있습니다.
즉, latch.await()가 없다면 동시성을 제어했더라도 테스트가 실패할 것입니다. Test Worker 스레드는 20개의 Sub 스레드가 수행하는 100개의 작업이 끝나기도 전에 종료되기 때문이죠.
이래서 CountDownLatch를 사용하는구나!
저희가 원하는 것은 Thread1~20이 100개의 작업을 모두 끝마치고 난 뒤의 결과값을 확인하는 것입니다.
따라서 Test Worker 스레드는 잠시 실행을 멈추고 20개의 Sub 스레드가 100개의 작업을 모두 마칠 때까지 기다려줘야 합니다. 이때 CountDownLatch라는 걸쇠를 사용할 수 있습니다.
CountDownLatch latch = new CountDownLatch(100);카운트값을 100으로 설정해 CountDownLatch를 만들었습니다.
finally {
latch.countDown();
}하나의 작업이 완료될 때마다 finally 구문 안에 있는 latch.countDown();가 실행되어 카운트값이 1씩 감소합니다.
100개의 작업이 모두 완료되면, 카운트값이 0이 됩니다.
latch.await();Test Worker 스레드가 위의 코드를 만나면, CountDownLatch의 카운트값을 확인합니다. 만약, 0보다 크다면 대기 상태에 머무릅니다. 0이라면, 대기 상태에서 해제됩니다.
위에서 확인했듯이, 스레드풀에 제출된 100개의 작업이 모두 완료되면 카운트값이 0이 되며, 이때 Test Worker 스레드가 대기 상태에서 해제됩니다!
즉, CountDownLatch는 Test Worker 스레드가 100개의 작업이 모두 완료될 때까지 대기 상태에 머무르도록 하는 역할을 합니다.
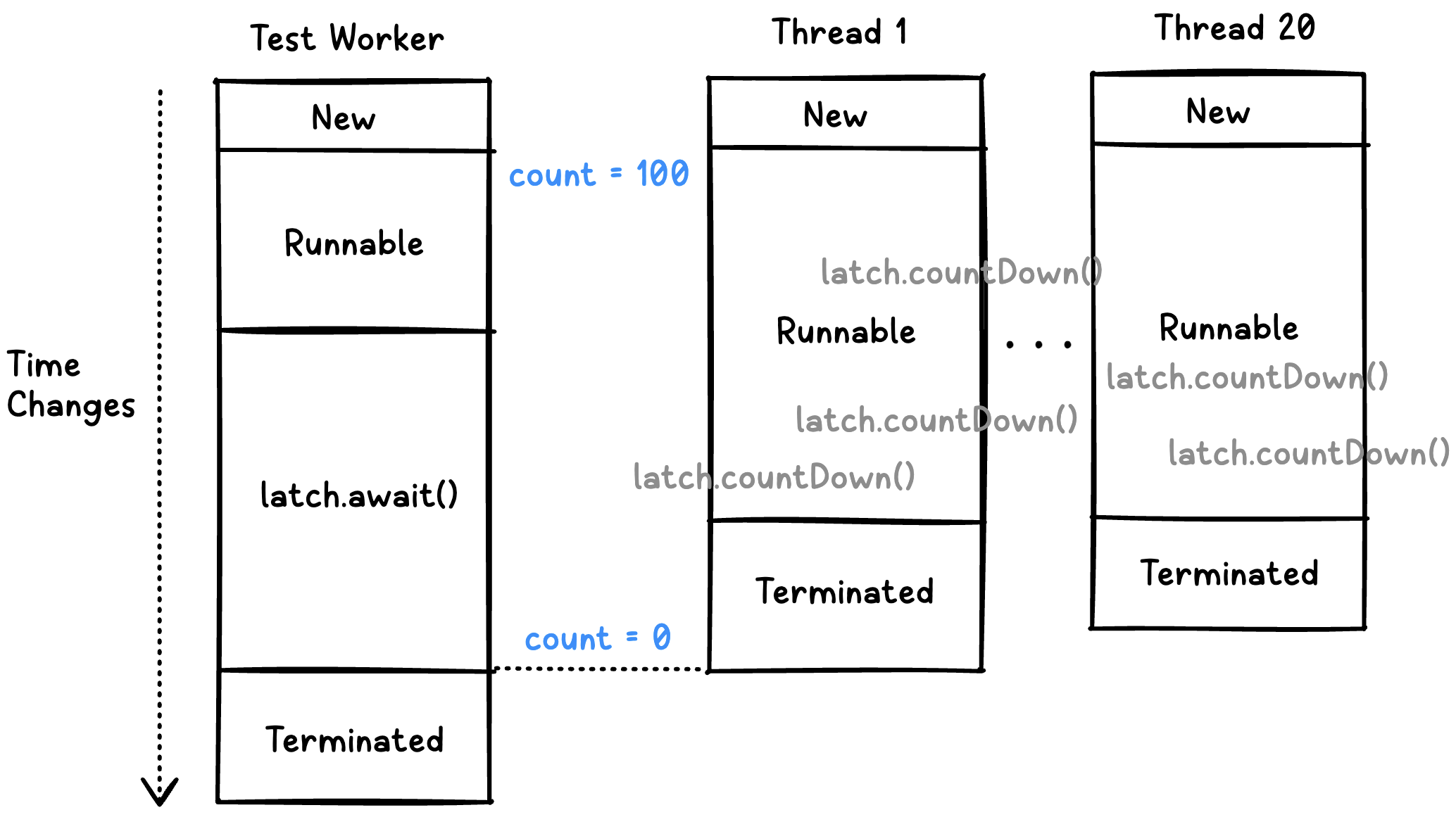
위의 그림을 통해 더이상 Test Worker 스레드가 비동기 작업이 끝나기 전에 종료되지 않고, 스레드풀에 제출된 작업이 모두 완료될 때까지 기다려주는 것을 확인할 수 있습니다.
