DeepLearning_RNN_LSTM
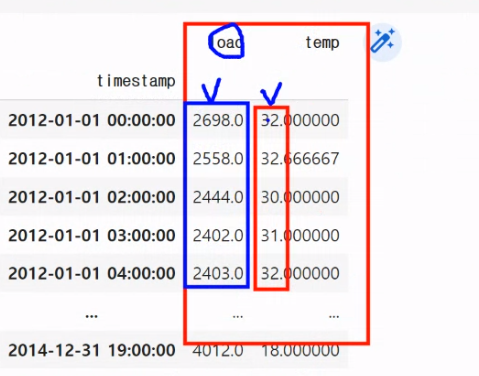
데이터 스케일링 사용하는 이유
기계 입장에서 봤을때 값의 차이가 너무 큼(중요도를 수치가 큰쪽에 잡아버릴수 있음)
데이터 컬럼별로 범위를 맞춰주기 위해
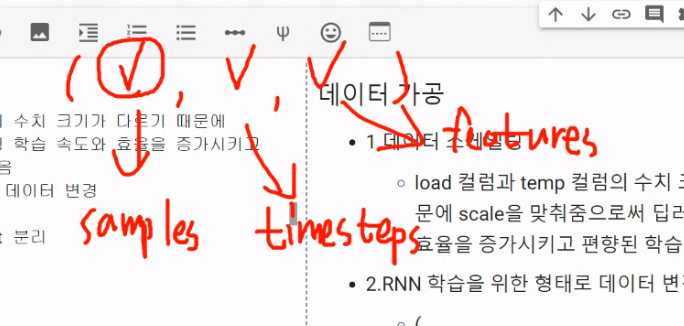
RNN에 넣기 위해 3개의 shape로 변경
MinMax 스케일링
- 값이 0에서 1사이로 모두 바뀜
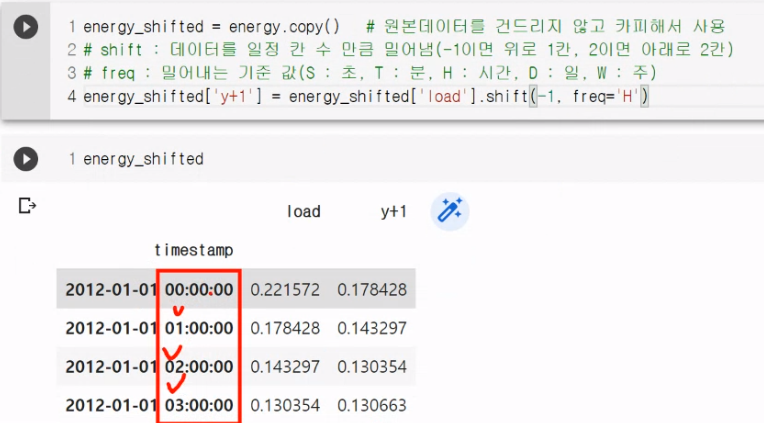
shift 함수: 데이터를 일정 칸 수 만큼 밀어냄
freq 함수 밀어내는 기준 값
데이터 시점들을 분리

