목표 : 관련 공식문서 읽고 ML model 만들기
Core ML
- machine learning모델을 앱에 통합시켜주는 프레임웤
- Core ML 프레임워크를 이용해 training data들로부터 model을 만들 수 있다.
- 이 model을 통해 새로운 input data의 prediction을 할 수 있다.
- 예를들어 코끼리리인지 아닌지 판단하는 모델을 만들었다면 새로운 사진이 주어졌을 때 이 사진의 피사체가 코끼리인지 아닌지 예측하도록 한다.
- Xcode의 ML app bundle을 통해 앱을 빌드하고 모델을 traing할 수 있으며 이 때 Core ML 프레임워크를 사용한다.
- 이 프레임워크는 CPU, GPU, Nerual Engine가 메모리나 배터리 소모의 최적화를 진행하며 성능을 낼 수 있도록 최적의 방법을 제공한다.
- Core ML은 domain-specific frameworks의 기반이다. 즉 목적에 따라 여러 프레워크들이 있는데 그러한 프레임워크들의 기반이다!
(Core ML is the foundation for domain-specific frameworks)
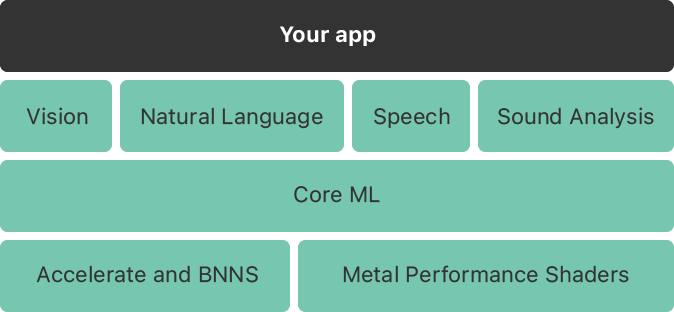
domain : 컴퓨터 프로그램영역에서의 targeted subject 를 의미. 예를들어 내가 만드는 앱이 초등학교에서 쓰이길 원한다면 내 앱의 도메인은 초등학교가 되는 것
Core ML API
- 보통의 경우 model을 xocde프로젝트에 추가하면 자동으로 만들어주는 인터페이스를 사용한다
- 하지만 작업흐름이 다른 경우나 useCases가 더 심화된 경우에는 Core ML 에서 제공하는 API를 사용한다.
- 예를들어 비동기적으로 인풋데이터를 모아야하는 경우 MLFeatureProvider 프로토콜을 사용,
- 사용방법
- MLFeatureProvider 를 클래스나 구조체에 채택한다.
- MLFeatureProvider의 MLModel 메소드를 사용한다.
Create ML
-
머신러닝 모델 만드는 프레임워크!
-
모델을 train하기!
- representative한 샘플들의 패턴을
모델이 recognize하도록 한다.
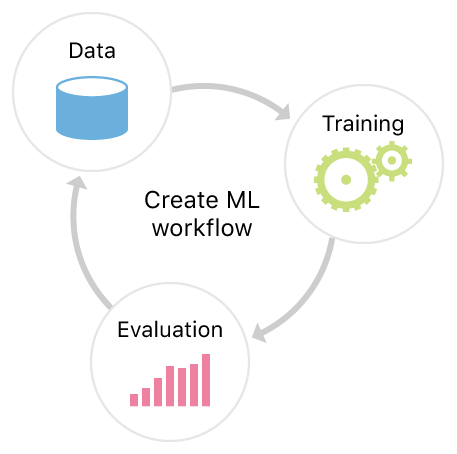
- 모델이 충분히 작동하는 경우 Core ML프레임워크를 이용해서 앱에 integrate한다.
- representative한 샘플들의 패턴을
-
Apple 제품에선 Photos, Siri 등에 내장된 machine learning 인프라스트럭쳐에 해당 프레임워크가 leverage하고 있다. (영향를 끼치고 있다. ) = 사진이나 자연어 모델의 train이 더 빠르다는 걸 의미(이미 해둔게 있어서 그렇다는 것 같다. )
Creating and Image Classifier Model
CreatML이용하기
-
모델 선정: ex) image classifier
-
image classifier는 기본적으로 scene print feature extractor 를 사용한다.
scene print feature extractor : 실제세계의 물체가 담긴 이미지를 가지고 훈련할 때 최적의 성과 내도록 해주는 것. 캐릭터 사진엔 별 효과가 없다(너무 binary해서)
-
-
데이터를 gathering하기
- 다양한 이미지 파일일 수록 더 트레이닝에 좋다.