Thread.sleep() 쓰면 되지 않아?
Thread.sleep()은 지정된 시간 동안 현재 스레드를 중단합니다. 다만, 의도한 이벤트 발생 시점에 맞춰 작업을 재개할 수 없습니다. 작업이 끝나는 정확한 시간을 예측하기 어렵기 때문에 테스트 수행 시 불필요한 대기 시간이 발생할 확률이 높습니다.
이와 반면, CountDownLatch 사용 시 정확한 이벤트 기반 동작이 가능합니다!
🤔 왜 이런 일이?
테스트한 결과, 평균 10% 정도의 성공률을 보였습니다. 즉 100명의 사용자가 동시에 조회했을 때, 조회수가 100으로 오르지 않고, 10에 웃도는 모습을 확인할 수 있었습니다.
예상했던 것보다도 너무 낮은 성공률을 보여서, 조회수를 올리는 로직을 다시 살펴보았습니다.
- ClubStatisticsService
@Transactional
public void increaseVisitedClubCount(String clubToken) {
ClubStatistics clubStatistics = clubStatisticsReader.readClubStatistics(clubToken);
clubStatistics.increaseVisitedCount();
clubStatisticsStore.store(clubStatistics);
}- ClubStatisticsEntity
public void increaseVisitedCount() {
this.visitedCount++;
}위와 같이 Entity 내부에 필드를 1씩 증가시키는 코드가 있습니다.
JPA Dirty Checking
JPA는 dirty checking으로 엔티티의 상태 변경을 감지하고, 트랜잭션이 커밋될 때 UPDATE 쿼리를 날립니다. 이때 Race Condition이 발생할 수 있습니다.