shape에 features 항목을 추가하기! features = 1

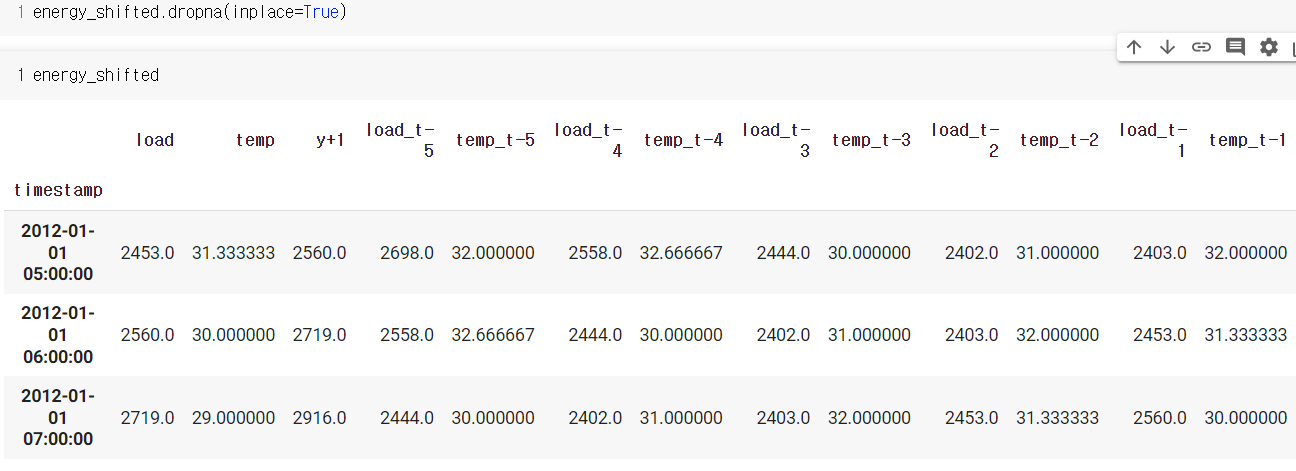
dropna 사용해 NaN값이 있는 행들 모두 제거

LSTM
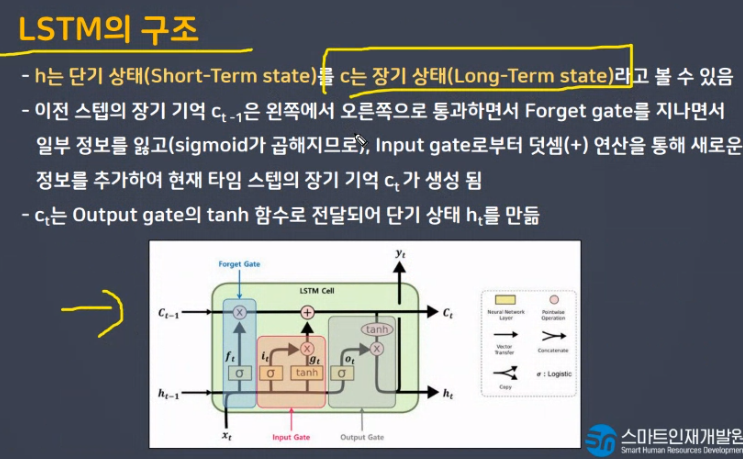
장기적으로 끌고가야할 데이터를 가지고 감
많은 연산들을 하게됨
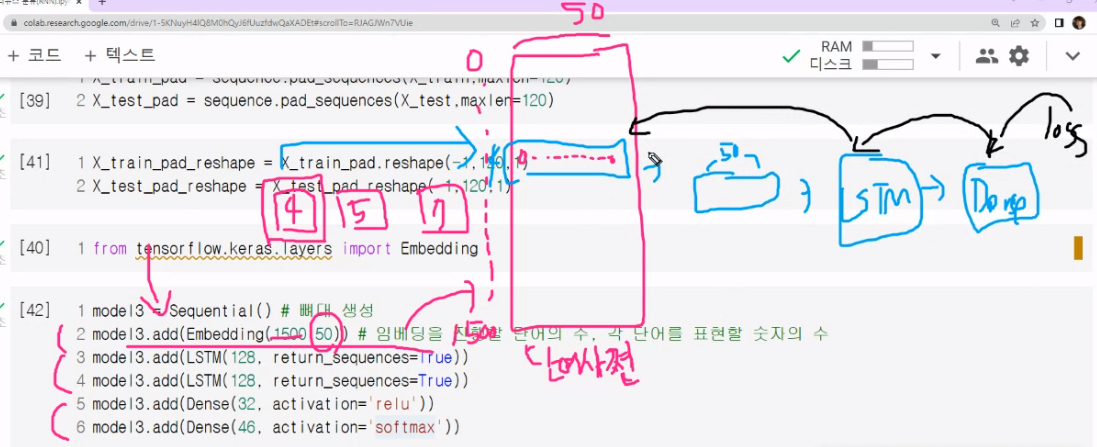
LSTM 도 여러층 쌓을 수 있음 하지만 그냥 쌓으면 안돌아감
다수입력 단일출력 기본구조

return_sequences=True 함수 사용

단어 관계 사이가 조절될 수 있도록 지원해줌
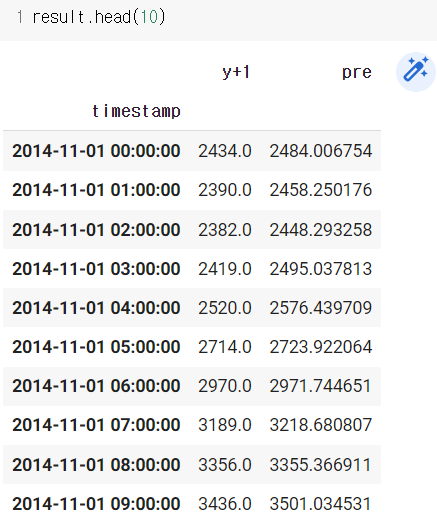
loss를 측정해 다시 수정이 일어남 이 작업이 계속 반복되면서
임베딩 레이어가 더 나은 숫자들을 업데이트 하게됨
-> 최적화가 이루어짐
!nvidia-smi colab에서 GPU 모델 확인
전이학습

끄적끄적