- 카테고리별 10개 이상은 되어야한다.
- 이미지 카테고리별로 비슷한 수의 이미지를 제시해야한다.
- 이미지 사이즈에 제약은 없지만 최소 299X299 픽셀은 되어야한다
- 이미지 확장자는 퀵타임플레이어에서 오픈되는거면 다 가능(ex : JPEG, PNG 등등)
-
트레이닝에 사용할 데이터를 정리하기
-
데이터 셋 트레이닝 시키기
- 트레이닝 데이터 셋 추가하기
- 테스트 데이터 셋 추가하기
- 트레이닝 데이터셋의 Parameters 설정(optional?)
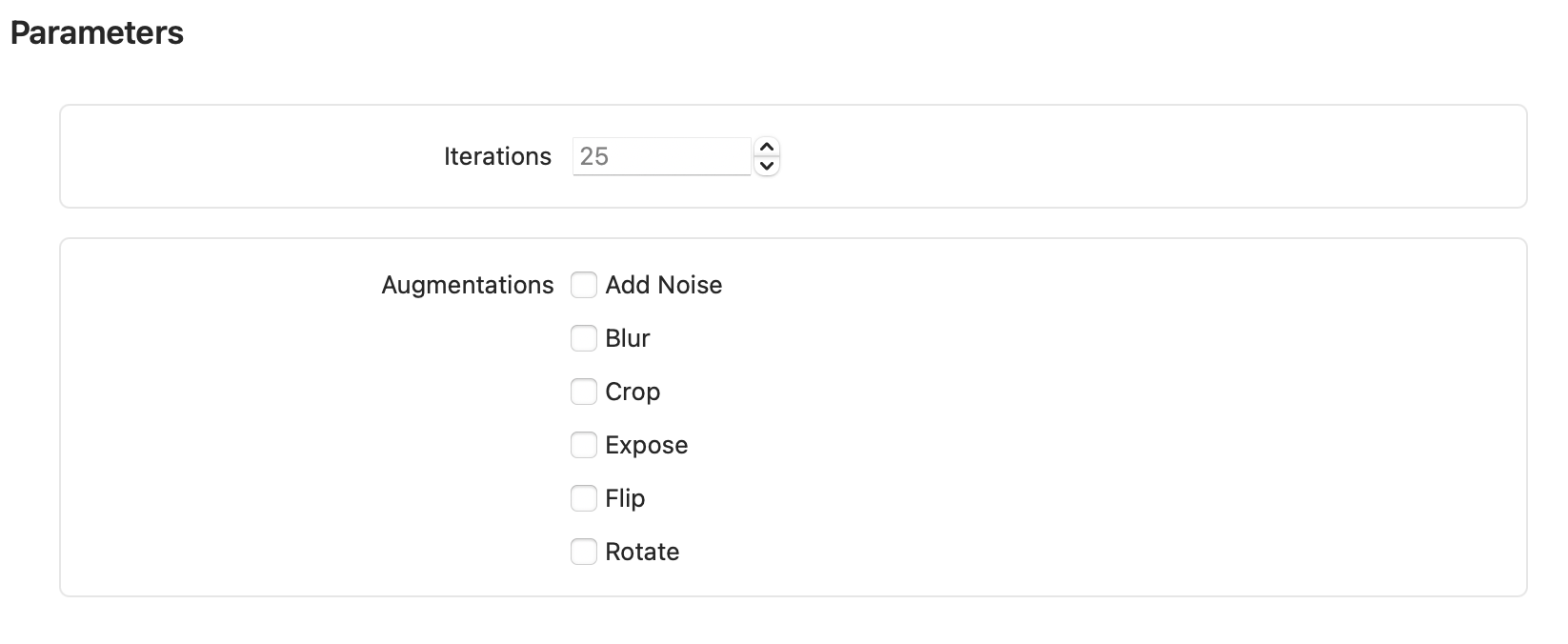
Iteration : 트레이닝 몇 번 반복할 것인지 정할 수 있음. 기본값은 25
Argumentations : Argumet정하면 트레이닝을 위해 입력한 데이터셋을 복사한 후 해당 argument에 맞게 변형한다(예를들어 Blur를 선택한 경우 데이터셋 복사 이후 이미지에 blur처리를 함)
