[부하테스트, 성능 최적화] 부하테스트를 진행하고, 성능을 개선해보자.
개요
저는 걱정이 많은 성격입니다.

성격떄문인지 사이트를 운영하면서, 나중에 취업후 회사에서 "내가 만든 서버가 터지면 어쩌지?"하는 걱정이 항상 들었습니다
이 부분에 대해선 수치화된 결과가 필요하다 생각했습니다.
찾아보니 이를 해소하기 위해 "부하테스트"가 존재하더라고요?!
그래서 이번 포스팅은 성능 최적화 전, 후의 비교군을 두고 부하테스트를 진행한 과정을 기록해보겠습니다.
부하테스트 with Jmeter
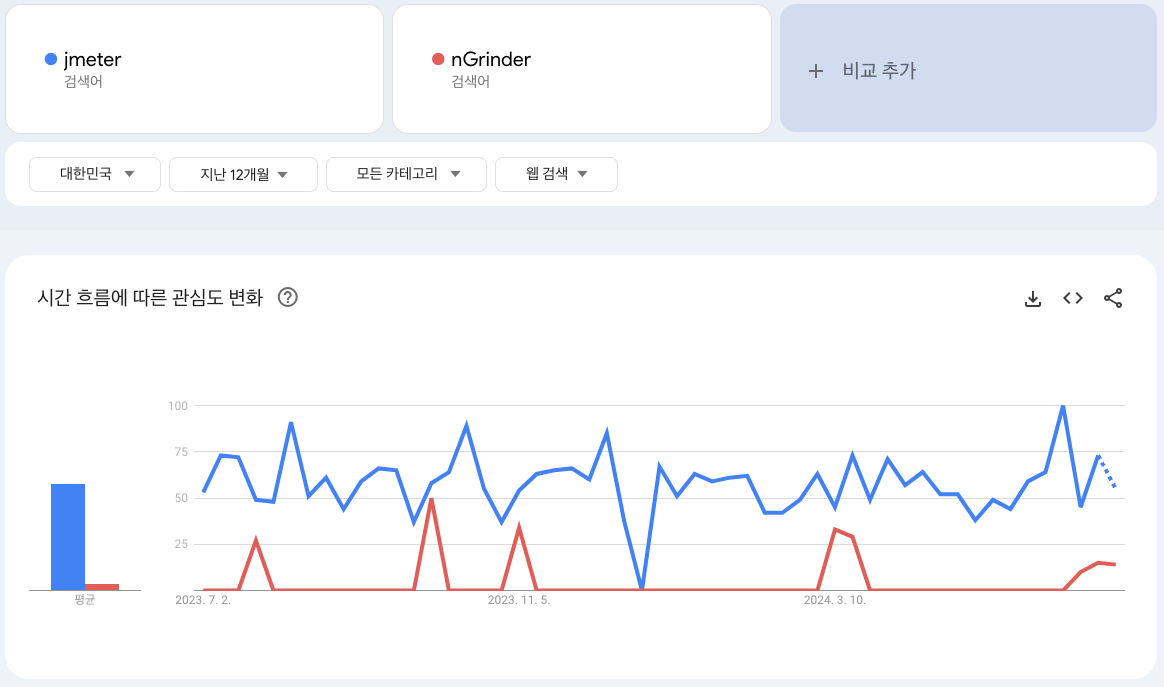
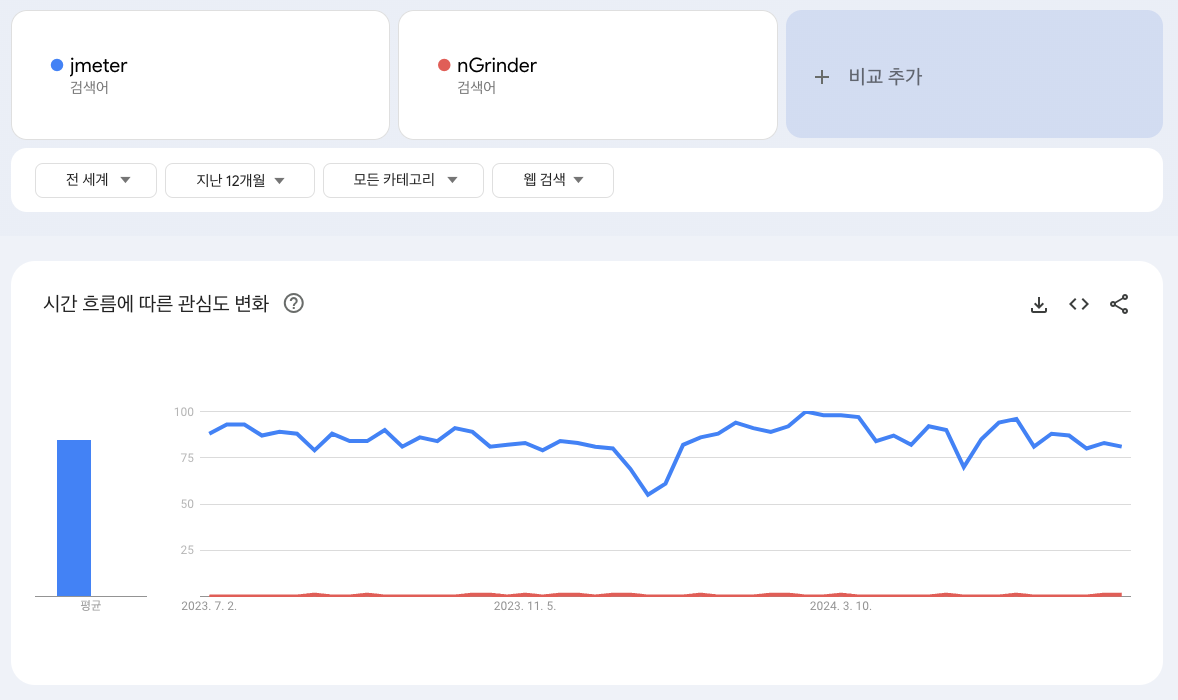
1. jmeter vs nGrinder
스프링 서버를 부하 테스트할 수 있는 도구로는 대표적으로 jmeter와 nGrinder가 있습니다.
