❝
2023-08-12에 작성된 문서입니다
❞
1. 가상환경 설정
가상환경에서 설치해야 하는 이유 - pywikibot을 `pip isntall pywikibot` 했을 때는 local의 wikibase와 연결하기 위해서 포트 번호 변경하는 파일을 수정해줄 수 없음. - pywikibot 깃헙을 클론해서 (파일이름 core) 하위 파일들 수정하고(아래 참고) 가상환경에서 불러와서 모듈 임포트해서 해결 - 기본 가상환경(?) 만들어서 해도 되는데, 연결이 잘 안돼서 아니콘다에서 가상환경 만든 것 (로컬 python kernel 연결이 뭔가 꼬인 듯. 그냥 가상환경 만들어서 연결 잘 되면 아나콘다에서 안만들어도 됨)1.1 아나콘다 가상환경 설정
conda create -n wikibase python=3.7- 가상환경 실행하기
conda activate wikibase
terminal이랑 jupyter notebook kernel이랑 둘다 가상환경으로 설정됐는지 확인해야 한다.
2. github repo만들어서 clone
- clone한 폴더에 ipynb 파일 하나 만들고 가상환경 kerneldmfh 접속하기
3. pywikibot 설치하기
3.1. pywikibot git clone
git clone https://gerrit.wikimedia.org/r/pywikibot/core.git
3.2. 추가 설치하기
-
pip install requests -
pip install -r requirements.txt -
cd core 들어가서
git submodule update --init→ 조금 오래걸림 -
python pwb.py login -all이 코드를 치면 아래와 같은 화면이 출력되면서 새로 생성을 시작한다.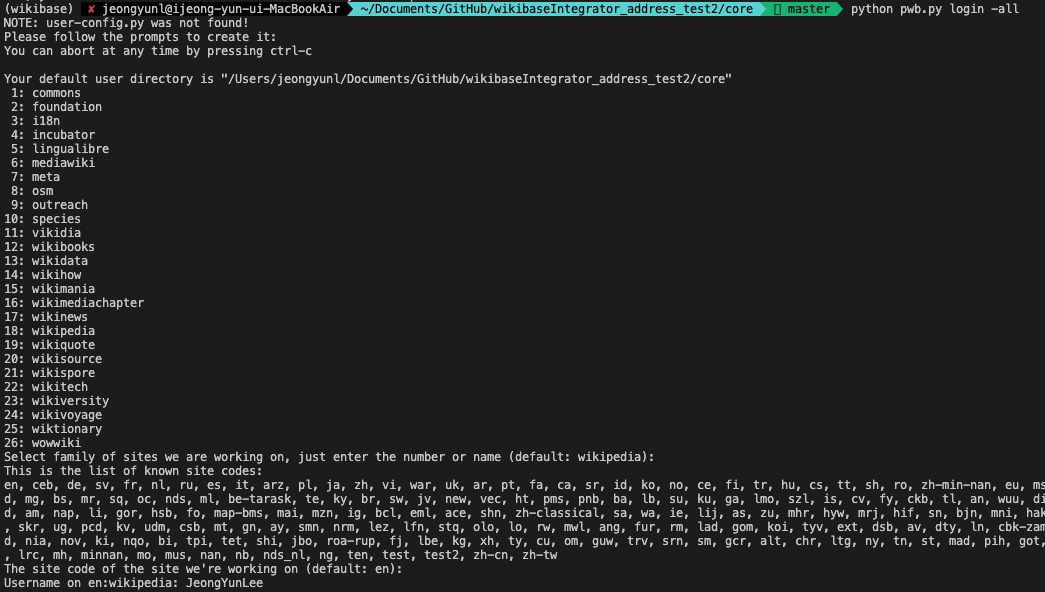
- family 선택할 때 mediawiki로 진행
- username, bot name, bot password 치고 나서 'Do you want to select framework setting sections?'과 'Do you want to select scripts setting sections?' 질문이 나왔을 때 다 a(전체 다 선택함) 누르면 user-config.py 파일 생성 완료!
