XLNet: Generalized Autoregressive Pretraining for Language Understanding(by 강유진)
paper reading
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Abstract
BERT와 같이 양방향 문맥을 모델링하는 능력으로 사전학습을 기반으로 한 denoising autoencoding은 autoregressive LM을 기반으로 하는 사전학습된 접근보다 훨씬 좋은 성능을 보였다. 그러나 인풋을 마스크로 denoising하는 것에 기반하면서 BERT는 마스크된 자리 사이의 의존을 무시했고, pretrain과 finetune 사이 차이가 존재했다. 이러한 BERT의 장단점과 관련해 XLNet을 제안한다. XLNet은 일반화된 qutoregressive pretraining method로 다음과 같은 특징을 갖는다.
- 모든 계산을 인수분해로 더 간단히 변환시켜 예상되는 가능성을 극대화시킴으로 양방향 문맥을 학습하는 것을 가능하게 했다.
- XLNet의 autoregressive formulation으로 BERT의 한계를 극복했다.
- XLNet은 Transformer-XL의 아이디어와 pretraining을 결합시켰다.
Introduction
- 비지도 표현 학습은 자연어처리 분야에서 꽤 성공적.
- 일반적으로 이러한 방법들은 최초로 large-scale unlabeled text corpora로 사전학습된 신경망 네트워크(neural network)
- 여러 분야에 맞춰 모델을 fine-tune하거나 표현.
- 가장 성공적인 pre-training objectives
- autoregressive LM
- autoencoder
- autoregressive Language Model
- autoregressive model과 함께 텍스트 코퍼스의 확률 분포를 평가하는 방법을 찾았다.
- 텍스트 순서 가 주어졌을 때, AR LM은 확률을 행렬화했다.
- forward product
- backward product
- AR LM은 오직 단방향 문맥을 인코딩하는데 훈련되어졌다. 깊은 양방향 문맥을 모델링하는데 효과적이지 않음
- 세부적인 lanugage understanding tasks는 자주 양방향 문맥 정보를 요구하기 때문에 AR과 효과적인 사전학습과는 거리가 생길 수 밖에 없음
- autoencoder based pretraining
- 명시적인 density estimation을 수행하지 않고 대신 원래 데이터를 오염된 인풋으로부터 재건하는데 목적을 둔다. BERT가 대표적인 예시이다.
- 인풋 토큰 순서가 주어지면 특정한 토큰의 부분은 special 심볼인 [MASK]로 대체된다. 그리고 모델은 마스크된 버젼을 원래 토큰으로 다시 되돌리는 것을 목적으로 학습된다.
- density estimation은 목적함수의 일이 아니기 때문에 BERT는 재건을 위해 양방향 문맥을 활용하는 것을 허락한다.
- 이러한 이점으로, autoencoder는 앞서 언급한 auto-regressive LM의 양방향적 정보의 차이를 줄인다.
- 존재하는 언어 사전학습 objectives의 장단점을 마주하며 XLNet을 제안한다.
- XLNet은 AR LM과 AE를 둘다 사용하여 위와 같은 한계를 피하고자하는 일반화된 autoregressive method이다.
- 명시적인 density estimation을 수행하지 않고 대신 원래 데이터를 오염된 인풋으로부터 재건하는데 목적을 둔다. BERT가 대표적인 예시이다.
- XLNet
- 전통적인 AR 모델은 고정된 forward, backward factorization 순서를 사용하는데 그 대신 XLNet은 예상되는 sequence(모든 가능한 factorization 순서의 순열에 대해)의 log likelihood를 최대화한다.
- 각 자리에 대한 문맥은 왼쪽과 오른쪽으로부터의 토큰들로 구성될 수 있다.
- 각 자리는 모든 자리로부터 문맥적인 정보를 활용하도록 학습되어진다. = bidirectional context를 잡는다.
- 일반화된 AR LM로, XLNet은 data corruption에 의존하지 않는다.
