
최근 프로젝트에서 Elasticsearch에 Bulk data를 넣는 일을 하고 있는데, 하면서 생긴 trouble issue를 정리한다.
- 상황 : SCV파일 -> bulk JSON화 -> Elasticsearch 입력
데이터:
elasticsearch하시는분은 아시겠지만 이것보다 좋은 방법이 있었죠...또륵
1. JSON 형태 오류
-
발생 오류
{"error":{"root_cause":[{"type":"json_e_o_f_exception","reason":"Unexpected end-of-input: expected close marker for Object (start marker at [Source: (ByteArrayInputStream); line: 1, column: 1])\n at [Source: (ByteArrayInputStream); line: 1, column: 2]"}],"type":"json_e_o_f_exception","reason":"Unexpected end-of-input: expected close marker for Object (start marker at [Source: (ByteArrayInputStream); line: 1, column: 1])\n at [Source: (ByteArrayInputStream); line: 1, column: 2]"},"status":400}
여러 강의들을 참고하며 Bulk 예시를 보고 형태를 맞춰 넣기로 생각함
- 예시 파일
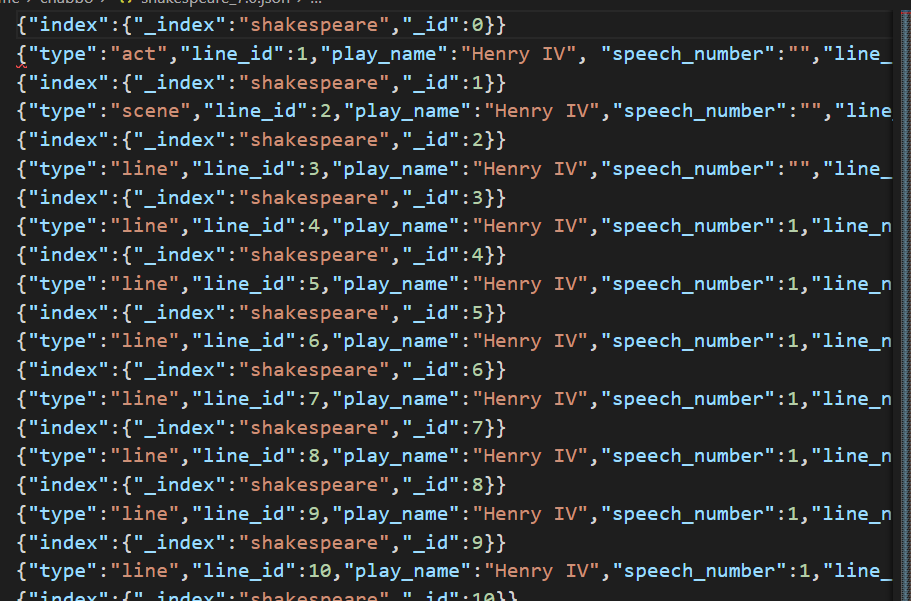
오호라{index:~~~} {내용~~~}형식의 JSON 파일을 만들면 되는구나!

뚝딱뚝딱
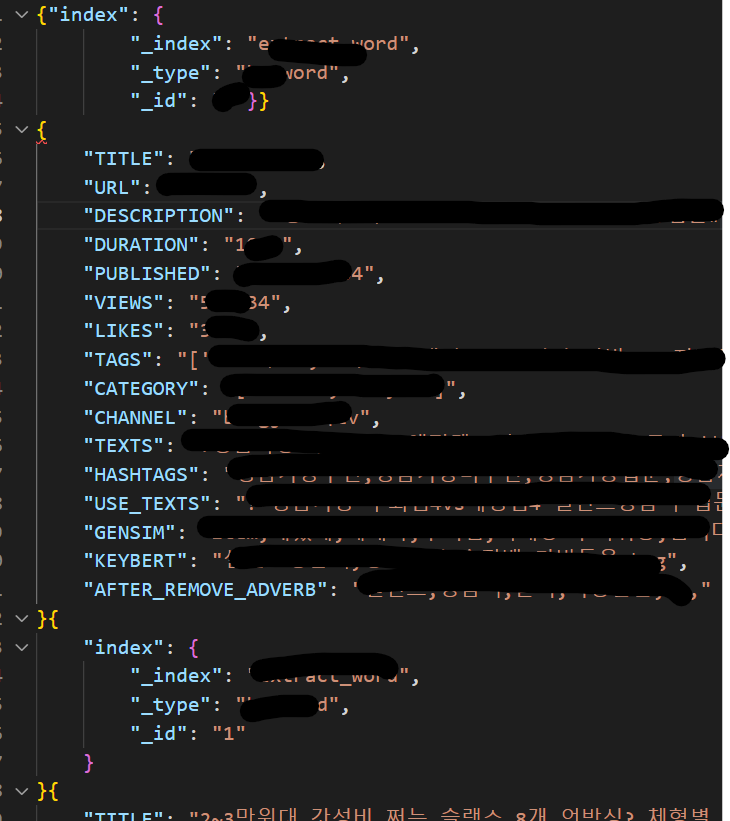
예쁘게 만들었는데 오류남....ㅎㅎㅎㅎ
이개외않되...... 로 1주일을 보냈다....
