Image Captioning
glove 사전학습된 임베딩 데이터
text 사진에 대한 글자데이터 묶음
dataset 실제 사진들 묶음
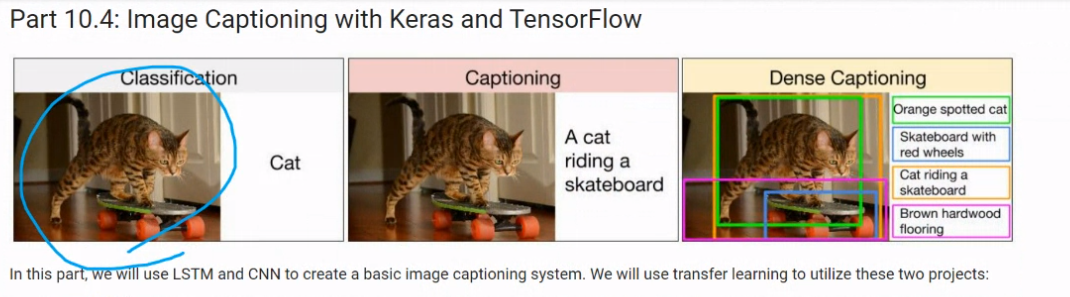
사진을 넣었을때 객체 확인 classification
captioning 객체에 대한 글자를 캡셔닝
Dense Captioning 객체들을 따로 캡셔닝