- 따라서 사전학습- 파인튜닝 간 차이에 의해 고통받지 않는다. ↔ BERT의 단점이었음
- 한편, autoregressive objective는 예측된 토큰의 joint probability를 factorizing을 위해 product rule을 사용하는 방식을 제공한다.
- XLNet은 사전학습에 대한 architectural designs을 향상시킨다.
- AR LM에 영향을 받아 XLNet은 segment recurrence mechanism과 상대적인 encoding 체계를 사전훈련에 통합시켰다.
- factorization order는 제멋대로이고, target도 불분명하기 때문에 Transformer(-XL) architecture를 permutation-based LM에 적용한 것은 동작하지 않는다.
- 전통적인 AR 모델은 고정된 forward, backward factorization 순서를 사용하는데 그 대신 XLNet은 예상되는 sequence(모든 가능한 factorization 순서의 순열에 대해)의 log likelihood를 최대화한다.
Realted Work
- 순열 기반의 AR modeling의 아이디어는 탐구되어져왔지만 이들에게는 몇몇의 중요한 다른점이 있다.
- 이전 모델들은 “순서 없는" 귀납적 편향을 적용해 density estimation을 향상시키는 것을 목표로 삼았다.
- ↔ XLNet은 AR 언어모델이 양방향 컨텍스트를 학습할 수 있도록 motivated
- 이전의 순열기반의 AR 모델들은 그들의 MLP(Multi Layer Perceptron) 아키텍쳐로 부터 상속받은 명시적인 position awareness 에 의존했다.
- ↔ 기술적으로, 유효한 target-aware prediction distribution을 세우기 위해 XLNet은 두 줄기의 attention을 통해 target position을 hide state에 포함시켰다.
- 순서없는 NADE(Neural Autoregressive Distribution Estimation), XLNet 에 대해
“순서 없는(orderless)”이 인풋 순서가 랜덤하게 순열되어 들어갈 수 있다는 것을 의미하는 것이 아니라, 모델이 분포의 다른 factorization orders을 허용한다는 것을 의미한다는 것을 강조.
- 이전 모델들은 “순서 없는" 귀납적 편향을 적용해 density estimation을 향상시키는 것을 목표로 삼았다.
2 Proposed Method
2.1 Background
- 먼저 전통적인 AR LM과 BERT를 비교하고자 한다.
- text sequence 가 주어지면, AR LM은 아래의 forward autoregressie factorization의 확률을 최대화하며 사전학습을 수행한다.
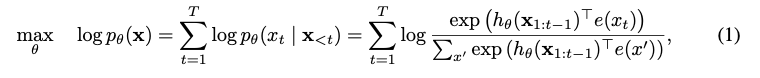
- = neural models(RNNs나 Transformers 등)에 의해 생산된 context representation
- = embedding of x.
- x = text sequence
- = 오염된 text sequence ver.
- = masked tokens
- BERT는 denoising auto-encoding을 기반으로 한다.
- 특히, text sequence x에 대해 BERT는 오염된 version인 을 text seqence x안에 ****토큰의 랜덤하게 세팅한 부분에 따라(예를 들어 15%정도 ) 먼저 [MASK]로 만든다. masked tokens →
- training objective는 으로 부터 를 다시 만든다.
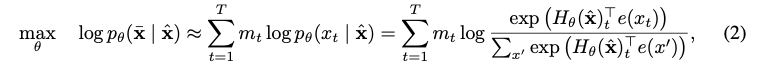 은 가 마스크되었다는 것을 의미하고, 은 T-길이의 text sequence x 를 hidden vectors의 sequence로 매핑하는 Transformer이다.
은 가 마스크되었다는 것을 의미하고, 은 T-길이의 text sequence x 를 hidden vectors의 sequence로 매핑하는 Transformer이다.
- text sequence 가 주어지면, AR LM은 아래의 forward autoregressie factorization의 확률을 최대화하며 사전학습을 수행한다.
- 두 사전학습 objevtives의 장단점은 아래의 관점에서 비교할 수 있다.