둘 다 결국 테스트하기 위한 도구일 뿐, 어떤걸 사용해서든 올바른 테스트 해서 수치화하는게 더 중요하다 생각하였습니다. 그래서 저는 단순하게 "현재 사람들이 자주 사용하는 도구"를 선택하였습니다.
대한민국 기준
전 세계 기준
2. 테스트 조건
Test Condition은 다음과 같습니다.
- Local Server를 대상으로 진행.
- 제 로컬 pc 사양은 MacBook Air M2 RAM16GB입니다.
- 하나의 thread(user와 비슷한 개념)는 5개의 API를 실행합니다.
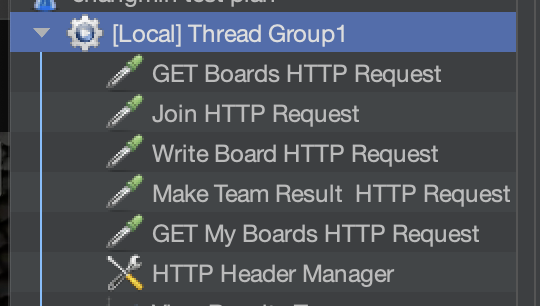
- Threads Properties는 다음과 같습니다.
- Number of Threads: 실행할 Thread의 수. 즉, 몇명의 사용자가 동시에 호출하는지 여부를 나타냅니다.
- Ramp-Up Period: 전체 thread가 전부 실행되는데까지 걸리는 시간을 나타냅니다.
예를 들어, Number of Threads가 5이고, Ramp-Up Period가 15초 일 경우에, 첫번쨰 thread가 수행된 후 다음 thread가 수행될떄까지 3초를 대기한다는 얘기입니다.
즉, 전체 5개의 thread가 15초동안 실행되기 위해, 3초마다 1개의 thread가 실행됩니다.- Loop Count는 각 Thread가 몇번씩 실행을 할 것인지를 나타냅니다.
- 또한 각 API 요청값을 적절히 설정해주었습니다.
예를 들어, 회원가입 API Body값의 username필터를 jmeter의 함수를 사용하여 랜덤값이 되도록 설정해두었습니다.
3. 왜 EC2 인스턴스가 아닌 Local Server를 대상으로 진행했는지?
찾아보니 정확한 부하테스트를 위해서 아래와 같은 환경이 권장됩니다.
테스트 하는 웹 어플리케이션 서버와 테스트를 돌리는 서버는 서로 달라야 합니다.
JMeter를 돌리는 서버와 웹 어플리케이션 서버가 같으면, 같은 메모리를 사용하기 때문에
정확한 값을 측정할 수 없습니다.
EC2 인스턴스 프리티어를 대상으로 부하테스트 -> 성능 최적화 -> 부하테스트를 진행해보았는데,
성능 최적화들을 적용해봐도 제 예상과는 다르게 성능 개선이 되지 않았습니다.
이에 대해서 인프런의 다음과 같은 답변이 적힌 글을 보았습니다.
프리티어 스펙이 너무 안좋아, 프리티어 기준으로는 유의미한 부하테스트를 기대하긴 어렵습니다.
위와 같은 이유로 EC2가 아닌 로컬 서버를 대상으로 진행하였으며, 성능 개선 차이 확인에 의의를 두었습니다.
3. 개선전 부하테스트 결과
부하테스트 진행 결과 다음과 같습니다. (앞으로 가장 평균적인 결과의 사진 하나만 올리겠습니다.)
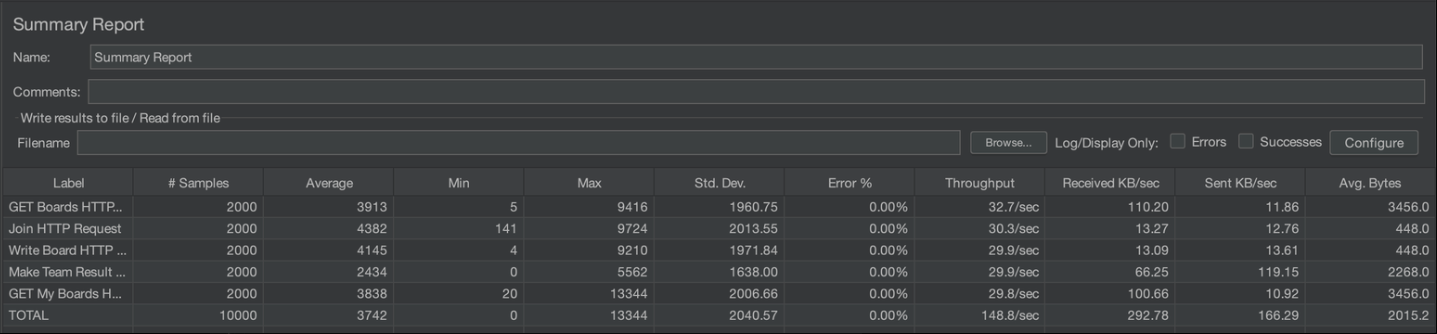
주로 볼 부분은 Average와 Std. Dev. 입니다.