iv. train 버튼 클릭하면 아래와 같이 나옴
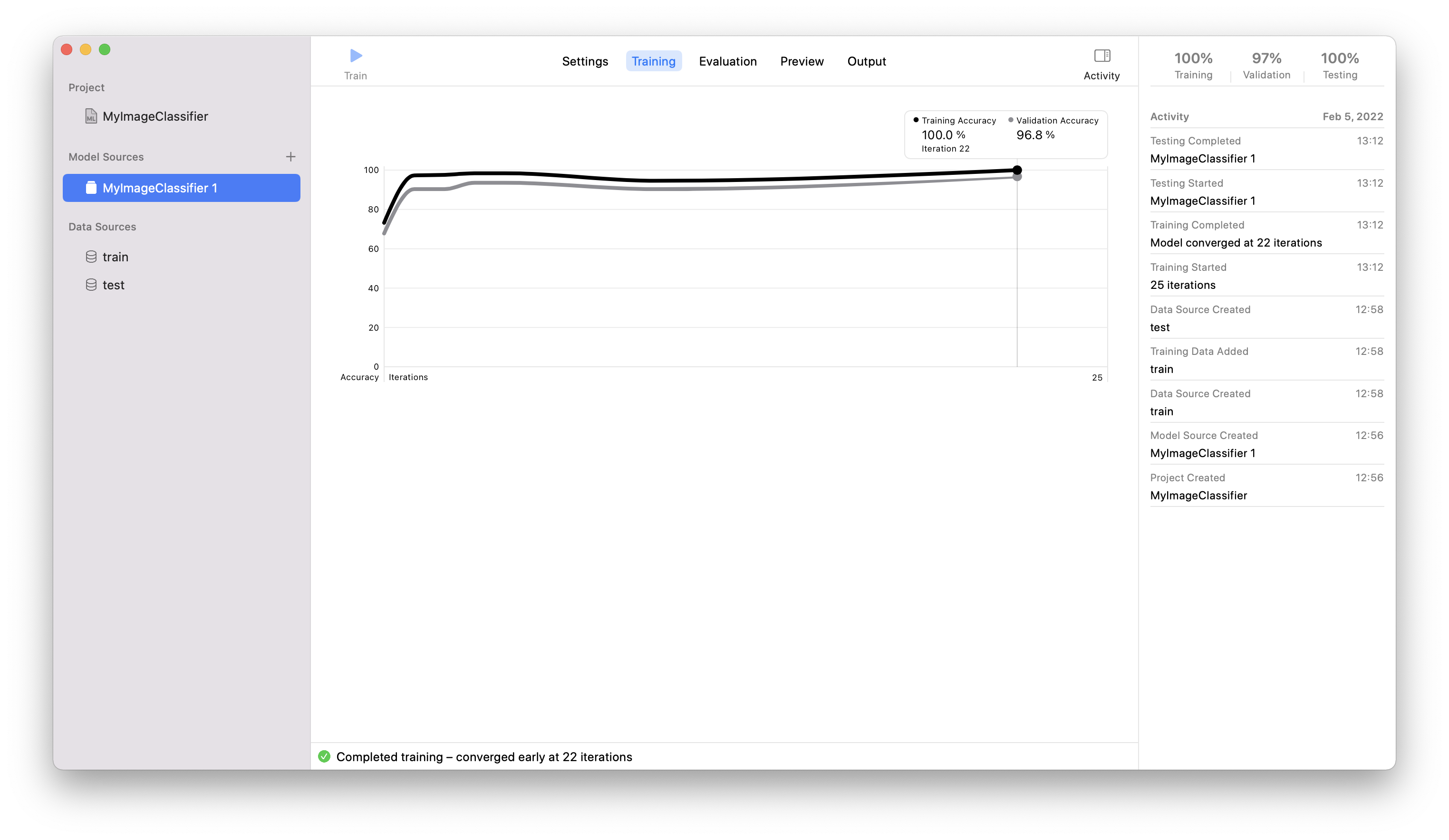
v. model의 Accuracy가 충분하지 못 한 경우 더 다양한 데이터가 필요하다. (Accuracy 높이기)
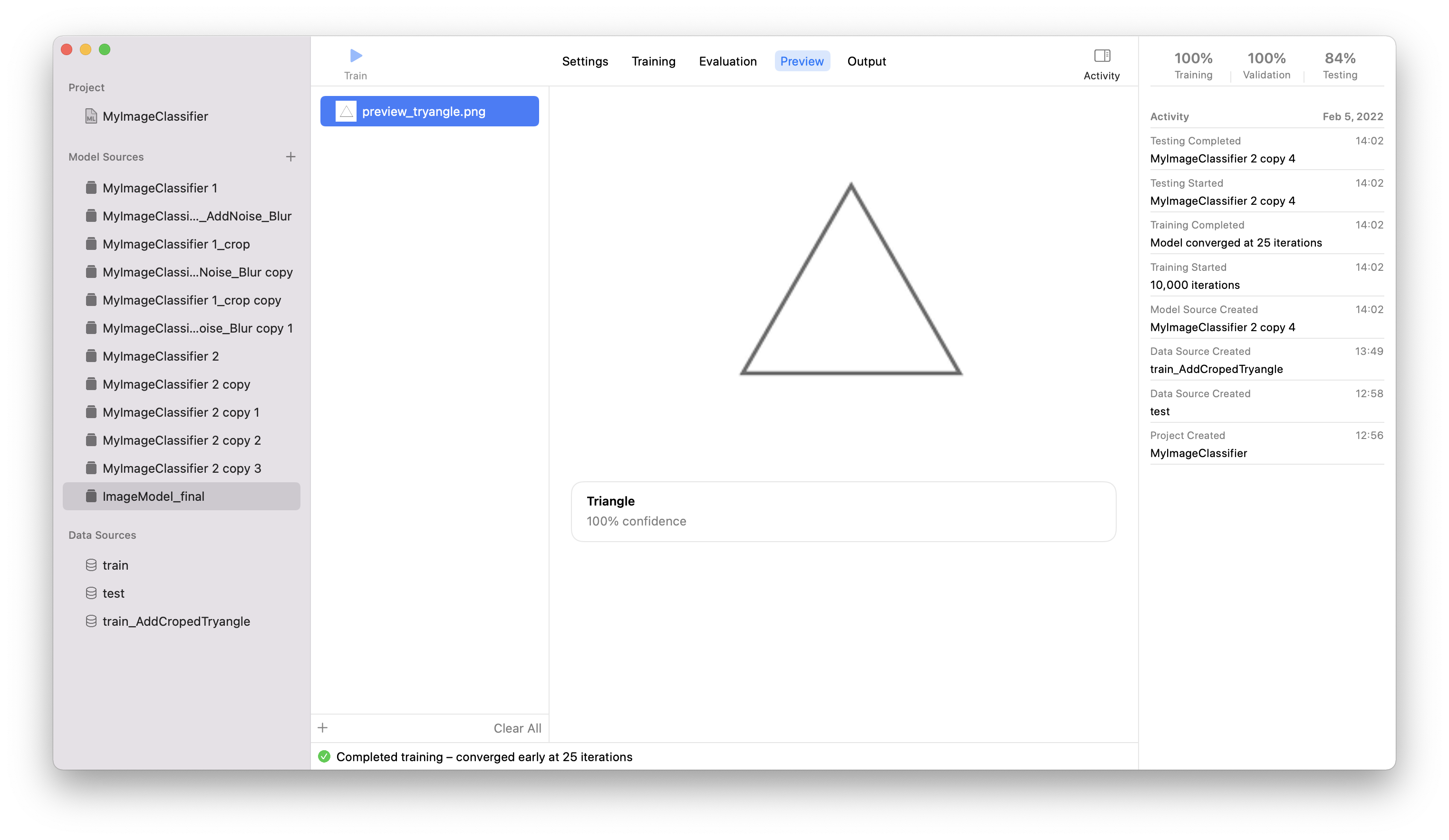
vi. Preview : 트레이닝 할 때 썼던 이미지가 아닌 새로운 이미지를 추가하고 어떻게 prediction하는지 살펴보기
-
완성된 model을 저장한 후 Xcode project에 추가하기
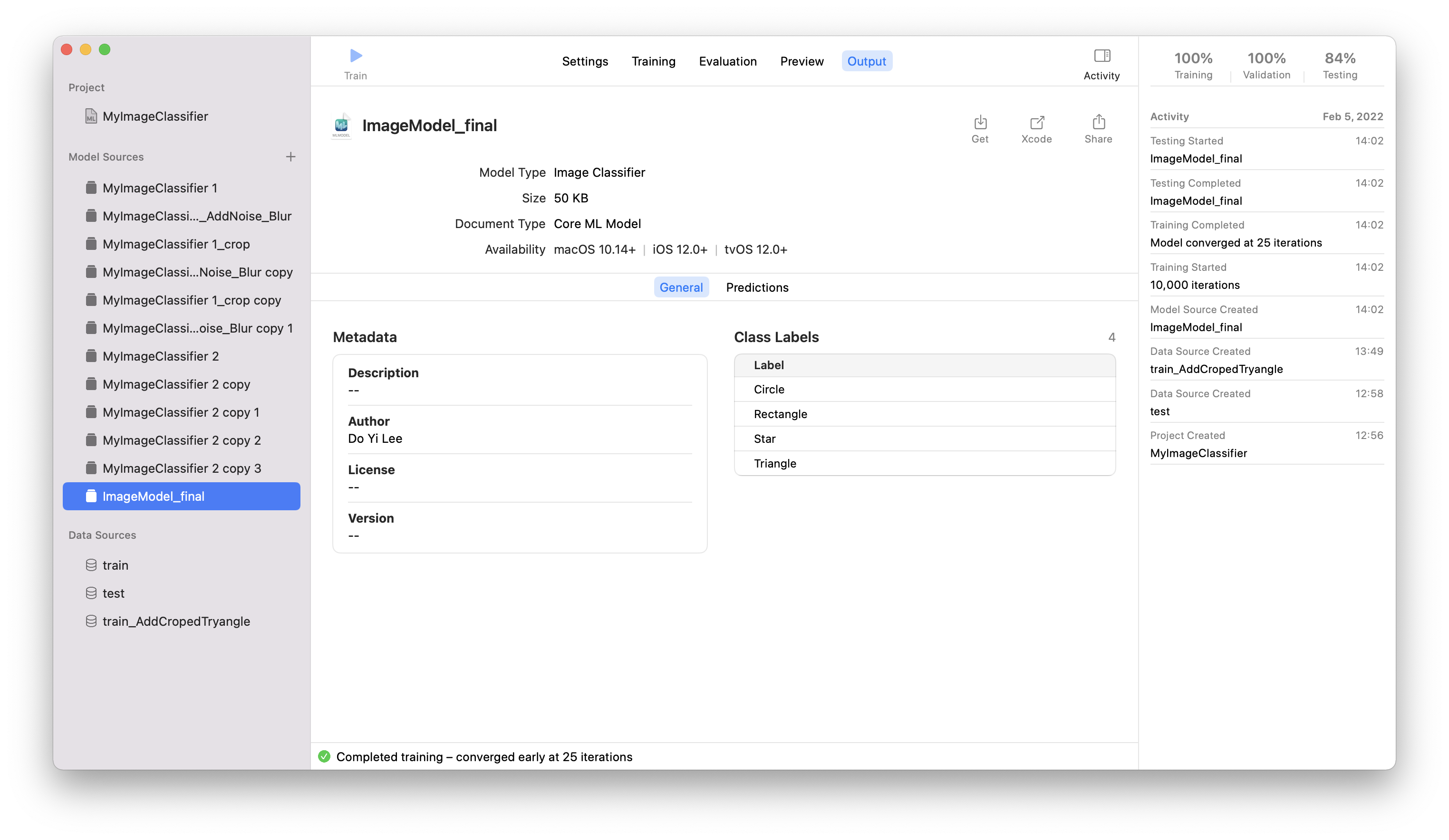
i. model 파일 저장- 상단 File에서 Save 클릭
- 혹은 아래 OutPut에서 get, share, Xcode 등 이용