Race Condition
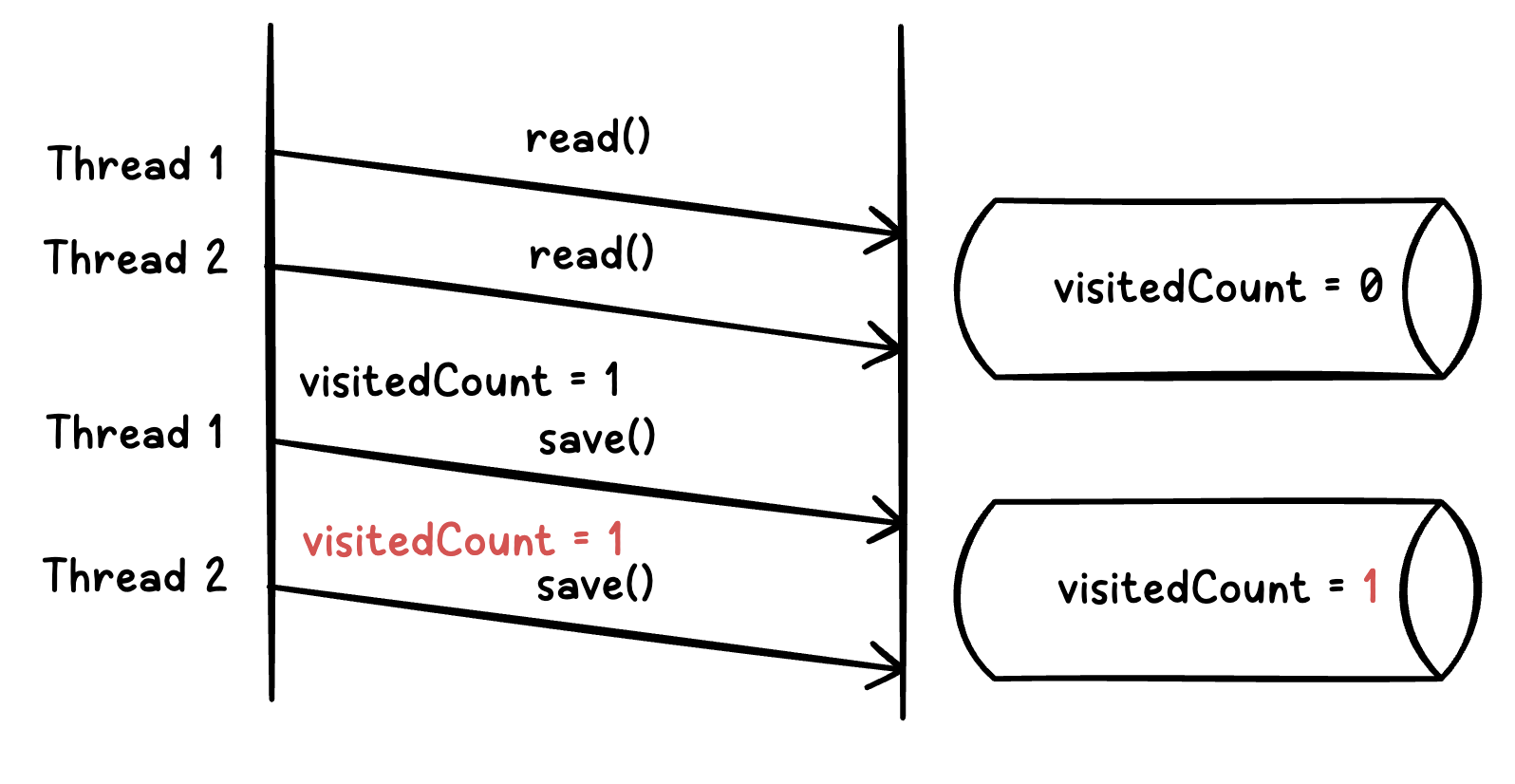
그림과 같이 Thread 1이 read()를 수행합니다. 이때 visitedCount 값은 0입니다. Thread 1이 visitedCount를 1 증가하여 DB에 반영하기 이전에, Thread 2가 read()를 수행합니다. 아직 visitedCount는 0입니다. 두 개의 스레드가 조회수를 올리고 싶었으나, 최종적으로 DB에 반영되는 값은 2가 아니라 1이 됩니다.
🧚 직접 Update Query 작성하기
JPA를 통한 업데이트를 할 때 락을 통해 동시성을 제어하지 않게 되면, 위와 같은 문제가 발생할 수 있습니다.
Update 쿼리를 직접 날려 간단하게 해결해보도록 하겠습니다. querydsl을 사용하여 DB의 row에 직접 +1을 수행합니다.
@Override
@Transactional
public void increaseClubVisitCount(String clubToken) {
queryFactory.update(clubStatistics)
.set(clubStatistics.visitedCount, clubStatistics.visitedCount.add(1))
.where(clubStatistics.club.clubToken.eq(clubToken))
.execute();
}영속성 컨텍스트에서 객체를 읽어와 값을 1 증가시키고 JPA의 Dirty Checking을 통해 업데이트하는 이전 방식과 다르게, DB의 해당 행(row)에 직접 +1 연산을 수행하기 때문에 자동으로 락이 걸리며 동시성 문제가 해소됩니다.

🔓 락을 걸어보자!
위의 방식에는 어떤 문제점이 있을까요? DB Connection Pool 소진, Deadlock, DB 부하 증가 등의 문제가 발생할 수 있습니다.
다만, 기존 프로젝트에서는 위와 같이 UPDATE 쿼리를 직접 작성하는 것으로 동시성 문제를 해결하기로 했습니다. 데이터 정합성이 거의 100% 지켜졌고, 하나의 동호회를 조회하는데 높은 트래픽이 몰릴 일이 적어 큰 문제점을 느끼지 못했기 때문입니다.
