Protocol
통신 프로토콜 또는 통신 규약은 컴퓨터나 원거리 통신 장비 사이에서 메시지를 주고 받는 양식과 규칙의 체계이다. 즉 통신 규약 및 약속이다.
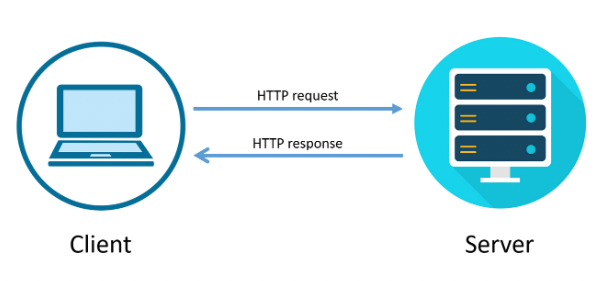
Request/Response의 기반이 되는 HTTP도 protocol의 한 종류이다.
HTTP
HTTP는 HyperText Transfer Protocol의 약자로 W3 상에서 정보를 주고받을 수 있는 프로토콜이다. 주로 HTML 문서를 주고받는 데에 쓰인다.
웹 서버랑 브라우저 간의 통신을 위한 규약으로 대략 헤더, 바디의 구조를 띄고 있다. 쉽게 말해 웹 서버와 화면을 보고 있는 클라이언트(브라우저) 간의 티키타카를 위해 규약을 정해놓고 사용한다~ 생각하면 된다. 뒤에 설명할 Request와 Response에서 사용되는 기본 프로토콜이다.
HTTP 특징

1. 서버, 클라이언트 구조와 TCP/IP 기반 프로토콜
- HTTP 메시지는 HTTP 서버와 HTTP 클라이언트에 의해 해석되고, TCP/IP 기반 응용 프로토콜이다.
2. 무상태 프로토콜 (Stateless)
- HTTP는 연결 상태를 유지하지 않는 비연결성 프로토콜이다. '연결 상태를 유지하지 않는다' 는 말은 내가 웹 서버에서 기능을 실행했을 때 실행된 내용이 유지되지 않는다는 얘기다. 더 쉽게 설명하면 오덕 A와 B가 있다. 프로 파오후 A가 B에게 'B쿤! 오늘 저녁 치킨먹자' 라고 말했다. B는 '알겠다능' 이라고 대답했다. 그리고 A가 다시 '아까 말한 저녁 먹자능' 이라고 했을 때 B는 '먼솔?' 이라고 반문한다. 분명 A는 치킨을 먹자했지만 B는 '저녁 먹자' 는 멘트의 상태를 유지하지 않기 때문에 저녁으로 뭘 먹을지 모르는 것이다. 이때 A를 클라이언트(브라우저), B를 서버(웹 서버)에 대입해 이해하면 된다. (이를 개선하기 위해 Cookie와 Session 개념이 도입됨)
3. 비 연결성 (Connectionless)
- HTTP는 연결을 유지하지 않는 프로토콜이기 떄문에 요청/응답 방식으로 동작한다. 이것도 파오후 A, B쿤을 대입해 비유하자면 A가 B에게 '오늘 저녁 치킨먹자능!' 라고 말했다. B는 치킨을 먹기위한 이유를 도출하기 위해 짱구를 굴린다. A는 B의 속을 알 수 없기 때문에 B가 응답해줄때 까지 기다린다. 이때 A와 B가 공명 상태가 아닌 것 처럼 클라이언트는 요청을 보내고 응답을 기다릴 수 밖에 없다. 지속적인 연결이 아니란 뜻이다. 또한 웹서버 통신 간 주체는 A(클라이언트)고 B(웹 서버)는 그에 해당하는 응답만 할 수 있다. B가 A에게 '저녁 피자 먹자능!' 이런 식으로 못한단 얘기다.
HTTP Request Method (요청 메소드)
클라이언트가 웹서버에게 요청하는 목적 및 그 종류를 알리는 수단
한마디로 정보 조회는 GET, 추가는 POST, 수정은 PUT, 삭제는 DELETE 등과 같이 특정 수행을 위한 리소스의 목적을 가르키는 정보라고 생각하면 쉽다. 물론 각 요청 메소드별 사용법과 차이가 존재한다.
- GET : 리소스를 조회할때 사용 (URI 형식으로 웹 서버 리소스를 요청)
- HEAD : GET과 동일한 응답을 요구하지만, 응답 본문을 포함하지 않는다.
