DeepLearning
활성화 함수, 경사하강법 비교
InputLayer 입력층
Dense 뉴런(중간층)
Flatten 1차원으로 만들어줌

최적화도구를 class로 사용시 디폴트 값 수정 가능
model3.add(InputLayer(input_shape=(28,28)))
model3.add(Flatten())
model.add(Flatten(input_shape=(224,224))) 위 코드 이걸로 대체 가능
Flatten 에 InputLayer기능이 들어있음
from selenium import webdriver as wb # 브라우저를 조작하는 도구
from selenium.webdriver.common.keys import Keys # 키 입력을 도와주는 도구(키보드)
from bs4 import BeautifulSoup as bs # 문서를 파싱해서 선택자 활용을 도와주는 도구
from tqdm import tqdm # 반복문 진행 정도를 시각화해주는 도구
from urllib.request import urlretrieve # 이미지 다운로드를 도와주는 도구
import time # 시간제어 도구
import os # 폴더 생성,삭제,이동 등을 도와주는 도구
from selenium import webdriver as wb # 브라우저를 조작하는 도구
from selenium.webdriver.common.keys import Keys # 키 입력을 도와주는 도구(키보드)
from bs4 import BeautifulSoup as bs # 문서를 파싱해서 선택자 활용을 도와주는 도구
from tqdm import tqdm # 반복문 진행 정도를 시각화해주는 도구
from urllib.request import urlretrieve # 이미지 다운로드를 도와주는 도구
import time # 시간제어 도구
import os # 폴더 생성,삭제,이동 등을 도와주는 도구
keyword = "쿠루루"
# 이미지가 저장될 폴더 생성
# 해당 폴더가 있는지 확인
if os.path.isdir('./{}'.format(keyword)) == False :
os.mkdir('./{}'.format(keyword)) # 폴더 생성
url = 'https://www.google.com/search?q={}&source=lnms&tbm=isch&sa=X&ved=2ahUKEwjs85-GsN7vAhX4xYsBHR6aBg0Q_AUoAXoECAEQAw&biw=1745&bih=852'.format(keyword)
driver = wb.Chrome() # 브라우져 생성
driver.get(url) # url 요청
time.sleep(5) # 페이지 로딩까지 5초 대기
cnt = 0
pre_img_src = [] # 이전에 다운로드된 경로
for j in range(10) :
img_html = bs(driver.page_source,'html.parser')
# 이미지 태그 수집
images = img_html.select('img.rg_i.Q4LuWd')
# 이미지 태그의 src 속성 값 추출
img_src = []
for img in images :
src = img.get('src')
if src != None : # img 태그에 src 속성이 없는 경우
if src not in pre_img_src : # 이전에 다운로드한 경로에 있는지 검사
img_src.append(src)
else : # img 태그에 src 속성이 있는 경우
src = img.get('data-src')
if src not in pre_img_src :
img_src.append(src)
# 파일 다운로드
# img_src를 반복문으로 돌면서 저장, tqdm 사용
for src in tqdm(img_src) :
cnt += 1
try :
urlretrieve(src,'./{}/{}.png'.format(keyword,cnt))
except :
print("수집불가")
continue
pre_img_src += img_src # 다운로드한 경로를 이전 리스트에 추가
# 화면 스크롤
for i in range(6):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# driver.find_element_by_css_selector('body').send_keys(Keys.PAGE_DOWN)
time.sleep(1)구글에서 keyword로 이미지 다운받기!