그래도 . . . 아쉬우니 여러 가지 종류의 락을 걸어보면서 동시성 문제를 조금 더 깊게 공부해보기로 했습니다.
🚨 락을 걸 때 주의할 점 - @Transactional
@Override
@Transactional
public void increaseVisitedClubCount(String clubToken) {
synchronized (this) {
increaseClubVisitCount(clubToken);
}
}
private void increaseClubVisitCount(String clubToken) {
ClubStatistics clubStatistics = clubStatisticsReader.readClubStatistics(clubToken);
clubStatistics.increaseVisitedCount();
clubStatisticsStore.store(clubStatistics);
}synchronized 키워드를 붙여봤습니다. 위 코드에서는 어떠한 문제가 있을까요?
트랜잭션 내부에서 락을 거는 행위는 주의해야 합니다. 아래와 같은 문제가 발생할 수 있습니다.
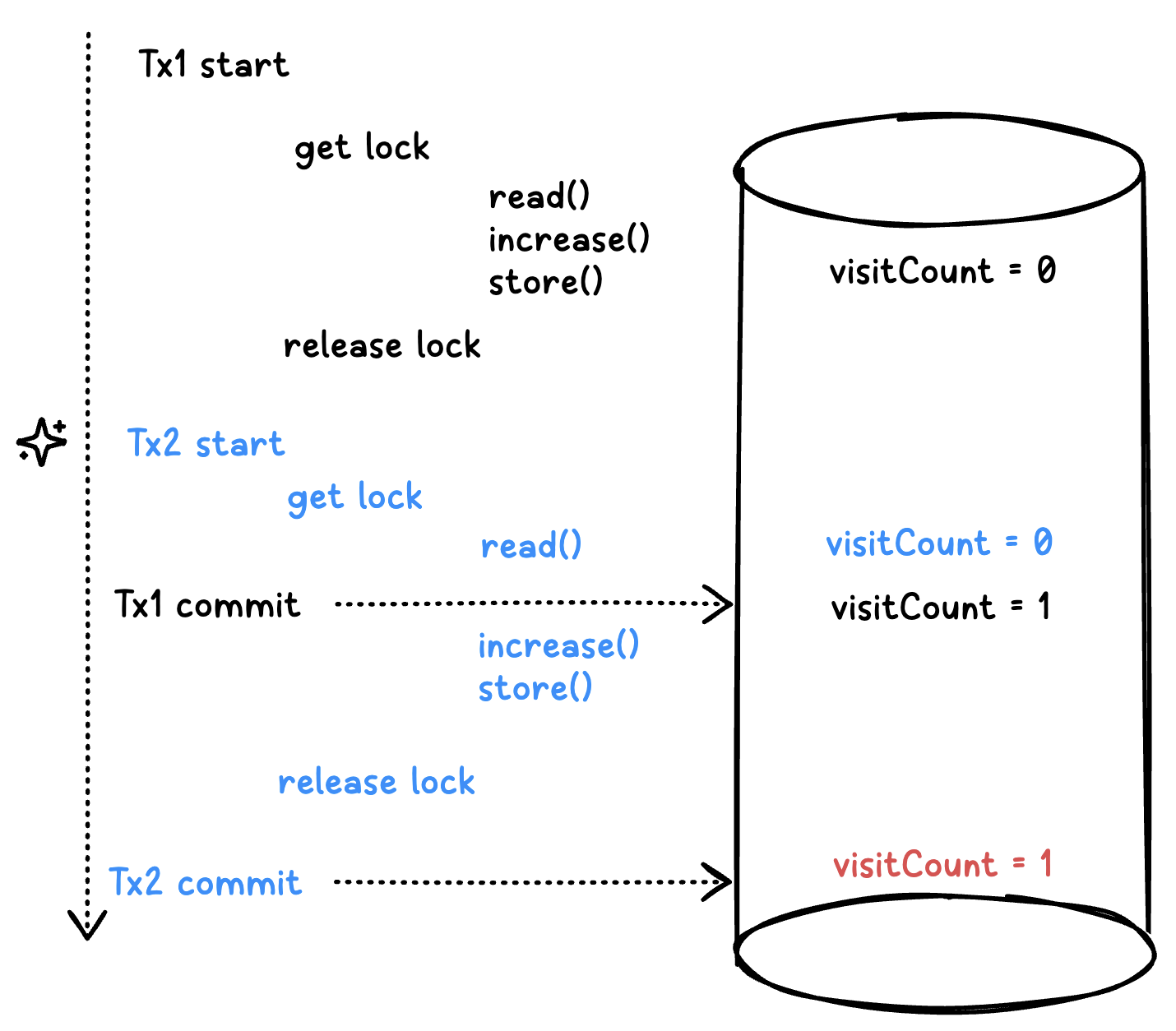
1번 요청이 작업을 다 수행한 다음 lock을 반납했습니다. 그러나 아직 트랜잭션이 커밋되기 이전이라고 가정해보겠습니다.