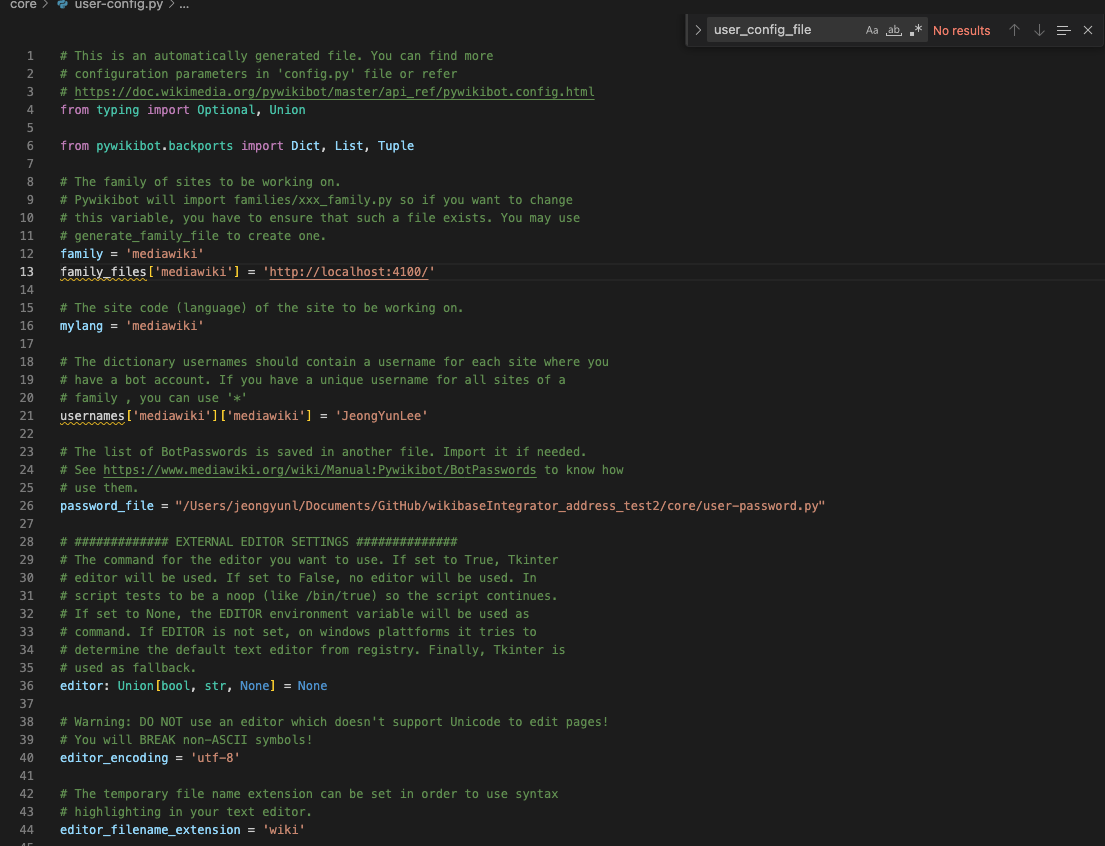
3.3. core/user-config.py 파일 수정하기
- user-config.py 파일 잘 생성되었는지 확인
- 추가 수정
family_files['wikipedia'] = '[http://localhost:4100/](http://localhost:4100/)'추가 (port number는 직접 수정)- password_file 경로 지정
- mylang 에 다른 언어도 넣어주고 싶다면 똑같은 형식으로 넣으면 됨 (ex.
mylnag = 'ko')
3.4. core/user-password.py 파일 수정하기
-
형식이 아래와 다르게 저장되어 있을 수 있다. 아래와 같은 형식으로 수정한다.

password 설정은 'localhost:4401/wiki/Special:BotPasswords'과 같이 본인이 설정한 포트나 도메인에서 위 경로로 들어가서 설정하면 botpassword를 생성해서 알려준다.
