
개별로 로우 업로드
-- user role select
use role sysadmin;
-- create tabelROOT_DEPTH
create or replace table GARDEN_PLANTS.VEGGIES.ROOT_DEPTH (
ROOT_DEPTH_ID number(1),
ROOT_DEPTH_CODE text(1),
ROOT_DEPTH_NAME text(7),
UNIT_OF_MEASURE text(2),
RANGE_MIN number(2),
RANGE_MAX number(2)
);
INSERT INTO ROOT_DEPTH (
ROOT_DEPTH_ID ,
ROOT_DEPTH_CODE ,
ROOT_DEPTH_NAME ,
UNIT_OF_MEASURE ,
RANGE_MIN ,
RANGE_MAX
)
VALUES
(
1,
'S',
'Shallow',
'cm',
30,
45
);
-- 행 추가
INSERT INTO ROOT_DEPTH (
ROOT_DEPTH_ID ,
ROOT_DEPTH_CODE ,
ROOT_DEPTH_NAME ,
UNIT_OF_MEASURE ,
RANGE_MIN ,
RANGE_MAX
)
VALUES
(
2,
'M',
'Medium',
'cm',
45,
60
);
INSERT INTO ROOT_DEPTH (
ROOT_DEPTH_ID ,
ROOT_DEPTH_CODE ,
ROOT_DEPTH_NAME ,
UNIT_OF_MEASURE ,
RANGE_MIN ,
RANGE_MAX
)
VALUES
(
3,
'D',
'Deep',
'cm',
60,
90
);
select * from ROOT_DEPTH;CSV파일 업로드
- 사용 가능한 CSV파일 형식
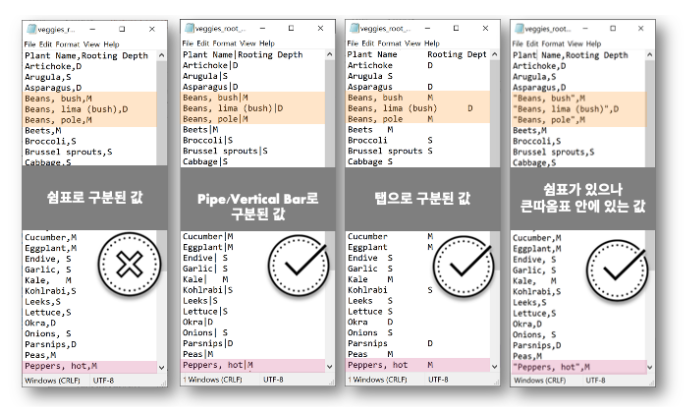
- 해당 파일 형식에 맞춰서 load 형식을 생성해준다 (이건 아직까지 예전 UI에만 존재한다고 함)

- 테이블 생성
-- 먼저 table을 생성
create table vegetable_details
(
plant_name varchar(25)
, root_depth_code varchar(1)
);
select * from vegetable_details-
DB에서 테이블을 선택, 업로드할 데이터를 올리고, 미리 생성해 놓은 데이터 포맷을 눌러 데이터를 로딩한다.
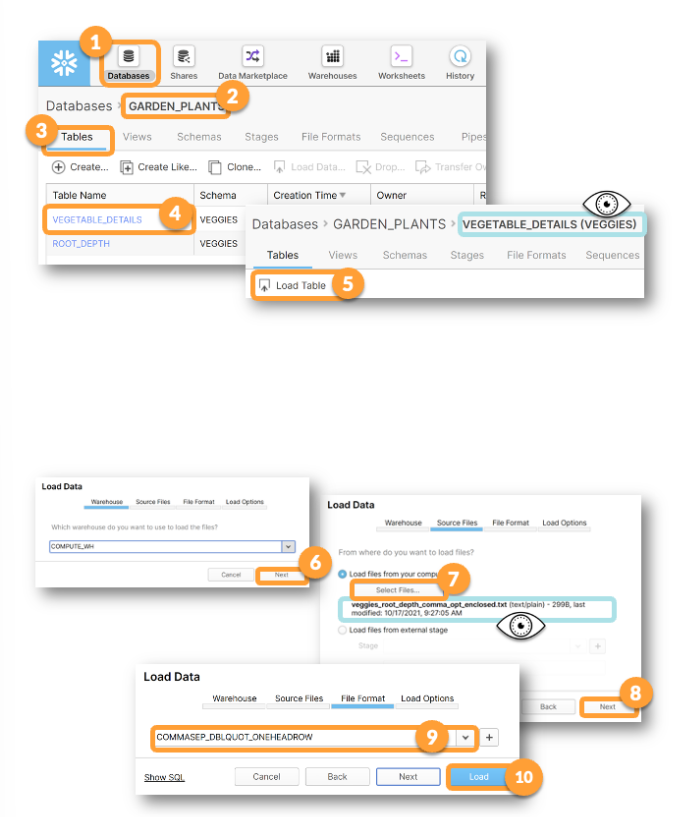
- 주의 사항 : 헤더 유무, 데이터 형식 재확인
-
다시 워크시트로 돌아가서 데이터를 확인한다.
