
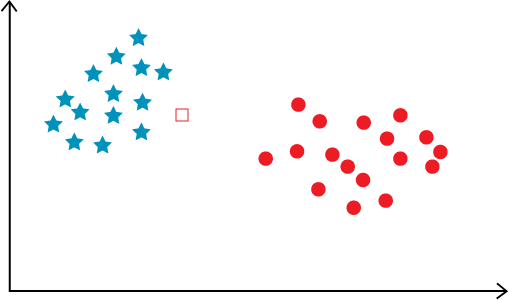
벡터(vector)
벡터란 공간에서 크기와 방향을 가지는 것을 의미하며, 위의 그림에서는 별모양과 원모양의 점들이 바로 하나하나의 벡터가 되는 것입니다.
또한, 특정 벡터들이 모여 있는 것을 특징량이라고 부르며, 머신러닝에서는 바로 이 특징량을 바탕으로 벡터들을 서로 구분하게 됩니다.
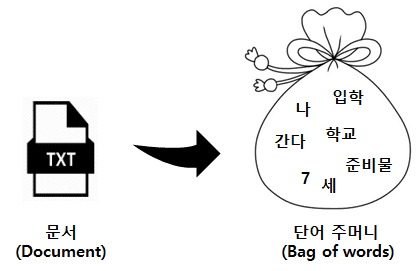
bag-of-words (BoW)
단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법
one-hot vector
원-핫 인코딩은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식입니다. 이렇게 표현된 벡터를 원-핫 벡터(One-Hot vector)라고 합니다.
예) 사과 - [1, 0, 0]
오렌지 - [0, 1, 0]
멜론 - [0, 0, 1]
워드 임베딩(word embedding) / 벡터화
- 기계가 이해할 수 있도록 단어를 0과 1의 수치로 표현하는 방법
- 전체 단어들 간의 관계에 맞춰 해당 단어의 특성을 갖는 벡터로 바꿔주므로 단어들 사이의 유사도를 계산할 수 있다.
- 통계적 기반
- 코퍼스의 통계량을 활용
- LSA(Latent Semantic analysis, 잠재의미분석) : 단어 사용 빈도, 코퍼스의 통계량 정보가 들어있는 행렬의 특이값 분해... 벡터들의 차원을 축소
- 단어 수준 : 단어를 기준으로
- 문장 수준 : 문장을 기준으로
- 신경망 기반(뉴럴 네트워크 기반)
- Word2Vec -> FastText -> ELMO -> BERT
- 단어 수준
- 문장 수준

Curious for Everything