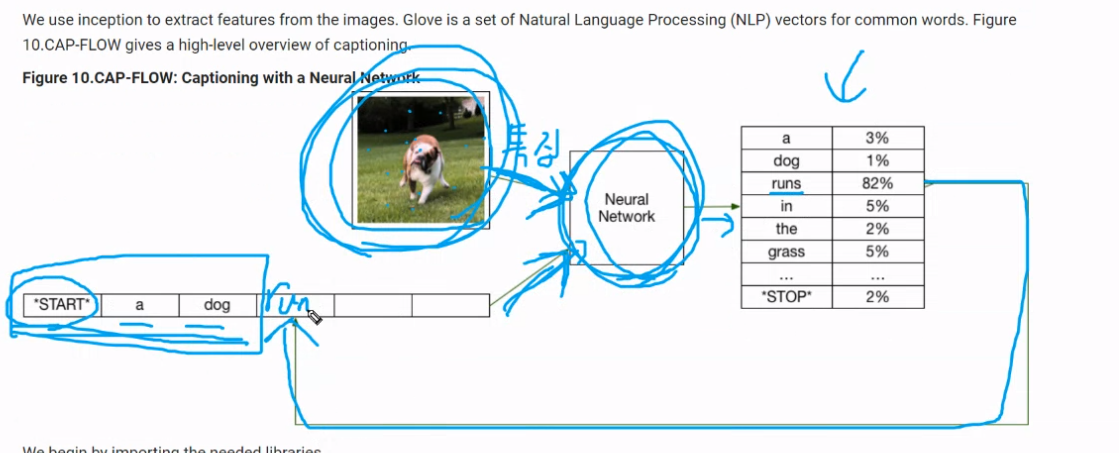
특징추출해서 학습망에 넣어줌 문장과 함께 그 다음 무슨 단어가 나올지 예측함
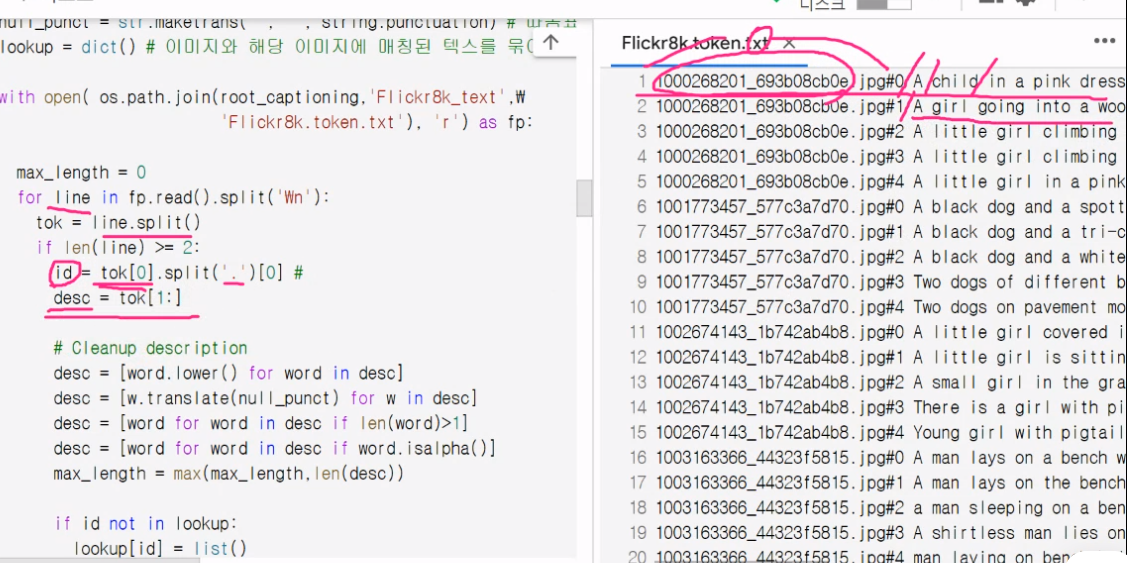
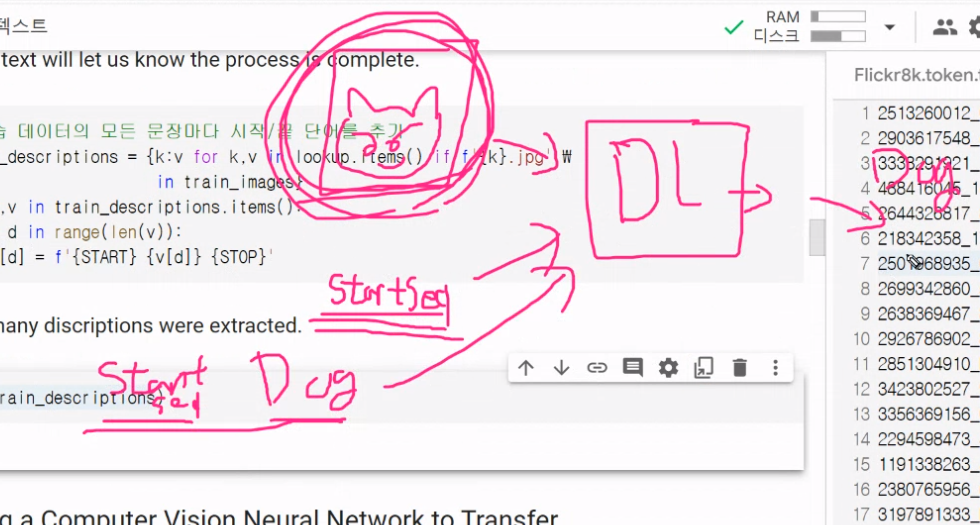

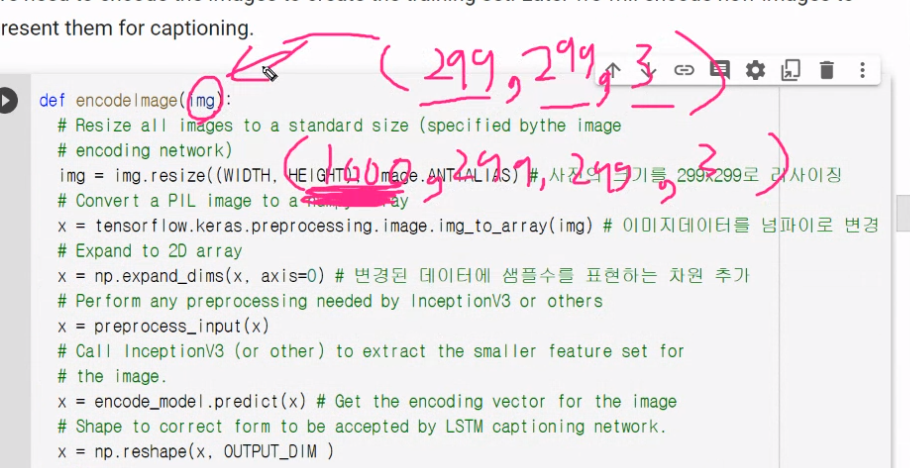