그 사이에 2번 요청은 lock을 획득하고, visitCount를 읽습니다. 이때 읽은 visitCount값은 1이 아닌 0입니다.
1번 요청이 +1 증가시킨 조회수가 아직 DB에 반영되기 이전이기 때문입니다. 그런데 두 번째 요청이 1번 tx가 커밋되기 이전에 lock을 획득해버렸고, 이때 읽어들인 조회수는 아직 0입니다.
이는 트랜잭션 내부에 락을 걸었기 때문인데요, 커밋하지 않은 데이터를 다른 곳에서 조회하게 되면 데이터 정합성에 큰 문제가 발생합니다.
어떻게 해결할 수 있을까요?
락 내부에 @Transactional을 걸면 위의 문제가 해결됩니다!
@Override
public void increaseVisitedClubCount(String clubToken) {
// 1. 락을 건다.
synchronized (this) {
increaseClubVisitCount(clubToken);
}
}
// 2. 트랜잭션이 시작된다.
@Transactional
public void increaseClubVisitCount(String clubToken) {
ClubStatistics clubStatistics = clubStatisticsReader.readClubStatistics(clubToken);
clubStatistics.increaseVisitedCount();
clubStatisticsStore.store(clubStatistics);
}앞선 코드와 다르게, 락을 획득하고 나서 트랜잭션이 시작됩니다. 작업을 수행한 다음, 커밋까지 완료되어야 락을 반납합니다.
즉, 커밋되지 않은 공유 자원의 경우 아직 락이 해제되지 않았기 때문에, 다른 스레드가 더이상 접근하지 못합니다.
이를 통해 항상 커밋된 내용을 읽는 것을 보장할 수 있습니다.
🔎 요약
락과 @Transactional을 함께 사용할 때는 데이터 정합성을 위해 락 내부에서 트랜잭션이 시작되도록 합니다.
😕 Synchronized의 문제점
다만, Synchronized 키워드는 한 프로세스 내에서만 스레드의 접근 제한을 보장합니다. 따라서 여러 프로세스에서 데이터 정합성을 보장해주지 않습니다. 또한 자바 애플리케이션에 종속되기 때문에, 여러 서버로 확장되었을 때 사용하기 어렵습니다.
🔏 비관적 락
비관적락은 mysql에서 제공하는 레코드락입니다.
# user1 요청
start transaction;
select * from clubStatistics where clubToken = 1 for update; # visitCount = 0
/*
user 1 조회수 증가
- update visitCount # visitCount = 1
- insert club_statistics
*/
commit; # 커밋이 되는 순간, 락이 해제된다.ㅡㅡㅡㅡClubStatistics 테이블에서 조회수를 조회할 때 락을 걸면, 커밋되기 전까지 읽거나 쓸 수 없습니다. 쿼리의 끝에 for update를 붙여 해당하는 레코드에 락을 걸 수 있습니다. 레코드락은 중첩해서 걸 수 없으며, 락이 해제될 때까지 기다려야 합니다. 커밋이 되면, 락이 해제됩니다.
# user2 요청
start transaction;
select * from clubStatistics where clubtoken = 1 for update; # 락이 해제되기를 기다림, 락을 건다.
/*
user 2 조회수 증가
- update visitCount # visitCount = 2
- insert club_statistics
*/
commit;user2는 락이 해제될 때까지 기다렸다가, user1의 요청이 커밋되는 순간 락을 획득합니다. 이때 읽어들인 visitCount는 1입니다.
아래와 같이 어노테이션을 통해 비관적락을 구현할 수 있습니다. 조회 시 락을 걸어, Transaction 범위 내에서 해당 레코드에 대한 접근 제한이 보장됩니다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
ClubStatistics findByClubClubToken(String clubToken);다만, 비관적 락의 경우 mysql에서 제공하는 락으로 DB에 병목이 생기면, 처리량에 문제가 생길 수 있습니다. 즉, DB에 부하가 생기며 성능 이슈가 발생할 가능성이 있습니다.