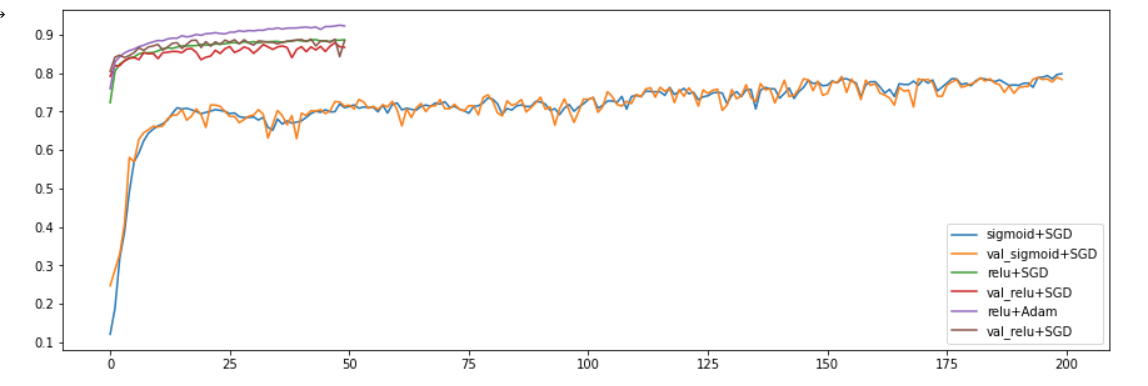
relu+Adam > Best

os.path.join() : 경로 설정을 편하게 할 수 있음
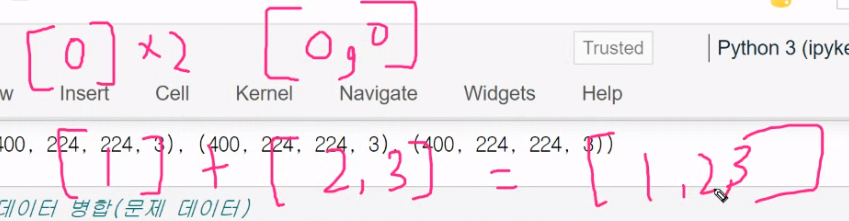
파이썬 리스트 연산

numpy 데이터 묶음!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image # 파이썬에서 가볍게 이미지를 다룰때 사용하는 라이브러리
import os #
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image # 파이썬에서 가볍게 이미지를 다룰때 사용하는 라이브러리
import os #
케로로_path = "./케로로"
기로로_path = "./기로로"
쿠루루_path = "./쿠루루"
# 각 폴더별 사진 이름 가져오기
케로로_fnames = os.listdir(케로로_path) # 지정된 폴더 내부의 파일명, 폴더명을 가져옴
기로로_fnames = os.listdir(기로로_path)
쿠루루_fnames = os.listdir(쿠루루_path)
len(케로로_fnames), len(기로로_fnames), len(쿠루루_fnames)
# 균등할수록 좋음 , 불균형하면 데이터가 많은걸 잘 맞춤
(399, 400, 400)
0
# 이미지 1개 오픈
#test_path = 케로로_path +"/"+케로로_fnames[0]
test_path = os.path.join(케로로_path,케로로_fnames[0])
test_path
'./케로로\\1.png'
test_path
Image.open(test_path)
a a제거
# 특정폴더에 있는 사진들을 읽어주는 함수
def load_images(folder_path, file_names, img_size=(224,224)) :
images = [] # 사진들이 담길 리스트
for fname in file_names :
path = os.path.join(folder_path, fname) # 한장의 사진 경로 생성
img = Image.open(path).resize(img_size).convert('RGB') # convert rgb 투명도 없애기 위해 rgba a제거
images.append(np.array(img))
# 리스트타입도 numpy 타입으로 변경해서 반환
return np.array(images)
케로로_data = load_images(케로로_path,케로로_fnames)
기로로_data = load_images(기로로_path,기로로_fnames)
쿠루루_data = load_images(쿠루루_path,쿠루루_fnames)
케로로_data.shape, 기로로_data.shape, 쿠루루_data.shape # (사진개수, 가로,세로,색상) 3차원 , 영상은 5차원
((399, 224, 224, 3), (400, 224, 224, 3), (400, 224, 224, 3))
.shape
# 데이터 병합(문제 데이터)
X = np.concatenate([케로로_data, 기로로_data, 쿠루루_data])
X.shape
(1199, 224, 224, 3)
# 정답데이터 (케로로 : 0, 기로로 : 1, 쿠루루 : 2)
y = np.array([0]*399 + [1] * 400 + [2] * 400)
y.shape
(1199,)
# 훈련데이터, 평가데이터로 분리 (8:2)
from sklearn.model_selection import train_test_split
이미지로 학습데이터 만들기!