여기저기 오픈카톡방에서도 물어보고 페이스북에서도 물어보고 했으나 형태가 같은데 왜....안돼....???? 라고 하다....
마사카...? JSON 형태를 따지는거야...?
라고 생각해서 형태까지 고대로 따서 2개만 넣어서 흘려봤다..
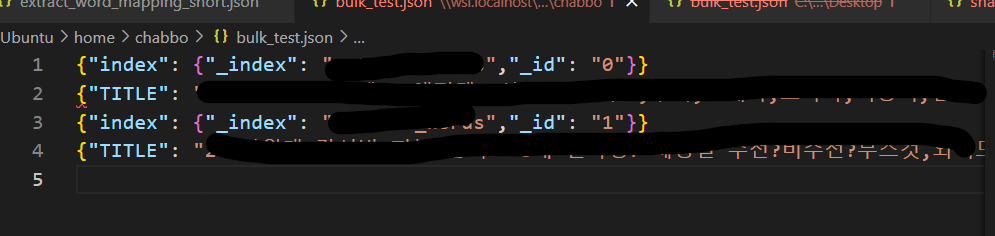

그래.... 이거였구나....?
- 예시 파일
그래서 결론!
bulk로 POST한다면 JSON의 형태가 아닌 줄을 맞춰줘야한다...!
- 덧)
- 이 형식으로 넣어준다면 먼저 mapping json을 넣어주던지, index를 만들어서 요기에 넣을거라도 말해줘야한다.
그렇지 않고 먼저 bulk 데이터 먼저 때려넣으면 successful이라고하지만 보내긴 했는데 index가 없어서 저장을 못하는 상태가 됨...
index_not_found_exception - 또 위에 보이지만 마지막 줄에도
/n빈 한줄을 넣어줘야한다.
(참고블로그)
2. 사실 이것보다 더 쉬운 방법이 있어..ㅎ...
How to Index Elasticsearch Documents with the Bulk API in Python
Python의 API를 이용해 JSON 형태를 만들지 않고도 DataFrame or list 째로 보낼 수 있다^_^.......
# elasticsearch의 helpers import
from elasticsearch import Elasticsearch, helpers
# ES에 벌크로 보낼 데이터를 담을 리스트
docs = []
# 리스트에 데이터 넣음
for num in range(10):
docs.append({
'_index': '인텍스 이름',
'_source': {
"category": "test"
"c_key": "test"
"status": "test"
"price": 1111
}
})
# helpers.bulk 함수를 통해 bulk 데이터 ES에 input..
helpers.bulk(es, docs)헤헤...
왜 이제 봤을까...ㅎㅎ
무튼 내일 이걸로 해서 시도해봐야겠다. 이방법이면 AWS lambda 함수를 이용해서 배치로 넣어주면 바로 ES 저장까지 할 수 있지않을까?
배운 점
- JSON이라고 사람이 보기 좋게 만들고 컴퓨터한테 이해하라고 하지말고,, 형태를 맞춰주자...
- 하나의 방식만 고집해서 찾지말고 시각을 넓게 보자. 더 쉽고 간결하게 할 수 있는 방법이 무조건 있다.