- Independene Assumption
- 식 (2)에서 강조했듯이, BERT는 joint conditional probability 을 factorize(인수분해. 인수를 곱셈의 형식으로 만듬.)
- 모든 masked tokens 가 개별적으로 등장하지 않지만, product rule로 나타내기 위해 독립적이라는 가정이 필요하다.
- AR LM objectivesms x를 인수분해한다.
- 독립 가정과 같은 것없이 예외없이 유지하는 product rule 사용
- 따라서, Independence Assumption이 필요없다는 측면에서는 AR LM이 더 좋음
- 식 (2)에서 강조했듯이, BERT는 joint conditional probability 을 factorize(인수분해. 인수를 곱셈의 형식으로 만듬.)
- Input noise
- BERT에 들어가는 [MASK]같은 심볼은 실제 Task에서는 발견할 수 없는 인공적인 작업.
- 이것은 pretrain과 fine-tune 간의 차이를 유발한다.
- [MASK]를 원래 토큰으로 다시 대체하는 작업은 문제를 해결하지 못한다.
- 반면, AR LM은 인풋 corruption에 의존하지 않기 때문에 위와 같은 문제가 발생하지 않는다.
- BERT에 들어가는 [MASK]같은 심볼은 실제 Task에서는 발견할 수 없는 인공적인 작업.
- Context dependency
- AR의 context representaion인 는 오직 단방향의 문맥만 담을 수 있지만, BERT의 context representation인 는 양방향 문맥을 모두 담을 수 있다.
- Independene Assumption
2.2 Objective: Permutation Language Modeling
- 위에서 AR과 BERT(AE)의 장점과 단점 살펴봤고, 이들의 단점은 피하면서 장점만 가져올 수 있는 방법에 대해 고민
- orderless NADE(Neural Autoregressive Distribution Estimation)에서 영감을 받아, permutation langauge modeling objective에 대해 제안한다.
-
AR model의 장점(독립 가정 필요 없음, pretrain - finetune 간 차이 나타나지 않음), bidirectional contexts를 모두 유지하는 objective
-
길이 의 sequence x에 대해, 의 다른 순서를 사용한다.
- autoregressive factorization을 수행하는 factorial이다.
- 다른 순서: 5! = 35214( ↔ original order 5! = 54321)
-
만약, 모델 파라미터가 모든 인수분해 순서(factorization order)를 갖고 있는다면, 모델은 모든 위치에서 각 양 방향의 정보를 모을 수 있도록 학습될 것이다.
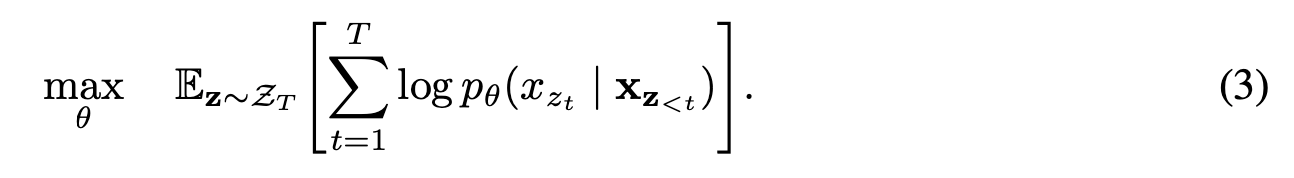
-
x(text sequence)에 대해 factorization order z를 때마다 샘플링 할 것 이고, 이 factorization order z에 따라 를 순서에 맞게 분해할 것이다.
-
는 모든 factorization order에 거쳐 훈련동안 공유되기 때문에 는 모든 가능한 요소 일 것이다. 그래서 양 방향의 문맥을 다 잡아낼 수 있다.
-
이 objective는 AR 프레임워크에 맞춰져있기 때문에 자연스럽게 독립 가정, 사전학습과 파인튜닝 사이의 간극을 피할 수 있게 된다.
Remark on Permutation
-
제안한 objective는 오직 factorization order의 순서를 바꾸고, sequence의 순서를 바꾸지 않는다!