from tensorflow.keras import Sequential
from tensorflow.keras.layers import InputLayer, Dense, Flatten
from tensorflow.keras.optimizers import Adamkeras 모델 임포트
# 1.신경망 구조 설계
model = Sequential()
#Flatten 명령을 통해 데이터를 한번에 펴주는
# 입력층(input_dim) + 중간층 1개(Dense)
# input_dim : 입력되는 데이터의 특성 수
# activation : 활성화 함수 설정(들어온 자극(데이터)에 대한 응답여부를 결정하는 함수)
model.add(Flatten(input_shape=(224,224,3) ))
# 중간층
model.add(Dense(128, activation='relu')) # 하나의 층
model.add(Dense(256, activation='relu')) # 하나의 층
model.add(Dense(256, activation='relu')) # 하나의 층
model.add(Dense(128, activation='relu')) # 하나의 층
# 출력층
model.add(Dense(3, activation='softmax')) # 케로로,기로로,쿠루루 총 3개
model.summary()MLP 모델
input_shape 데이터에 맞게 썼는지 항상 체크
출력층 개수 체크 softmax 데이터가 3개이상일 때, 사용
model.compile(loss='sparse_categorical_crossentropy',
optimizer=Adam(learning_rate=0.001), # 최적화함수 : 경산강법의 방식을 설정해주는 함수
metrics=['acc'] # metrics : 분류모델의 평가방법을 설정(정확도)
)sparse_categorical_crossentropy : 다중 분류 손실함수
훈련데이터 label 값이 정수인 경우 사용!
h = model.fit(X_train, y_train,
validation_split=0.2,
epochs=50,
batch_size=64)"validation_split=0.2"
데이터에서 20%만큼 훈련데이터를 만들어 학습 진행
model.evaluate(X_test, y_test)테스트셋으로 학습평가!
import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
# train데이터
plt.plot(h.history['acc'], label='acc', c='blue', marker='.')
# val데이터
plt.plot(h.history['val_acc'], label='val_acc', c='red', marker='.')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.legend()
plt.show()학습된 데이터 수치화
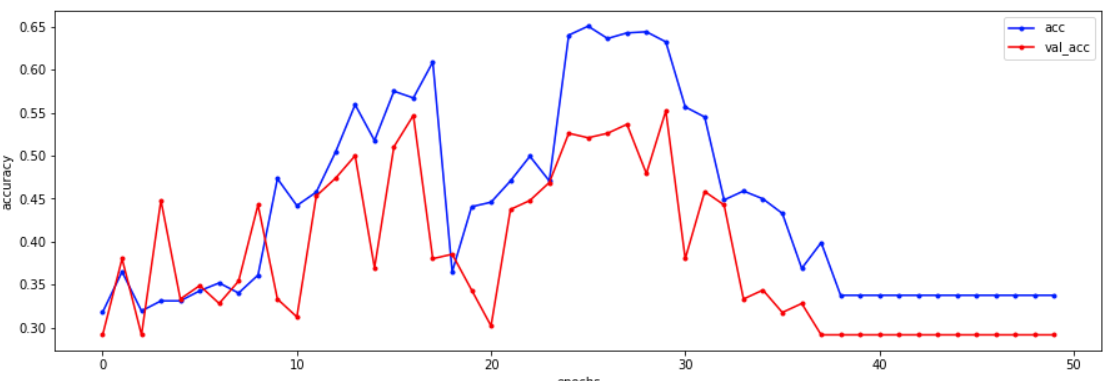
데이터들이 일정하지 않고 뒤죽박죽이라 학습결과도 좋지않다.
40회를 넘어서면 변화가 없는데 이 부분은 나중에 자동으로
학습을 멈추는 법을 알려주신다고 하셨다.

끄적끄적