🧣 레디스락
레디스락은 분산락입니다. 즉, 분산 환경에서도 안정적으로 락을 걸고 해제할 수 있습니다. Java의 Redis client인 Redisson을 사용했습니다. Redisson은 Lock, Semaphore, CountDownLatch 등의 잠금 및 동기화 장치를 제공합니다.
기본적으로 Redis는 인메모리 DB이기에 더 빠르게 락을 획득 및 해제할 수 있습니다. 분산락에 대한 부하를 Redis 서버가 감당하기 때문에, 앞서 살펴봤던 DB 성능 문제를 방지할 수 있습니다.
build.gradle에 아래와 같이 의존성을 추가합니다.
- build.gradle
implementation 'org.redisson:redisson-spring-boot-starter:3.27.0'- Executor
package org.badminton.infrastructure.statistics;
@Component
@Slf4j
@RequiredArgsConstructor
public class DistributeLockProcessorExecutorImpl implements DistributedLockProcessor {
private final RedissonClient redissonClient;
@Override
public void execute(String lockName, long waitMilliSecond, long releaseMilliSecond, Runnable runnable) {
RLock lock = redissonClient.getLock(lockName);
try {
boolean isLocked = lock.tryLock(waitMilliSecond, releaseMilliSecond, TimeUnit.MILLISECONDS);
if (!isLocked) {
throw new IllegalArgumentException("[" + lockName + "] lock 획득 실패");
}
runnable.run();
} catch (InterruptedException e) {
log.error(e.getMessage(), e);
throw new RuntimeException(e);
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}- ClubStatisticsService
@Override
public void increaseVisitedClubCount(String clubToken) {
String lockName = "CLUB_VISIT_LOCK_" + clubToken;
distributedLockProcessor.execute(lockName, 10000, 10000,
() -> increaseClubVisitCountWithNamedLock(clubToken)
);
}
@Transactional
public void increaseClubVisitCountWithNamedLock(String clubToken) {
ClubStatistics clubStatistics = clubStatisticsReader.readClubStatistics(clubToken);
clubStatistics.increaseVisitedCount();
clubStatisticsStore.store(clubStatistics);
}🕰️ 세 가지 락 비교
100개 데이터를 테스트한 결과, 아래와 같은 결과를 확인했습니다.
- 동시성 적용 X
- 0.322s (322.807ms)
- synchronized
- 1.144s (1143.671ms)
- 레디스락
- 1.21s (1206.73ms)
- mysql 락(비관적 락)
- 0.634s (634.514ms)
당연히 동시성을 고려하지 않았을 때, 락을 걸지 않아 가장 빨랐습니다. 다만, 세 가지 락이 보여준 시간이 예상 밖이었는데, mysql 락이 가장 빨랐고 레디스락이 가장 느렸습니다. 이는 추가적으로 알아보려고 합니다.
⛳️ 조회수와 동시성
동시성에서 중요한 건, "공유 자원인가? 공유 자원이 아닌가?"를 판단하는 것입니다. 만약 공유 자원이라면, 얼마나 공유되고 있는지를 고민해보아야 합니다. 조회수의 경우, 동시성의 경합 조건이 실제로는 훨씬 덜할 것이라고 예상됩니다.
또한 조회수는 엄격하게 가져갈 것이 아니기 때문에, "조회수를 올리는데 별도의 락까지 써야 할까?"라고 생각했습니다. 어쩌다가 한 번씩 실패하는 경우에는 감내할 수 있기 때문입니다.
따라서, 최종적으로 처음에 소개했던 UPDATE 쿼리를 직접 날리는 방식을 택하게 되었습니다.
🌳 마치며
프로젝트에서 조회수 기능을 구현하며 동시성 문제를 고민해본 내용을 담아봤습니다. 아주 간단할거라 생각했는데, 고민해볼 만한 부분이 많아 재미있게 구현할 수 있었습니다!
긴 글 읽어주셔서 감사합니다 😄
📘 참고자료
CountDownLatch - baeldung
ExecutorService - baeldung
비관적락 - baeldung
Redisson - baeldung
Distributed Locks with Redis
Transactional with synchronized doesn't work - stackoverflow

백엔드 공부하고 있는 학생인데 이 글이 되게 도움이 되었습니다! 좋은 글 감사해요!