- 원래 순서와 일치하는 positional encoding을 사용해 원래 sequence 순서는 유지하고, 적절한 Transformer의 attention mask를 사용해 factorization order의 순서 바꿈을 수행한다.
- 원래 sequence를 건들이지 않는 것은 필수임.
- 모델이 finetuning동안은 자연스러운 순서로 text sequence를 입력으로 받기 때문이다.
-
아래 그림은 token 를 예측하는 예시인데 같은 input sequence x이지만 다른 Factorization order를 사용하는 것을 보여주는 예시이다.
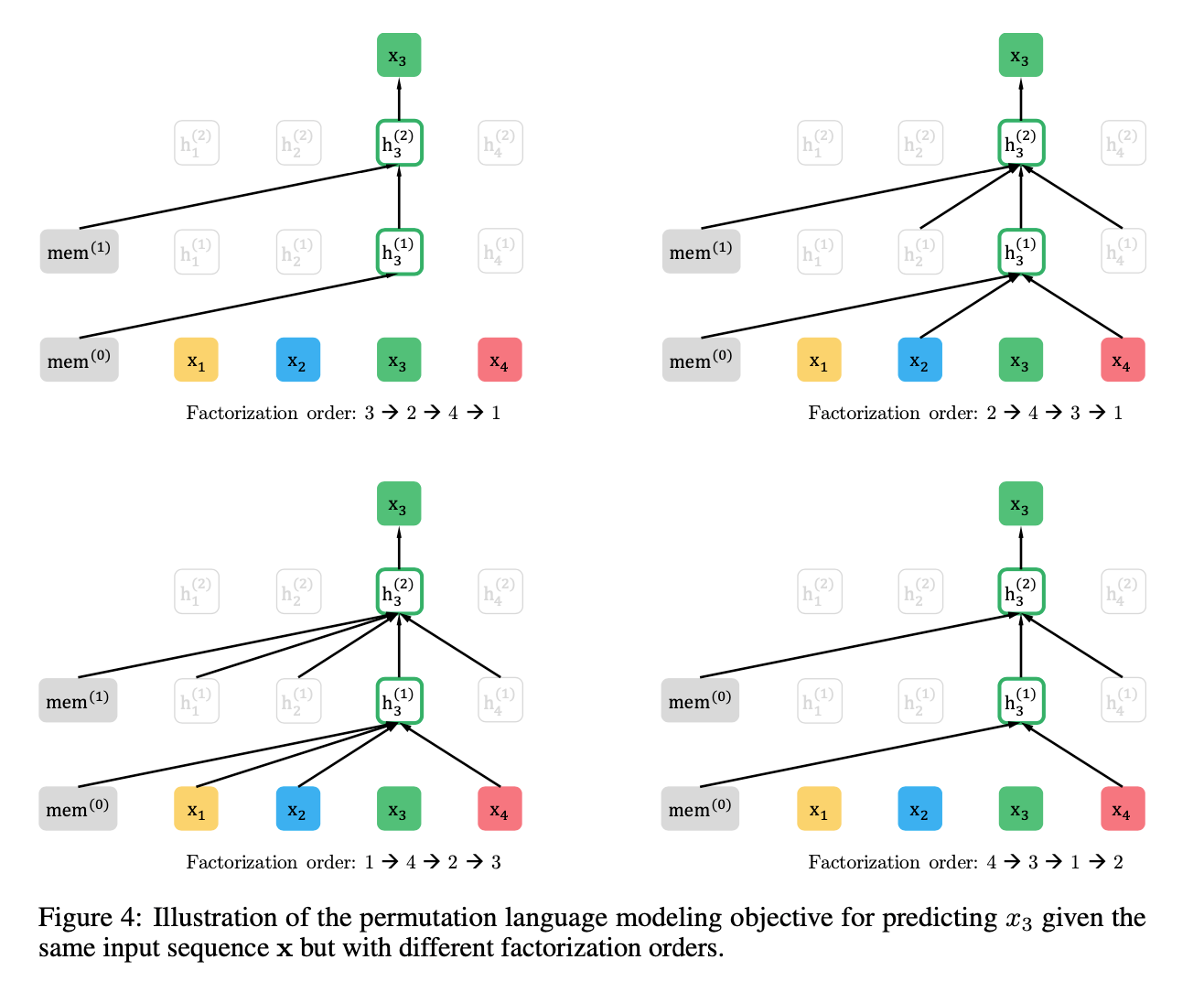
각 순서들에 대해 x3 를 예측하는 부분(초록색)을 보면 x3 를 예측하기 위해 [x4],[x2,x4],[x1,x2,x4] 를 이용합니다. 모든 permutation()에 대해 위 과정을 수행하면 x3를 제외한 [x1,x2,x4] 의 모든 부분집합에 conditional한 x3 의 probability를 계산할 수 있습니다. 그러므로 특정 token에 대해 양방향 context를 고려한 AR Modeling이 가능해지고 기존 AR방식의 한계를 극복할 수 있습니다. (https://blog.pingpong.us/xlnet-review/)
-
2.3 Architecture: Two-Stream Self-Attention for Target-Aware Representations
- permutation language modeling objective가 원하는 성질을 기본 Transformer parameteriation로는 구할 수 없다.
- AR LM의 objective는 이전 token을 보고, 다음 token을 예측함.