ii. Xcode에 드래그앤 드롭으로 추가
iii. 모델에 접근하기
- 모델의 파일명이 코드의 타입명 (ex :모델 파일 이름 - ImageModel_final, 코드에서의 타입명 - ImageModel_final)
import CoreML class ... { let defaultConfig = MLModelConfiguration() let imageModelWrapper = try? ImageModel_final(configuration: defaultConfig) }
testing 데이터 셋의 precision이 계속 낮은데 이건 상관없는건가? 만약 상관있다면 어떻게 향상 시킬 수 있나?
Create Model in Programmatically
MLImageClassifier 인스턴스를 사용해서 model training 작업을 진행할 수 있다. 위 방법과의 차이점은 모든 과정이 코드를 통해 이루어진 다는 것.
- 주의점 : 프로젝트는 iOS가 아닌 macOS temaplate을 만들어야한다. iOS 템플릿에서는 CreateML이 import되지 않는다.
- pesudo code
import CreateML //1. Make Data set for training and testing let trainingDataSource = MLImageClassifier .Data .Source(trainingData:parameters:) let testDataSource = MLImageClassifier .Data .Source(...) // Train let matrics = evaluation(on:) 메소드 이용 (matrics의 타입 : MLClassifierMetrics) // Access to result matrics를 통해 접근