shape이 저렇게 입력됨
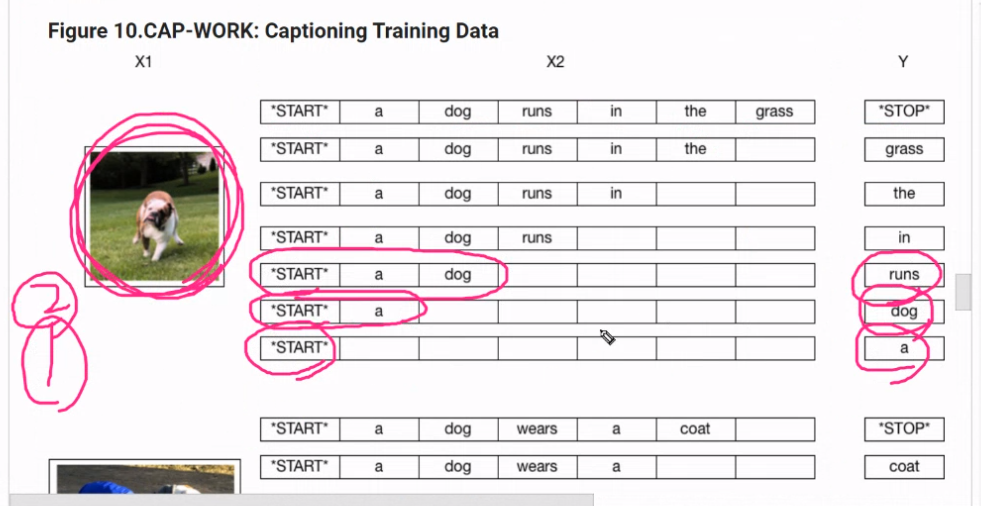
하나의 사진과 하나의 문장에 대해 샘플들을 여러개 만들어줌
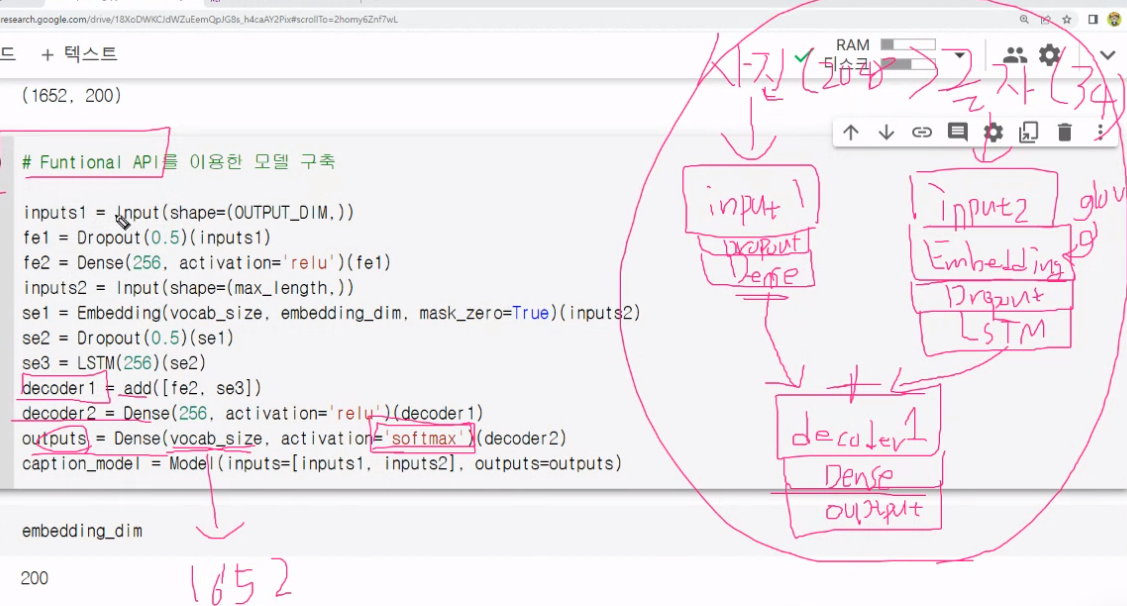
사진과 글자가 동시에 들어가는 모델

trainable = False
이미 사전에 학습된 임베딩 모델을 학습 못하게 함

끄적끄적