- 학습 할 때 라고 할 때, 을 학습하기 위해서는 를 제외한 모든 input은 masking, 을 예측할 때는 제외하고는 다 masking하는 방식을 사용
- next-token distribution 가 기본 Softmax를 사용한다고 가정할 때, , 이 식에서 transformer의 hidden representation 는 즉, 현재 target index 이전의 context token 들에만 의존.
- 위의 값은 결국 target index position에 관계없이 같은 값을 갖게 되는 문제를 발생시킴.
-
같은 형식의 AR LM은 단방향으로 진행되기 때문에 target index position이 명확함.
-
그러나 XLNet의 object는 index를 permutation한 후 진행하기 때문에 이전까지 Index가 같더라도 여러 target index position이 존재할 수 있음.
Input sequence [x1,x2,x3,x4]와 index의 permutation =[[1,2,3,4],[1,3,2,4],…[4,3,2,1]] 에 대해 학습을 진행한다고 가정해 보겠습니다.
[2,3,1,4]의 경우 p(x1∣x2,x3)을 계산하기 위해 hθ(x2,x3) 과 같은 representation을 이용합니다.[2,3,4,1]의 경우에도 p(x4∣x2,x3)을 계산하기 위해 hθ(x2,x3) 과 같은 representation을 이용합니다.결과적으로 같은 representation을 이용하여 x4과 x1을 예측해야 하는 문제가 발생합니다.
-
- 이러한 문제를 해결하기 위해 이전 context token들의 정보 () 뿐만 아니라 target index의 position 정보()도 함께 이용하는 Target Position-Aware Representation 제안.