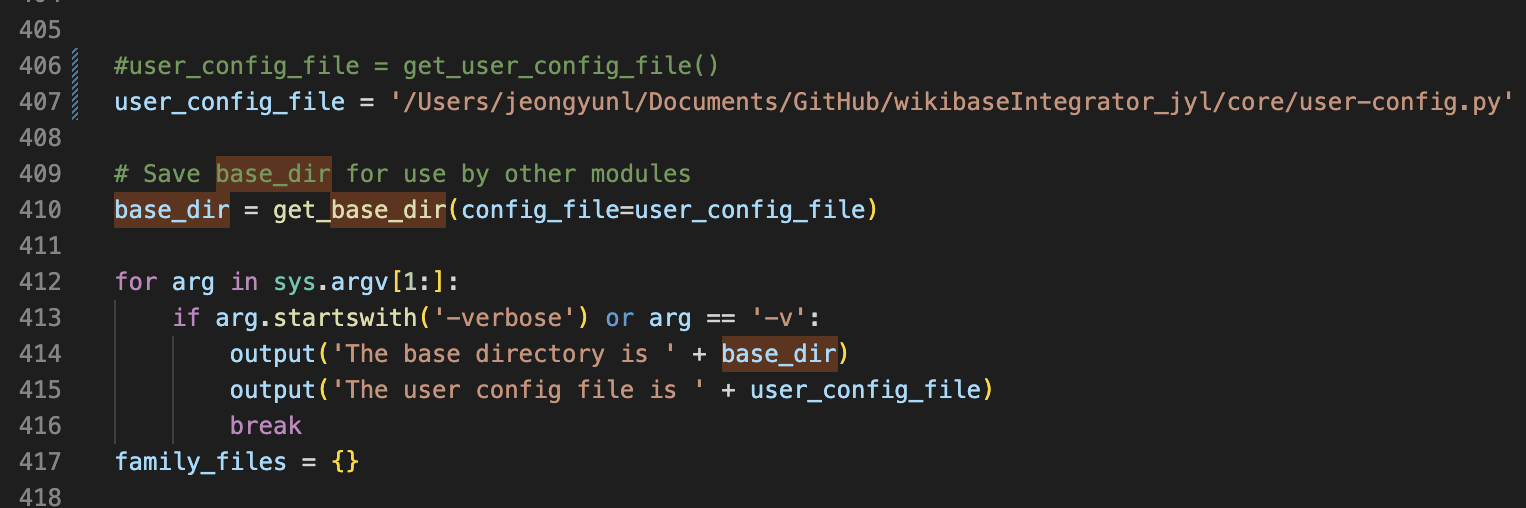
3.5. core/pywikibot/config.py 파일 수정하기
- user_config_file 변수에 get_user_confifg_file() 함수 쓰지 말고 그냥 user-config.py 경로로 바로 넣어주면 된다.
4. ipynb: CONNECT
지금부터는 python의 ipynb 파일에서 진행하는 내용이다. 아래 코드들은 모두 이 깃헙을 참고했다.
- core의 경로를 sys.path에 추가
import sys
sys.path.append('/Users/jeongyunl/Documents/GitHub/wikibaseIntegrator_jyl/core')
print(sys.path)- local wikibase 연결하기
from wikibaseintegrator import WikibaseIntegrator
from wikibaseintegrator.wbi_config import config as wbi_config
wbi_config['MEDIAWIKI_API_URL'] = 'http://localhost:4100/w/api.php'
wbi_config['SPARQL_ENDPOINT_URL'] = 'http://localhost:8834/proxy/wdqs/bigdata/namespace/wdq/sparql'
wbi_config['WIKIBASE_URL'] = 'http://wikibase.svc'
wbi_config['USER_AGENT'] = 'MyWikibaseBot/1.0 (https://www.wikidata.org/wiki/User:JeongYun Lee)'- login
from wikibaseintegrator import wbi_login
login_instance = wbi_login.Login(user='JeongYun Lee', password='*****', mediawiki_api_url='http://localhost:4100/w/api.php')- pywikibot install
import pywikibot, json, csv, sys
from pywikibot import family5. ipynb: ADD PROPERTIES
"""
Notes:
We need to remove the built in throttling because we
are working on our own localhost running wikibase, we don't
care if we do a ton of requests, we are likely the only user
"""
# over write it
def wait(self, seconds):
"""Wait for seconds seconds.