- Average: 모든 요청에 대한 평균 응답 시간입니다.
- Std. Dev. (표준 편차): 응답 시간의 변동성을 나타냅니다. 개선 후 표준 편차가 낮아졌다면 성능이 더 안정적이 되었음을 나타냅니다.
- Throughput (처리량): 단위 시간당 처리된 요청 수입니다.
개선전 Average는 3600ms, 표준 편차는 2000ms의 수치가 나왔습니다.
성능 최적화 진행
성능 최적화를 위해 다음과 같은 과정을 거칠 예정입니다.
- OSIV off
- JVM 메모리 힙 설정
- query 최적화
- @Transactional(readonly = true) 적용
- DB Connection Fool 설정
- Redis 사용
1. OSIV OFF
1-1. OSIV란?
OSIV(Open Session In View)는 영속성 컨텍스트(Session)을 뷰 계층까지 연장하는 것을 의미합니다. 이는 기본적으로 영속성 컨텍스트가 HTTP 요청의 시작부터 끝까지 열려있어 뷰 계층에서도 지연 로딩을 사용할 수 있게 합니다.
이는 편리한 데이터베이스 액세스를 제공하지만, 지연 로딩 문제를 일으킬 수 있습니다.
또한 OSIV를 사용하면 데이터베이스 연결이 요청의 전 기간 동안 유지되므로(=긴 트랜잭션 유지), 데이터베이스 연결이 오래 유지됩니다. 이는 특히 긴 요청 처리 시간이나 많은 동시 요청이 있는 시스템에서는 데이터베이스 연결 고갈 문제를 초래할 수 있습니다.
1-2. OSIV 끄기
application.properties에 아래 옵션을 추가합니다.
spring.jpa.open-in-view=false이 설정으로 인해, 세션이 뷰 렌더링 시점까지 열려 있지 않게 되어서 Lazy Loading 문제를 일으킬 수 있습니다. 이 문제는 데이터베이스 세션이 이미 닫힌 상태에서 Lazy 로딩을 시도하기 때문에 발생합니다.
이 문제를 해결하는 방법 중 하나는 서비스 레이어에서 필요한 데이터를 미리 로딩하는 것입니다. 이를 위해 엔티티를 페치 조인(fetch join) 또는 DTO 변환 시 필요한 데이터를 명시적으로 로딩할 수 있습니다.
Repository에서 사용자 정보를 페치 조인하도록 수정해야합니다.
페치 조인하기 위해서는 @EntityGraph, Query Fetch Join두 방법이 있습니다.
@EntityGraph = left join
Query Fetch Join = inner join
저의 상황에서는 inner join이기 떄문에, Query Fetch Join을 사용하였습니다.
BoardRepository
package carrotbat410.lol.repository;
import carrotbat410.lol.entity.Board;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
public interface BoardRepository extends JpaRepository<Board, Long> {
@Query("SELECT b FROM Board b JOIN FETCH b.user u WHERE u.id = :userId")
Page<Board> findByUserId(@Param("userId") Long userId, Pageable pageable);
@Query("SELECT b FROM Board b JOIN FETCH b.user")
Page<Board> findAll(Pageable pageable);
}BoardService는 수정할 필요없습니다.
public Page<BoardDTO> getMyBoards(Long userId, Pageable pageable) {
Page<Board> boardsPage = boardRepository.findByUserId(userId, pageable);
return boardsPage.map(board -> new BoardDTO(
board.getId(),
board.getTitle(),
board.getContent(),
board.getUser().getId(),
board.getUser().getUsername()
));
}2. jvm의 힙 메모리 크기 설정
2-0. 효과는 조금 부족했다.
원인은 모르겠지만, jvm 힙 메모리 크기 설정에 의한 성능 개선 효과는 미미했습니다.
나중에 좋은 스펙의 EC2 인스턴스를 빌려 테스트를 진행하게 된다면, 그떄 다시 시도 및 추가 공부와 함께 내용을 업데이트하겠습니다.
2-1. jvm
Java 애플리케이션을 실행할 때 JVM (Java Virtual Machine)의 힙 메모리 크기를 설정하지 않으면 기본값이 사용됩니다.
기본 힙 메모리 크기는 Java 버전과 사용 중인 JVM의 종류, 운영 체제, 그리고 시스템의 물리적 메모리 크기에 따라 달라질 수 있습니다. 일반적으로 다음과 같은 기본값이 사용됩니다.
초기 힙 크기 (-Xms):
JDK 8 이하: 약 1/64의 물리적 메모리 크기 또는 1MB 중 더 큰 값
JDK 9 이상: 약 1/64의 물리적 메모리 크기 또는 2MB 중 더 큰 값
최대 힙 크기 (-Xmx):
JDK 8 이하: 약 1/4의 물리적 메모리 크기
JDK 9 이상: 약 1/4의 물리적 메모리 크기 또는 25%의 물리적 메모리 크기 중 더 작은 값
출처: HotSpot Virtual Machine Garbage Collection Tuning Guide - Ergonomics
2-2. 힙 메모리 크기 설정
-Xms와 -Xmx 옵션을 사용하여 힙 메모리의 초기 크기와 최대 크기를 설정할 수 있습니다. 이 옵션들이 없으면 JVM은 기본 힙 크기 설정을 사용합니다.
spring actuator를 사용하여 현재 jvm의 초기의 메모리를 확인합니다.