Two-Stream Self-Attention
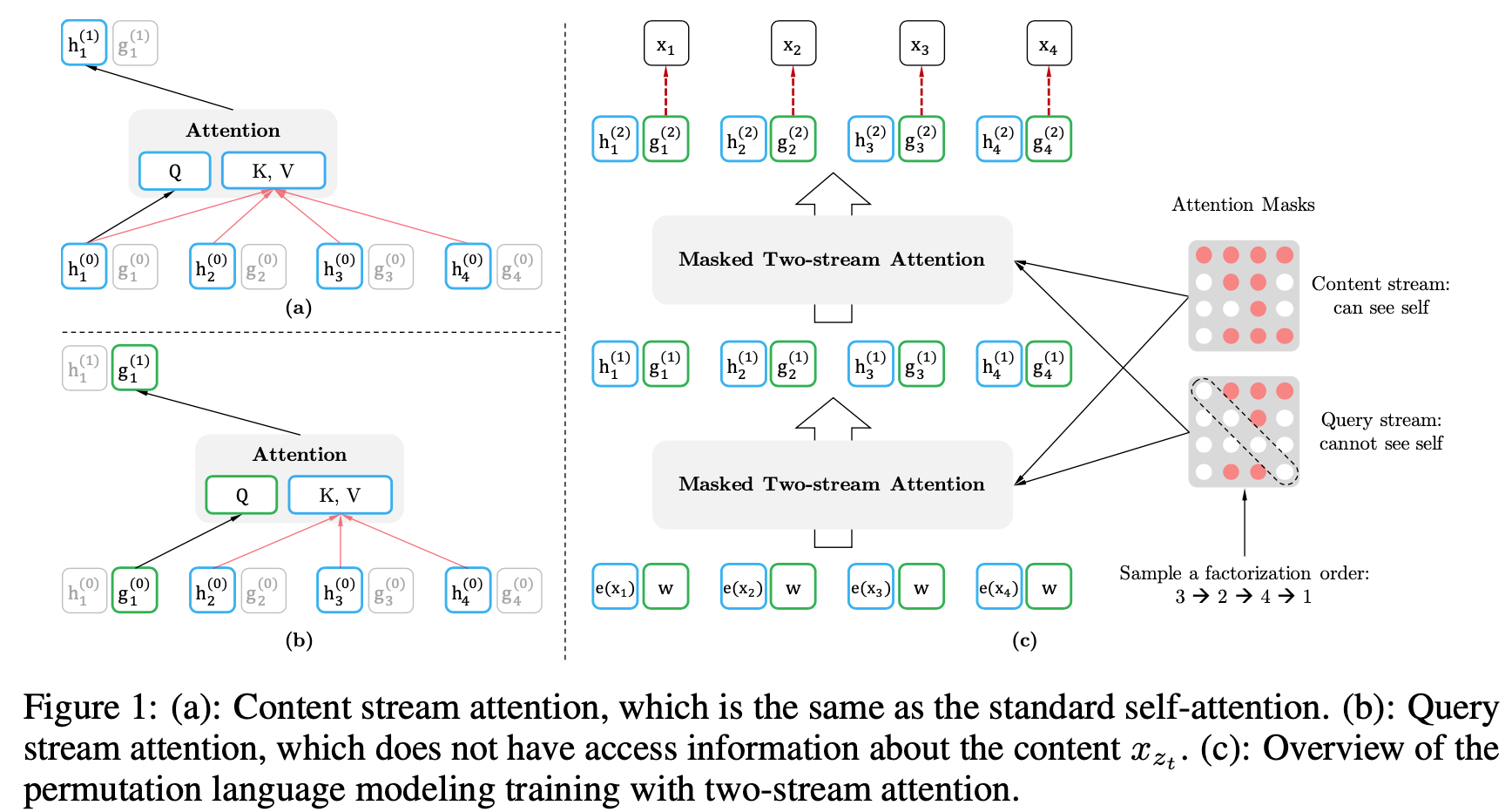
- target 예측의 불확실성을 없애기 위해 어떻게 는 아래의 두가지 조건을 충족해야한다.
- 토큰 를 예측하기 위해 는 target position 정보 , t 시점 이전 context 정보인 만을 사용해야한다.
- t시점 이후의 토큰인 를 예측하기 위해서, 는 또한 t 시점의 content 를 인코딩해야한다. 모든 문맥 의 정보를 제공하기 위해서 필요하다.
- 기본 transformer는 한 token 당 하나의 representation을 갖는다. 그러나 위의 hidden representation 은 따르면 두개의 representation이 요구된다.
- 1번은 t 시점의 hidden representation은 t시점의 context를 포함하지 않지만
- 2번 조건에서는 t 시점의 context를 포함해야한다.
- 각 layer에서 한 token이 두개의 Representation을 갖게 하기 위해 저자는 2개의 hidden representation을 갖게 하는 Two-Stream Self-Attention을 제안한다.