- POST : 특정 리소스에 엔티티(개체)를 제출할 때 사용, 보통 회원 가입 기능처럼 많은 엔티티 설정 값이 넘어갈 때 사용한다.
- PUT : 내용 갱신 위주로 사용, POST와 거의 동일하지만, 주로 정보 업데이트에 사용됨
- DELETE : 특정 리소스를 삭제할때 사용.
- CONNECT : 프록시 서버와 같은 중계 서버를 경유할 때 사용
- OPTIONS : 웹 서버 제공 메소드에 대한 질의.
- TRACE : 요청 리소스가 수신되는 경로를 보여줌.
- PATCH : 리소스의 특정 부분을 수정하는 데 사용.
종류가 대충 이렇게 있는데 주로 GET/POST/PUT/DELETE 정도만 사용된다.
HTTP version 별 특징
-
HTTP/0.9
- GET 메서드만 지원
- HTTP 헤더 없음
- 상태 오류 코드없음
-
HTTP/1.0
- 단기 커넥션 (Short-lived connections)
- Request를 날릴 때마다 Connection을 새로 생성
- 데이터 전송
- 플레인텍스트
- Data를 압축해서 전달이 가능하도록 하여 전달하는 Data 양이 감소
-
HTTP/1.1 (보편적으로 많이 사용됨)
- 지속 커넥션 (Persistent connection)
- 커넥션 재사용 가능
- HTTP 파이프라이닝 (Pipelining) : Request를 미리 여러개 서버에 날릴 수도 있게 되었다
- 하나의 Reuqest 당, 한 개의 리소스를 받아옴
- 헤더 압축으로 인한 성능 향상
- HOL block 문제 (Head Of Line Blocking)
- 첫 Request에 문제가 생길 경우, 응답이 늦어지면 2, 3번째에 요청 응답도 같이 늦어짐 (응답 블로킹)
-
HTTP/2
- Multiplexing : 프레임 단위로 나눠서 전송,관리 가능하게 됨. (다수의 요청과 응답이 가능한 구조)
- 데이터 전송 : 바이너리로 인코딩하여 전송
- ServerPush 사용
- 브라우저에서 필요한 리소스들을 서버가 알아서 찾아다가 내려주는걸 의미한다
- 필요한 경우
- 캐싱되지 않은 리소스를 받아올 때
- 페이지에서 필요한 리소스가 페이지를 내려주는 서버에 있을 때
-
HTTP/3
- TCP > UDP 사용 (HOL block 문제 해결)
- QUIC 프로토콜 사용
- UDP위에 새로운 전송 계층을 추가해 TCP에 존재하는 패킷 재전송, 혼잡/속도 제어등 여러 기능 제공
- 진행 중
👁 HTTP/1.1, HTTP/2는 TCP 기반, HTTP/3는 UDP 기반 프로토콜
HTTPS
HTTPS는 HyperText Transfer Protocol over Secure Socket Layer의 약자로 HTTP의 보안이 강화된 버전이다. HTTPS는 통신의 인증과 암호화를 위해 넷스케이프 커뮤니케이션즈 코퍼레이션이 개발한 넷스케이프 웹 프로토콜이며, 전자 상거래에서 널리 쓰인다.
요약하면 얘도 HTTP인데 SSL 인증서를 곁들여 암호화된 HTTP 통신이라고 생각하면 된다. 기존 평문을 공개키 암호화방식을 사용하여 보안성을 강화하여 전송하는 프로토콜이다. CA, SSL 인증서 발급 및 암호화 프로세스에 대해서는 추후에 다루겠다. 여기선 그냥 HTTP에서 보안을 강화하면 이런 놈이 되는구나 알고 넘어가면 된다. 요즘 HTTP만으로 서비스하는 웹 포털은 없을 것이다. 당장 네이버만 봐도 알 수 있다.

Request
클라이언트(브라우저)가 서버에 리소스를 요청하는 것
말그대로 웹 서버에게 특정 리소스를 요청하는 행위다. 당장 f12 디버거 모드를 켜봐도 수많은 요청, 응답 메세지를 확인할 수 있다.
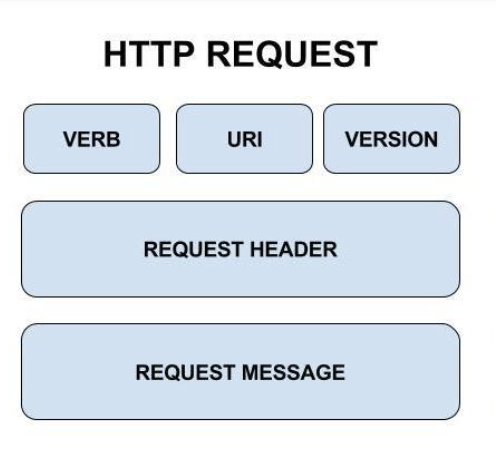
Request 구조
크게 세 덩이로 구분할 수 있다.