/actuator/metrics/jvm.memory.committed: 211.156992mb
/actuator/metrics/jvm.memory.max: 5620.367357mb
현재 16GB 메모리의 맥북을 사용하고 있는데, 위 설명과 비슷한 수치가 나왔네요!
그 후, -Xms4096m -Xmx4096m 옵션을 통해 초기, 최대 힙 메모리 크기를 설정해 서버를 실행해줍니다.
저는 최대 힙 크기는 이미 충분해서, 초기 힙 크기만 늘려줬습니다.
java -jar -Xms4096m -Dspring.profiles.active=local lol-0.0.1-SNAPSHOT.jar
Xms 는 초기힙사이즈, Xmx는 최대힙사이즈입니다.주의할 점은 어플리케이션에서 필요로하는 메모리가 증가할 때마다 최대 힙사이즈까지 점진적으로 힙 사이즈를 늘리게 되는데 이 과정에서 애플리케이션이 일시적으로 멈추는 병목 현상(Stop the World Event)이 발생할 수 있으므로 메모리가 넉넉하다면 처음부터 -Xms 값을 -Xmx와 동일하게 설정하는 방법을 추천하기도 합니다.
설정 후, 다시 actuator를 통해서 수정된 값을 확인합니다.
/actuator/metrics/jvm.memory.committed: 4413.718528mb
/actuator/metrics/jvm.memory.max: 5620.367357mb
jvm 메모리 힙 설정은 끝났습니다.
3. 쿼리 최적화
보통 CRUD중, 조회 동작에서 비효율적인 쿼리가 발생합니다.
테스트하는 5개의 API들이 각각 어떤 쿼리가 실행되는지 확인하기 위해 application.properties에 다음을 추가해줍니다.
spring.jpa.show-sql = true
spring.jpa.properties.hibernate.format_sql= true3-1. Read Query 최적화
GET /my/boards API 실행시, 기존 실행되던 쿼리는 다음과 같았습니다.
Hibernate:
select
b1_0.board_id,
b1_0.board_category,
b1_0.content,
b1_0.created_at,
b1_0.title,
b1_0.updated_at,
u1_0.user_id,
u1_0.created_at,
u1_0.password,
u1_0.role,
u1_0.updated_at,
u1_0.username
from
boards b1_0
left join
users u1_0
on u1_0.user_id=b1_0.user_id
where
u1_0.user_id=?
limit
?, ?
Hibernate:
select
count(b1_0.board_id)
from
boards b1_0
left join
users u1_0
on u1_0.user_id=b1_0.user_id
where
u1_0.user_id=?개선 할 부분은 다음과 같습니다.
- 페이징을 위한 count 쿼리에 join이 있을 필요가 없습니다.
- 내가 쓴 글이므로, 작성자에 대한 정보를 가져오는 join은 필요 없습니다.
내가 쓴 게시글을 조회하는 쿼리이므로, 굳이 나의 대한 정보를 여기서 한번 더 join으로 가져올 필요는 없을 것 같습니다.
필요시에는 닉네임, 아이디 정도는 토큰으로 저장하고 있기 떄문에, 필요시 토큰에서 꺼내 쓰면 됩니다.
개선 전 Repository 코드
public interface BoardRepository extends JpaRepository<Board, Long> {
Page<Board> findByUserId(Long userId, Pageable pageable);
}개선 후 Repository 코드
public interface BoardRepository extends JpaRepository<Board, Long> {
@Query(value = "select b from Board b where b.user.id = :userId",
countQuery = "select count(b) from Board b where b.user.id = :userId")
Page<Board> findByUserId(Long userId, Pageable pageable);
}lazy loading + OSIV off설정에 의한 "Error: no session"을 방지하기 위해, 서비스 코드도 수정합니다.
Error: no session 관련 글
https://byungil.tistory.com/241#Post%20-%3E%20DTO%20%EB%B3%80%ED%99%98%EC%9D%84%20%EC%84%9C%EB%B9%84%EC%8A%A4%EC%97%90%EC%84%9C%20%ED%95%98%EC%9E%90.-1
https://dingdingmin-back-end-developer.tistory.com/entry/SpringBoot-Data-Jpa-5-Fetch-Join
수정 된 Service 코드
public Page<BoardDTO> getMyBoards(Long userId, Pageable pageable) {
Page<Board> boardsPage = boardRepository.findByUserId(userId, pageable);
return boardsPage.map(board -> new BoardDTO(
board.getId(),
board.getTitle(),
board.getContent(),
// board.getUser().getId(),
// board.getUser().getUsername()
userId,
null //필요시 토큰에서 꺼내와 값을 넣어줍시다.
));
}3-2. Write Query 최적화
POST /boards API 의 서비스 코드
public void writeBoard(Long userId, WriteBoardRequestDTO request) {
User user = userRepository.findById(userId).orElseThrow(()-> new AccessDeniedException("존재하지 않는 유저입니다. 재 로그인후 다시 요청해주세요."));
Board newBoard = new Board(
null,
request.getTitle(),
request.getContent(),
request.getBoardCategory(),
user
);
boardRepository.save(newBoard);
}기존 실행되던 쿼리는 다음과 같았습니다.
Hibernate:
select
u1_0.user_id,
u1_0.created_at,
u1_0.password,
u1_0.role,
u1_0.updated_at,
u1_0.username
from
users u1_0
where
u1_0.user_id=?
Hibernate:
insert
into
boards
(board_category, content, created_at, title, updated_at, user_id)
values
(?, ?, ?, ?, ?, ?)JPA는 엔티티를 저장할 때 객체와 연관관계를 만들어주다 보니, 뤄져서 연관관계의 엔티티인 user를 조회하기 위한 select + insert쿼리가 수행되었습니다.