Announce the delay if it exceeds a preset limit.
"""
pass
pywikibot.throttle.Throttle.wait = wait
if __name__ == "__main__":
csv_path = '/Users/jeongyunl/Documents/GitHub/wikibaseIntegrator_address_test2/testData/add_properties.csv'
csv_file = open(csv_path,'r', encoding='utf-8-sig')
csv_reader = csv.DictReader(csv_file)
### 로그인 이미 했으므로 안해도 됨
site = pywikibot.Site('mediawiki:mediawiki')
#site.login()
complete_data = []
for row in csv_reader:
row = dict(row)
data = {
'datatype': row['Datatype'], # mandatory
'descriptions': {
'ko': {
'language': 'ko',
'value': row['Property Description']
}
},
'labels': {
'ko': {
'language': 'ko',
'value': row['Property Label']
}
}
}
params = {
'action': 'wbeditentity',
'new': 'property',
'data': json.dumps(data),
'summary': 'bot adding in properties',
'token': site.tokens['csrf']
# 'token': site.tokens['edit']
}
req = site._simple_request(**params)
results = req.submit()
row['PID'] = results['entity']['id']
print(row['PID'], row['Property Label'])
complete_data.append(row)
csv_file.close()
with open(csv_path+'_updated.csv','w') as out:
fieldnames = list(complete_data[0].keys())
writer = csv.DictWriter(out, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(complete_data)6. ipynb: ADD CORE ITEMS
import wikidataintegrator as WI
import requests, csv, sys, re
########## part1 ##########
WI.wdi_core.WDItemEngine.core_props = {
'P50': {
'datatype': 'string',
'name': '식별자',
'domain': ['addresTerms'], # this is a wikidataintergrator thing, to group properties together
'core_id': True
}
}
use_unique_property = 'P50:string'
if __name__ == "__main__":
csv_path = '/Users/jeongyunl/Documents/Github/wikibaseintegrator_address_test2/testData/add_core_items.csv'
csv_file = open(csv_path,'r', encoding='utf-8-sig')
csv_reader = csv.DictReader(csv_file)
complete_data = []
errors_data = []
for row in csv_reader:
row = dict(row)
data = []
# properties stuff
for key in row:
# is it a property field
if key.find(':') > -1 and key[0] == "P":
PID, data_type = key.split(':')
# there are few other data types need to add...
try:
if data_type.lower() == 'string':
if row[key] is not None and row[key].strip() != '':
statement = WI.wdi_core.WDString(value=row[key], prop_nr=PID)
data.append(statement)
elif data_type.lower() == 'url':
if row[key] is not None and row[key].strip() != '':
statement = WI.wdi_core.WDUrl(value=row[key], prop_nr=PID)
data.append(statement)
elif data_type.lower() == 'wikibase-item':
if row[key] is not None and row[key].strip() != '':
statement = WI.wdi_core.WDItemID(value=row[key], prop_nr=PID)
data.append(statement)
except Exception as e:
print("There was an error with this part1, skipping:")
print(row)
print(e)
errors_data.append(row)
data = "error"
if data == 'error':
continue
if use_unique_property in row:
item_name = row[use_unique_property]
else:
item_name = None
########## part2 ##########
domain = 'addresTerms'
try:
wd_item = WI.wdi_core.WDItemEngine(new_item=True, data=data, mediawiki_api_url="http://localhost:4100/w/api.php")
# set the label and description if exists
if 'Label' in row:
if row['Label'] is not None and row['Label'].strip() != '':
wd_item.set_label(row['Label'])
if 'Description' in row:
if row['Description'] is not None and row['Description'].strip() != '':
wd_item.set_description(row['Description'])
# write
r = wd_item.write(login_instance)
print("goodbye!")