-
start line
이 놈안에서도 3개로 나뉜다. 아오
예시 :GET /login.do HTTP/1.1- HTTP Method : request의 요청 메소드
- Request target : 리소스 URI
- HTTP Version : request에 사용되는 HTTP version
-
headers
요청에 대한 추가 정보를 담고 있는 부분으로
Key : value구조를 갖고 있다.
자주 사용되는 header 정보에는 다음이 있다- Host : 요청이 전송되는 target의 host url
- User-Agent : 요청을 보내는 클라이언트의 대한 정보
- Accept : 받을 수 있는 응답(response) 타입
- Connection : 해당 요청 종료 후 컨넥션을 유지 여부
- Content-Type : 요청 메세지 body의 타입
- Content-Length : 요청 메세지 body의 길이
-
body
reqeust의 실제 내용으로 POST나 PUT의 경우 속성 바디가 넘어간다.
Response
서버가 요청에 대한 답변을 클라이언트(브라우저)에게 보내는 것
요청한 리소스를 반환하는 행위다.
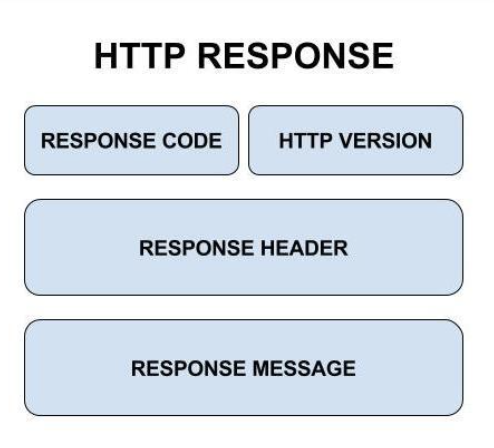
Response 구조
request와 거의 동일하다. 얘도 세 덩이로 나뉜다.
-
status line
얘도 3개로 나뉜다. 으으..
예시 :HTTP/1.1 404 Not Found- HTTP Version : HTTP version
- Status Code : 응답 상태를 나타내는 코드. 3자리 숫자로 되어있다.
- Status message : 응답 상태를 간략히 설명해주는 문구
-
headers
request의 헤더와 동일하다. 특정 부분 response에서만 사용될 수 있는 값들이 있지만 거의 안쓰인다.
-
body
요청에 대한 응답 데이터가 여기 들어온다. 그니깐 지금 지지고 복고 요청보내고 똥누고 하는게 다 이놈받을라고 하는 짓임.

Status Code

HTTP Response에 대한 상태코드를 말하며 3자리 숫자로 이루어져 있다.
요청에 대한 응답상태를 간략화한 숫자 코드로 맨 앞자리에 따라 처리 유형의 차이가 있다.
- 1xx (정보) : 요청을 받았으며 프로세스를 계속 진행
- 2xx (성공) : 요청을 성공적으로 인식
- 3xx (리다이렉션) : 요청 완료를 위해 추가 작업 필요
- 4xx (클라이언트 오류) : 요청 문법 오류 혹은 요청 처리 불가
- 5xx (서버 오류) : 유효한 요청에 대해 실패 (서버 오류)
정리하며
오늘은 HTTP와 클라이언트, 서버간 request/response에 대해 알아봤다. 그냥 프론트 엔드에서 백 엔드로 요청보낼땐 request, 그에 해당하는 응답은 response라고 생각하면 된다. 말 그대로 직역해서 생각하면 끝날 일이다.
오늘 저녁은 탄두리 치킨이다. 🥕
참조 : https://jobjava00.github.io/basic/http-version/
https://usefultoknow.tistory.com/entry/HTTP%EB%9E%80
https://javacatcher.tistory.com/32
https://cotak.tistory.com/59
https://doglovedeveloper.tistory.com/28?category=517064
https://surprisecomputer.tistory.com/54
https://velog.io/@seeker1207/HTTP-0.9%EC%97%90%EC%84%9C-HTTP-3.0%EA%B9%8C%EC%A7%80
https://velog.io/@teddybearjung/HTTP-%EA%B5%AC%EC%A1%B0-%EB%B0%8F-%ED%95%B5%EC%8B%AC-%EC%9A%94%EC%86%8C