이를 개선하기 위해 findById()가 아닌 getReferenceById()를 사용하여 insert쿼리만 수행되도록 수정하겠습니다.
수정된 service 코드
public void writeBoard(Long userId, WriteBoardRequestDTO request) {
User user = userRepository.getReferenceById(userId);
Board newBoard = new Board(null, request.getTitle(), request.getContent(), request.getBoardCategory(), user);
boardRepository.save(newBoard);
}수정후 실행 된 쿼리
Hibernate:
insert
into
boards
(board_category, content, created_at, title, updated_at, user_id)
values
(?, ?, ?, ?, ?, ?)select문이 제거된 것을 볼 수 있습니다.
getReferenceById 주의 사항
getReferenceById 메서드는 실제로 데이터베이스에서 엔티티를 가져오는 대신, 프록시 객체를 반환합니다. 프록시 객체는 나중에 실제 데이터에 접근할 때(필드에 접근할 때 등) 데이터베이스를 조회합니다. 따라서, 프록시 객체를 사용하려고 할 때 LazyInitializationException이 발생할 수 있습니다.
특히 트랜잭션 범위 밖에서 프록시 객체에 접근할 경우 문제가 됩니다.위 단점을 충분히 이해하고 적절한 상황에서 사용하는 것이 중요하며, 어쩌면 코드의 안정성과 예외 처리를 보장하기 위해서 findById를 사용하여 엔티티의 존재를 명확하게 확인하는 것이 더 바람직할 수 있습니다.
이런식으로 최적화할 수 있는 api의 쿼리들은 최적화를 진행하였습니다.
4. @Transactional(readonly = true) 적용
Spring에서 @Transactional 어노테이션을 사용할 수 있는데 트랜잭션을 readOnly = true로 설정해 주면 읽기 전용 모드로 변경할 수 있습니다.
트랜잭션을 읽기 전용으로 설정하면 해당 메서드가 데이터를 읽기만 한다는 것을 DB에 알려줌으로써 쿼리 및 캐싱을 최적화할 수 있다.
적용
@Service
@Transactional(readOnly = true)
public class BoardService {
@Autowired
BoardRepository boardRepository;
@Autowired
UserRepository userRepository;
public Page<BoardDTO> getMyBoards(Long userId, Pageable pageable) {
Page<Board> boardsPage = boardRepository.findByUserId(userId, pageable);
return boardsPage.map(board -> new BoardDTO(
board.getId(),
board.getTitle(),
board.getContent(),
userId,
null
));
}
public Page<BoardDTO> getAllBoards(Pageable pageable) {
Page<Board> boardsPage = boardRepository.findAll(pageable);
return boardsPage.map(board -> new BoardDTO(
board.getId(),
board.getTitle(),
board.getContent(),
board.getUser().getId(),
board.getUser().getUsername()
));
}
@Transactional
public void writeBoard(Long userId, WriteBoardRequestDTO request) {
User user = userRepository.getReferenceById(userId);
Board newBoard = new Board(null, request.getTitle(), request.getContent(), request.getBoardCategory(), user);
boardRepository.save(newBoard);
}
}전체적으로 @Transactional(readOnly = true)를 적용시켰고,