- Content Stream
-
-
2번 조건을 충족하기 위한 = 는 Content representation로, 기존의 Transformer와 비슷한 역할을 한다. 이 representation은 context와 둘다 인코딩한다.
-
target position 정보인 과 t시점의 content를 담고있는 토큰인 를 사용한다.
-
Content Stream은 Query로 이전 layer의 h state(),
Key, Value로는 이전 Layerdml h state()를 사용한다. -
기본 Transformer의 self attention과 Q,K, V가 동일, t index 이후의 token state들은 making하여 연산 진행.
- Query Stream
- 1번 조건을 충족하기 위해 현재 시점을 제외한 이전 시점의 위치정보를 이용해 계산하는 representation
- 마지막 layer의 Query Representation을 이용해 현재 position의 token을 예측하는 pretraining objective를 계산.(현재 layer의 Query Stream은 이전 layer의 g state를 attend하여 h state값들로 벡터를 재구성)
- content(z<t)와 위치정보 (t)만 이용하는 stream
Partial Prediction
- permutation language modeling objective는 훨씬 더 최적화하는 것이 까다롭다.
- permutation이 수렴하는데 느리기 때문.
- 이러한 문제를 줄이기 위해 특정 순서에서 마지막 몇 토큰만 예측하는 방법을 취함.
- z를 cutting point c를 통해 타켓부분과 타겟이 아닌 부분으로 나눠 계산.
2.4 Incorporating Ideas from Transformer-XL
- Transformer-XL에서 사용된 두가지 중요 기술을 사용.
- relative positional encoding scheme
- 기본 Transformer는 단어의 position을 모델링하지 않는 대신 positional encoding을 함.
- 하지만, 이러한 Positinal encoding은 Transformer-XL과 같이 segment가 recurrent한 경우 문제가 발생한다.
- segment recurrence mechanism
- relative positional encoding scheme
- rcurrence mechanism을 제안한 permutation 방식에 통합하는 방법과 이전 segments의 hidden states를 모델이 재사용하는 방법에 대해 살펴볼 것이다.
- 긴 sequence에서 두 segments를 가져온다고 가정하자.
- s; and , permutation
- permutation 가 주어졌을 때 첫번째 segment를 처리하고, 그리고 나서 각 layer m에 대한 content representations 를 갖게 된다. 그런다음 다음 segment 에 대해 attention update는 다음과 같다.
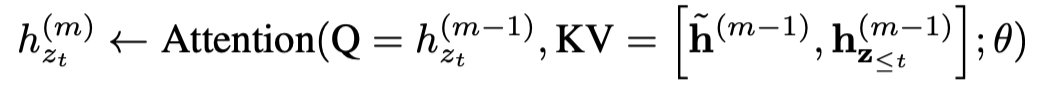
- positional encoding은 원래 sequence에 실제 자리에만 의존하기 때문에 의 attention update는 permutation에 독립적이다.
- 이전 segment의 factorization 순서를 아는 것이 필요없기 때문에 memory를 아낄 수 있다.
2.5 Modeling Multiple Segments
- 많은 세부 태스크들은 다수의 input segment를 갖기 때문에 이 다수의 segments를 받아 XLNet을 pretrain하는 것에 대해 다루고자 한다.
- pretraining 단계에서, BERT와 같이 랜덤하게 두 segments를 샘플링하고 두 segment를 이어붙인 것을 하나의 sequence로 여겨 permutation langauge Modeling을 수행했다.
- 이때, 같은 문맥에서 두 segments가 샘플링 된 경우에만 메모리를 reuse할 수 있다.
- XLNet의 인풋의 모양은 BERT(: [CLS, A, SEP, B, SEP])와 동일하다.
-
SEP, CLS 두개의 special symbol과 A, B라는 두개의 segments를 이용한다.
Relative Segment Encoding
-
BERT와 다른 것은 완전한 segment embedding을 각 자리에 word embedding에 더한다는 것이다.
-
Transformer-XL의 relative encoding의 idea를 이어받아 segments를 인코딩한다.