# QID is returned
row['QID'] = r
print(row['QID'], row['Label'])
complete_data.append(row)
except Exception as e:
print("There was an error with this part2, skipping:")
print(row)
print(e)
errors_data.append(row)
data = "error"
csv_file.close()
with open(csv_path+'_updated.csv','w') as out:
fieldnames = list(complete_data[0].keys())
writer = csv.DictWriter(out, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(complete_data)
if len(errors_data) > 0:
with open(csv_path+'_errors.csv','w') as out:
fieldnames = list(errors_data[0].keys())
writer = csv.DictWriter(out, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(errors_data)7. ipynb: ADD ITEMS
ADD CORE ITEMS와 코드 동일함
import wikidataintegrator as WI
import requests, csv, sys, re
########## part1 ##########
WI.wdi_core.WDItemEngine.core_props = {
'P50': {
'datatype': 'string',
'name': '식별자',
'domain': ['addresTerms'], # this is a wikidataintergrator thing, to group properties together
'core_id': True
}
}
use_unique_property = 'P8:string'
if __name__ == "__main__":
csv_path = '/Users/jeongyunl/Documents/Github/wikibaseintegrator_address_test2/testData/add_core_items.csv'
csv_file = open(csv_path,'r', encoding='utf-8-sig')
csv_reader = csv.DictReader(csv_file)
complete_data = []
errors_data = []
for row in csv_reader:
row = dict(row)
data = []
# properties stuff
for key in row:
# is it a property field
if key.find(':') > -1 and key[0] == "P":
PID, data_type = key.split(':')
# there are few other data types need to add...
try:
if data_type.lower() == 'string':
if row[key] is not None and row[key].strip() != '':
statement = WI.wdi_core.WDString(value=row[key], prop_nr=PID)
data.append(statement)
elif data_type.lower() == 'url':
if row[key] is not None and row[key].strip() != '':
statement = WI.wdi_core.WDUrl(value=row[key], prop_nr=PID)
data.append(statement)
elif data_type.lower() == 'wikibase-item':
if row[key] is not None and row[key].strip() != '':
statement = WI.wdi_core.WDItemID(value=row[key], prop_nr=PID)
data.append(statement)
except Exception as e:
print("There was an error with this part1, skipping:")
print(row)
print(e)
errors_data.append(row)
data = "error"
if data == 'error':
continue
if use_unique_property in row:
item_name = row[use_unique_property]
else:
item_name = None
########## part2 ##########
domain = 'addresTerms'
try:
wd_item = WI.wdi_core.WDItemEngine(new_item=True, data=data, mediawiki_api_url="http://localhost:4100/w/api.php")
# set the label and description if exists
if 'Label' in row:
if row['Label'] is not None and row['Label'].strip() != '':
wd_item.set_label(row['Label'])
if 'Description' in row:
if row['Description'] is not None and row['Description'].strip() != '':
wd_item.set_description(row['Description'])
# write
r = wd_item.write(login_instance)
print("goodbye!")
# QID is returned
row['QID'] = r
print(row['QID'], row['Label'])
complete_data.append(row)
except Exception as e:
print("There was an error with this part2, skipping:")
print(row)
print(e)
errors_data.append(row)
data = "error"
csv_file.close()
with open(csv_path+'_updated.csv','w') as out:
fieldnames = list(complete_data[0].keys())
writer = csv.DictWriter(out, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(complete_data)
if len(errors_data) > 0:
with open(csv_path+'_errors.csv','w') as out:
fieldnames = list(errors_data[0].keys())
writer = csv.DictWriter(out, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(errors_data)
궁금한 건 많지만, 천천히 알아가는 중입니다