Read를 제외한 Create, Update, Delete에 대한 서비스 메서드에만 @Transactional을 적용해주었습니다. (@Transactional readOnly 기본값 = false)
주의사항
readOnly에서도 알 수 있듯이 읽기 전용으로 변경하는 것이기 때문에 데이터를 수정하는 서비스에 적용하면 안됩니다.
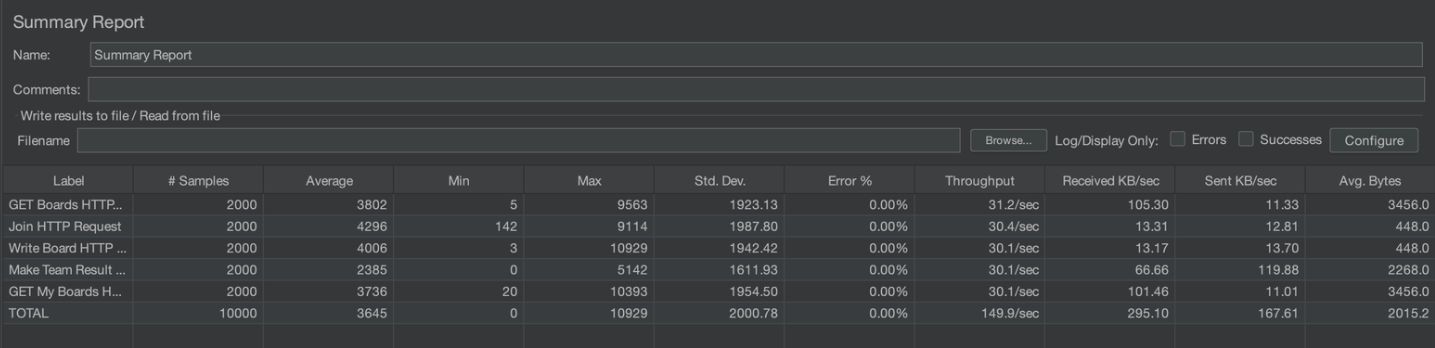
중간 점검 부하테스트 결과
개선 전
개선 후
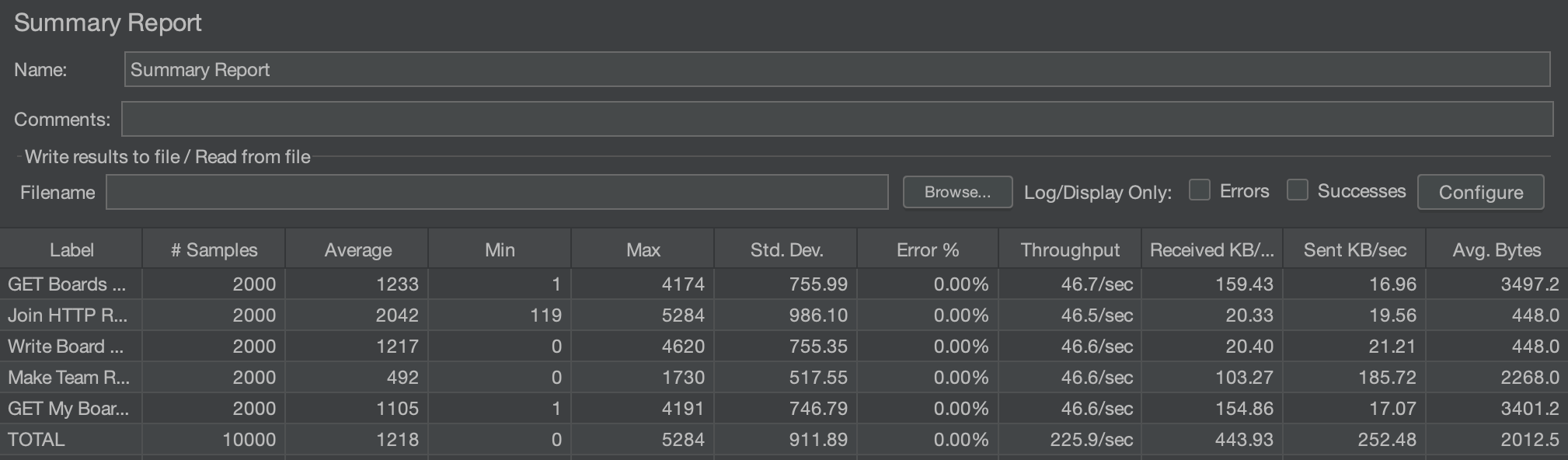
개선 비율 = (이전 속도 - 새 속도) / 이전속도 x 100 개산법으로 개선 비율을 구했습니다.
Average는 약3600ms -> 1200ms으로 약 66.6%가 개선되었습니다.
Std. Dev.(표준 편차)는 2000ms -> 900ms으로 55%가 개선되었습니다.

5. DB Connection Fool 설정
5-1. DB Connection Pool 설정 공식
별다른 설정을 안하면, Connection Pool max size 기본값은 10 입니다.
HikariCP github페이지에 적혀있는 공식을 따라 커넥션 풀을 늘렸습니다.

core_count: 저의 맥북 Air m2 core 수는 8개 입니다.
effective_spindle_count: effective_spindle_count이란 회전하는 디스크의 수.
하나의 spindel은 DB가 관리할 수 있는 동시 I/O 요청의 개수로 볼 수 있으며 이를 토대로 값을 보정해줍니다. 저의 맥북 하드 디스크는 1개 입니다.
즉, 저의 권장 DB Connection Pool size는 아래와 같습니다.
(8 X 2) + 1 = 17
application.properties에 다음을 추가해줍니다.
spring.datasource.hikari.maximum-pool-size=17
#디폴트값은 maximum-pool-size와 동일하게 설정됩니다.
#spring.datasource.hikari.minimum-idle=17 # 커넥션 풀의 최소 유휴 커넥션 수.
#minimum-idle을 설정하지 않으면 minimum-idle = maximum-pool-size 이기 떄문에, idle-timeout을 설정하는 의미가 없습니다.
#spring.datasource.hikari.idle-timeout=30000 # 유휴 커넥션 최대 유지 시간.6. Redis 사용
같은조건으로 게시글 조회시 7초간 유지되는 캐싱 데이터를 제공하기 위해, Redis를 사용하였습니다.
Redis는 기본적으로 Redis Repository, Redis Template 두가지 방식이 있습니다.
저는 spring data jpa처럼 사용하는 방식인 Redis Repository방식을 사용했습니다.
6-1. Mac에 Redis 설치
아래 명령어를 통해 Redis를 설치합니다.
$ brew install redis
$ brew services start redis
아래 명령어를 통해 redis에 접속할 수 있습니다.
$ redis-cli6-2. 의존성 추가
build.gradle파일에 Redis 의존성을 추가합니다.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.springframework.boot:spring-boot-starter-cache'6-3. Redis 설정
application.properties
spring.cache.type=redis
spring.redis.host=localhost
spring.redis.port=6379RedisConfig 클래스
package carrotbat410.lol.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.repository.configuration.EnableRedisRepositories;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
@EnableRedisRepositories
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return template;
}
}Board Entity에 대응하는 BoardCache 객체를 만들어주었습니다.
