
🚨문제 상황
최근 사이드 프로젝트에서 크롤링 업무를 맡아서 제목, url, 댓글수, 작성일 등을 따오고 있다! 근데 제목을 딸 때 대부분 페이지의 제목은 a태그 안에 있기 때문에 title = search.find('a').get_text()로 긁어오면 바로 저장이 가능했다. 근데, 뽐뿌는 a태그 안에 <font>라는 태그로 댓글수를 알려주는 형태로 되어있어서 다른 처리가 필요한 상황이었다.
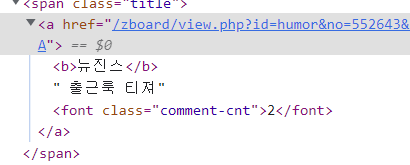

(귀엽네요....2222)
title = search.find('a').get_text() 이 코드를 슬행하면 아래와 같이 제목+댓글수까지 같이 크롤링이되는 것을 볼 수 있다.

🤔어떻게 해결해볼까
고민 1. contents를 이용해서 뒤에 font값만 제외하고 join 시키기
get_text()값은 찾은 태그값내에 모든 하위 태그(<b>,<font>, 등)을 제거하고 텍스트만 반환해줍니다.
하지만contents를 이용하면
[<b>뉴진스</b>, ' 출근룩 티져', <font class="comment-cnt">2</font>]이렇게 태그의 하위항목별로 나눠서 출력할 수 있습니다. 공식문서 설명
하지만 이렇게 출력하면 검색어에 blod처리를한 <b>태그가 포함되어 정규표현식이나 다른 방식으로 처리하는데 더 복잡해 질 것 같아 최후의 수단으로 미뤄둡니다...!
고민 2. 태그 사이에 있는 중간의 텍스트 얻기??
-
contents를 찾는 도중 태그 사이에 있는 중간의 텍스트를 얻을 수 있다는 방법을 찾아 사용해봤습니다! 관련 블로그
-
soup.제외태그.string를 하면 제외태그 사이에 있는 텍스트가 반환된다는 소문을 듣고 시도해봤습니다.# a 태그랑 font 태그 사이의 글을 찾아줘! print(search.find('a').font.get_text()) >>> 2 # ;; 그럼 span이랑 font 태그 사이 글을 찾아줘..! print(search.find('span').font.get_text()) >>> 2 # ;;; 그럼 span이랑 a태그 사이의 글...? print(search.find('span').a.get_text()) >> 뉴진스 출근룩 티져2휴,, 아무래도 font 태그가 a태그 안에 들어가있어서
</a>이렇게 닫히지 않았기때문에 분리가 안되는 것 같다.
✨고민 3. decompose()를 이용해 관련 태그 없애기 (이걸로 해결)✨
- 블로그를 서칭하다 나와 비슷한 상황을 찾았다! 해당 블로그
decompose()는 하위 태그 관련 contents를 다 삭제하는 함수다 공식블로그 설명- 그럼 시작해볼까? 먼저 블로그에
search.select_one('a').font.decompose().text를 하면 바로 출력이 된다고 되어있었는데, 직접 해보니
이라는 NoneType object는 text를 지원하지않는다는 오류가 나온다.print(search.select_one('a').font.decompose().text) >>> AttributeError: 'NoneType' object has no attribute 'text'.text없이 출력하니None이 반환됐다.
해당 함수는 없애는 용도만 있고, 값을 반환하려면 다시 그 상위 태그로 가서 출력해야한다. - 근데 여기서 문제는, 저
<font>값을 지우면 뒤에 댓글수를 불러올 수 없다.
👉 그래서 먼저<font>값을 저장하고, 지운뒤<a>태그 값을 출력하는 식으로 순서를 바꿔 진행했다.
🥰완성 Code
# 앞 파싱 내용 생략!
# BeautifulSoup_html을 Parsing 함
soup = BeautifulSoup(driver.page_source, 'html.parser')
search_in_commu = soup.find_all('div', class_="content")
for search in search_in_commu:
comment_num = search.find('font', class_ = 'comment-cnt').get_text()
search.find('a').font.decompose()
title = search.find('a').get_text()
url = f"https://www.ppomppu.co.kr{search.find('a')['href']}"
date = search.find('p', class_ = 'desc').select_one('span:nth-child(3)').string.split('.')
date = '-'.join(date) # yyyy-mm-dd 형식 맞춤
print(title, url, date, comment_num)
>>> 뉴진스 출근룩 티져 https://www.ppomppu.co.kr/zboard/view.php?id=humor&no=552643&keyword=%B4%BA%C1%F8%BD%BA 2023-02-28 2
...
크롤링이 점점 손에 익어가는 듯 하다^)^ 뿌듯하구만!
뷰티풀숩에 생각보다 다양한 함수들이 있어 잘 이용하면 거의 무적일 것 같다ㅋㅋㅋ
얼른 크롤링 끝내고 MySQL에 저장까지 가보자고~

차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)