- sequence 내에 position 가 쌍으로 주어졌을 때, 같은 segment 내에 가 있다면 segment encoding를 로 인코딩하고, 같은 segment 안에 있지 않다면 로 인코딩해 두 position이 갖은 segments 내에 있는지 아닌지 따진다.
- 는 각 attention head의 학습가능한 모델 파라미터이다.
- segment encoding 는 attention weight을 계산하는데 사용된다.
- , 는 query vector, b는 학습할 수 있는 head 특정 편향 벡터
- sequence 내에 position 가 쌍으로 주어졌을 때, 같은 segment 내에 가 있다면 segment encoding를 로 인코딩하고, 같은 segment 안에 있지 않다면 로 인코딩해 두 position이 갖은 segments 내에 있는지 아닌지 따진다.
-
relative segment encoding의 장점
- relative encodings의 귀납 편향은 일반화를 향상시킨다.
- 완전한 segment encoding을 사용하지 못하는 두개 이상의 segments를 갖는 태스크에 대한 파인튜닝의 가능성을 열어준다.
-
2.6 Discussion
- XLNet은 BERT가 하지못하는 pair 간의 관계를 잡아낼 수 있다는 것을 주목해야 한다.
3 Experiments
3.4 Ablation Study
- Ablation study를 하는 세가지 목적
- 특히 denoising auto-encoding objective인 BERT와 비교해 permutation language modeling objective의 효과를 보이기 위해
- Transformer-XL를 신경망의 뼈대로 삼은 것의 중요성을 보이기 위해
- 몇가지 실행에 대한 자세함을 보여줄 필요가 있기 때문
1. span-based prediction
2. bidirectional input pipline
3. next-sentence prediction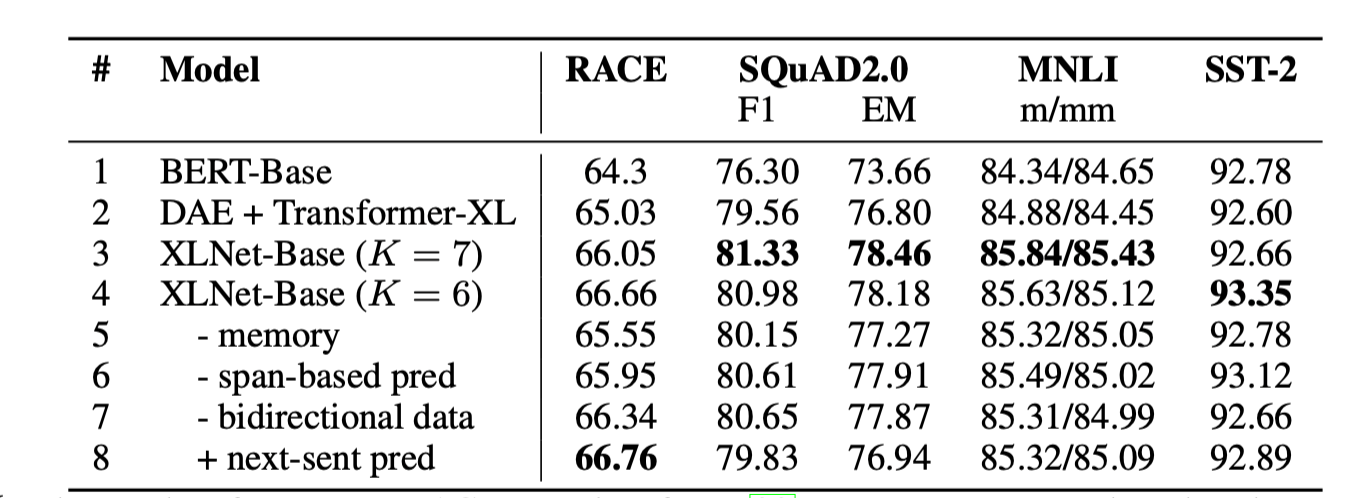
[참고1](https://blog.pingpong.us/xlnet-review/](https://blog.pingpong.us/xlnet-review/)