package carrotbat410.lol.entity.cache;
import carrotbat410.lol.dto.board.BoardDTO;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import org.springframework.data.annotation.Id;
import org.springframework.data.redis.core.RedisHash;
import org.springframework.data.redis.core.TimeToLive;
import org.springframework.data.redis.core.index.Indexed;
import java.io.Serializable;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.TimeUnit;
@ToString
@RedisHash("BoardCache")
@Getter
@Setter
public class BoardCache implements Serializable {
@Id
private String id;
@Indexed
private List<BoardDTO> boards;
private int pageNumber;
private int pageSize;
private long totalElements;
@TimeToLive(unit = TimeUnit.SECONDS)
private Long expiration;
public BoardCache(String id, List<BoardDTO> boards, int pageNumber, int pageSize, long totalElements, Long expiration) {
this.id = id;
this.boards = (boards != null) ? boards : Collections.emptyList();
this.pageNumber = pageNumber;
this.pageSize = pageSize;
this.totalElements = totalElements;
this.expiration = expiration;
}
}RedisRepository를 만들어줍니다.
package carrotbat410.lol.repository;
import carrotbat410.lol.entity.cache.BoardCache;
import org.springframework.data.repository.CrudRepository;
public interface BoardRedisRepository extends CrudRepository<BoardCache, String> {
}
BoardService에서 다음과 같이 RedisRepository를 사용하여 캐시를 저장, 가져오면 됩니다.
package carrotbat410.lol.service;
import carrotbat410.lol.dto.board.BoardDTO;
import carrotbat410.lol.dto.board.WriteBoardRequestDTO;
import carrotbat410.lol.entity.Board;
import carrotbat410.lol.entity.User;
import carrotbat410.lol.entity.cache.BoardCache;
import carrotbat410.lol.repository.BoardRedisRepository;
import carrotbat410.lol.repository.BoardRepository;
import carrotbat410.lol.repository.UserRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageImpl;
import org.springframework.data.domain.Pageable;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
@Service
@Transactional(readOnly = true)
public class BoardService {
@Autowired
BoardRepository boardRepository;
@Autowired
UserRepository userRepository;
@Autowired
BoardRedisRepository boardCacheRepository;
private static final Long CACHE_TTL = 7L; // 10초 TTL 설정
...
public Page<BoardDTO> getAllBoards(Pageable pageable) {
String cacheKey = "allBoards_" + pageable.getPageNumber() + "_" + pageable.getPageSize();
Optional<BoardCache> cachedResult = boardCacheRepository.findById(cacheKey);
if (cachedResult.isPresent()) {
BoardCache cache = cachedResult.get();
return new PageImpl<>(cache.getBoards(), pageable, cache.getTotalElements());
} else {
Page<Board> boardsPage = boardRepository.findAll(pageable);
List<BoardDTO> boardDTOs = boardsPage.stream().map(board -> new BoardDTO(
board.getId(),
board.getTitle(),
board.getContent(),
board.getUser().getId(),
board.getUser().getUsername()
)).collect(Collectors.toList());
BoardCache boardCache = new BoardCache(cacheKey, boardDTOs, pageable.getPageNumber(), pageable.getPageSize(), boardsPage.getTotalElements(), CACHE_TTL);
boardCacheRepository.save(boardCache);
return boardsPage.map(board -> new BoardDTO(
board.getId(),
board.getTitle(),
board.getContent(),
board.getUser().getId(),
board.getUser().getUsername()
));
}
}
@Transactional
public void writeBoard(Long userId, WriteBoardRequestDTO request) {
User user = userRepository.getReferenceById(userId);
Board newBoard = new Board(null, request.getTitle(), request.getContent(), request.getBoardCategory(), user);
boardRepository.save(newBoard);
// 캐시 무효화
// boardCacheRepository.deleteAll();
}
}
이제 해당 API에 요청을 하고, redis서버에 캐싱데이터가 제대로 저장되었는지 확인합니다.
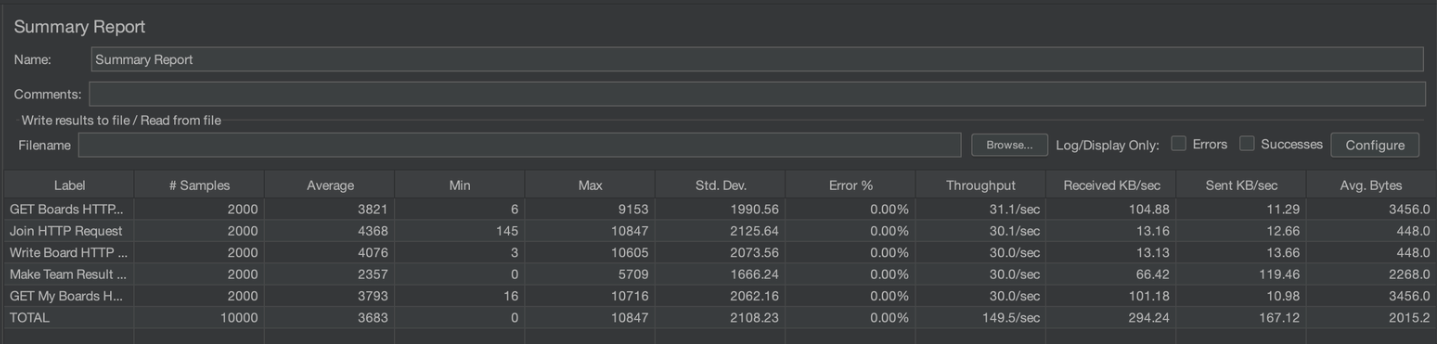
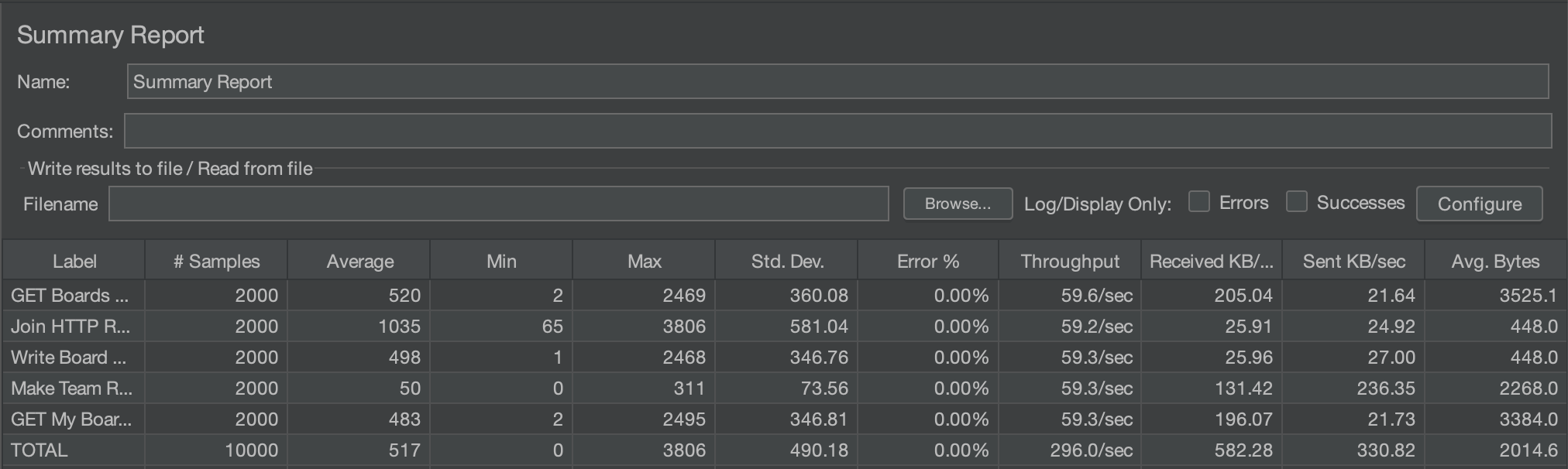
최종 부하 테스트 결과
마무리
정리하자면 다음과 같습니다.
개선 결과
평균 응답 속도: 3600ms -> 520ms으로 85.5%가 개선되었습니다.
Std. Dev.(표준 편차): 2000ms -> 490ms으로 75.5%가 개선되었습니다.
효과가 미미했던 것들
- JVM 메모리 힙 설정
- 초기 메모리힙 크기: 기본값 / 1024mb / 4096mb 으로 설정 변경해보았지만 큰 차이가 없었습니다.
추후 성능 최적화를 위해 고려할 것들
- DB Index 설정
- Load Balancing
아쉬운 점
- 테스트 환경과 서버 환경이 분리가 되지 않은점.
- 로컬 환경이다보니, 인스턴스를 늘려 로드밸런싱을 적용하기 애매했던 부분.
그렇지만 API 성능이 확실히 개선되었음을 확인할 수 있다는 것에 의미가 있었으며, 결과가 눈에 보이니 즐거운 과정이였습니다.
이번 포스팅은 아쉬웠던 점 + 내용 업데이트는 급한 불(=취업, 롤 내전 도우미 사이트 프론트엔드 코드 리팩토링, 기존 Next.JS -> spring Server로 Migration)부터 끈 후, 잊지 않고 업데이트 할 예정입니다.!
틀린 부분이 있다면 지적해주시면 감사하겠습니다.
긴 글 읽어주셔서 감사합니다.
참고 자료
#부하테스트
https://0soo.tistory.com/220
https://mindybughunter.com/성능테스트-1편-성능-테스트를-통한-api-서버-성능-평가/
https://www.inflearn.com/chats/1228661/%EB%B6%80%ED%95%98%ED%85%8C%EC%8A%A4%ED%8A%B8%EB%8A%94-%EB%B0%B0%ED%8F%AC-%ED%99%98%EA%B2%BD%EC%97%90%EC%84%9C-%ED%95%98%EB%A0%A4%EB%A9%B4-%EC%96%B4%EB%96%BB%EA%B2%8C-%ED%95%B4%EB%83%90%ED%95%98%EB%82%98%EC%9A%94#jvm
https://docs.oracle.com/en/java/javase/12/gctuning/ergonomics.html#GUID-DA88B6A6-AF89-4423-95A6-BBCBD9FAE781
https://blog.naver.com/kbh3983/220989675046
https://findmypiece.tistory.com/236#OSIV
https://byungil.tistory.com/241#Post%20-%3E%20DTO%20%EB%B3%80%ED%99%98%EC%9D%84%20%EC%84%9C%EB%B9%84%EC%8A%A4%EC%97%90%EC%84%9C%20%ED%95%98%EC%9E%90.-1
https://dingdingmin-back-end-developer.tistory.com/entry/SpringBoot-Data-Jpa-5-Fetch-Join#@Transactional(readOnly = true)
https://velog.io/@jhbae0420/TransactionalreadOnly-true%EB%A5%BC-%EC%82%AC%EC%9A%A9%ED%95%98%EB%8A%94-%EC%9D%B4%EC%9C%A0%EC%99%80-%EC%A3%BC%EC%9D%98%ED%95%A0%EC%A0%90#DB Connection Fool
https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
https://velog.io/@gale4739/%EC%BB%A4%EB%84%A5%EC%85%98%EA%B3%BC-%EC%BB%A4%EB%84%A5%EC%85%98-%ED%92%80Feat.-ThreadPool-HikariCP#Redis
https://docs.spring.io/spring-data/redis/reference/repositories.html
https://wlswoo.tistory.com/44
https://bcp0109.tistory.com/386