select * from vegetable_details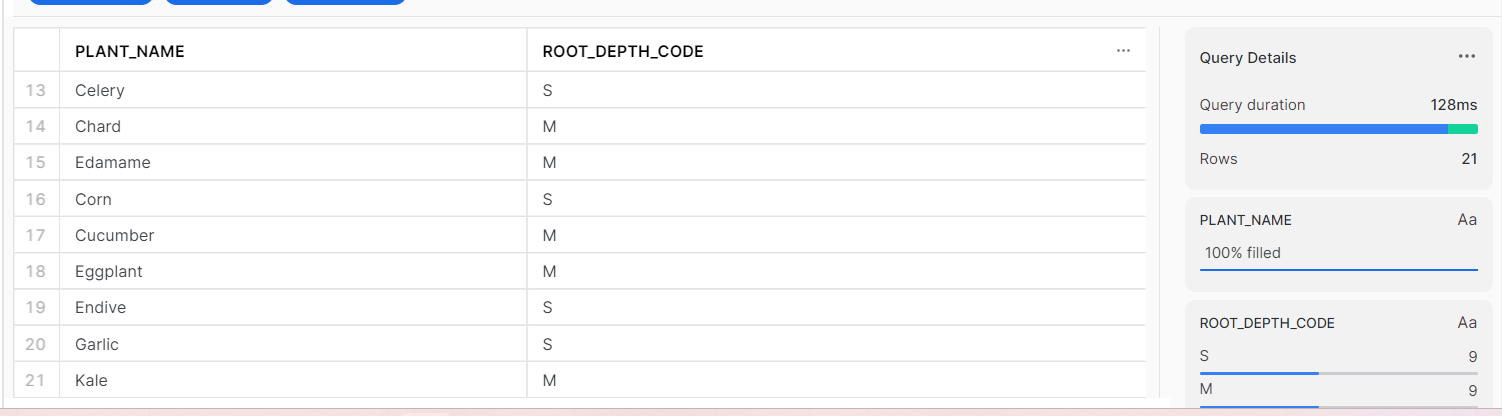
S3버킷에서 가져오기
이때 stage를 사용하게 되는데, 이는 실제 파일을 불러오는 것이 아니라 해당 파일의 위치를 Snowflake에 알려주는 것이다! 이를 통해 파일을 더 쉽게 불러올 수 있다.
-
트라이얼에선 이미 생성되어 있는
uni-lab-files버킷의 데이터를 불러오기로 한다 -
GUI를 이용한 S3버킷 선택
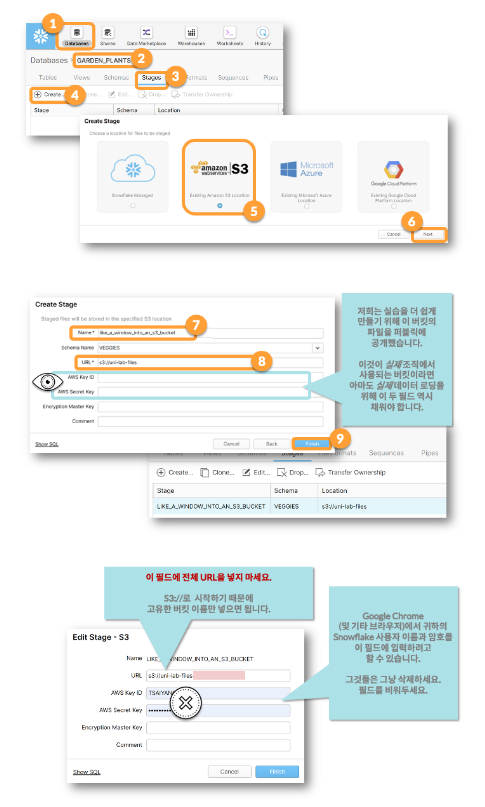
-
sql문을 이용한 S3 버킷 선택 및 list로 파일 확인
-- 스테이지 생성
create or replace stage like_a_window_into_an_s3_bucket url = 's3://uni-lab-files';
-- 스테이지상 리스트 확인 list @like_a_window_into_an_s3_bucket; 로 사용해도 확인 가능(대소문자 구분X)
list @like_a_window_INTO_an_s3_bucket; Snowflake에서는 대소문자를 구분하지 않지만, S3버킷의 데이터에선 대소문자가 구분되어 있기 때문에 확인을 잘 해야한다.

- 토양 데이터 불러오기
워크시트에서 실행할 수 있는 COPY INTO 문을 사용해 데이터를 로딩한다.
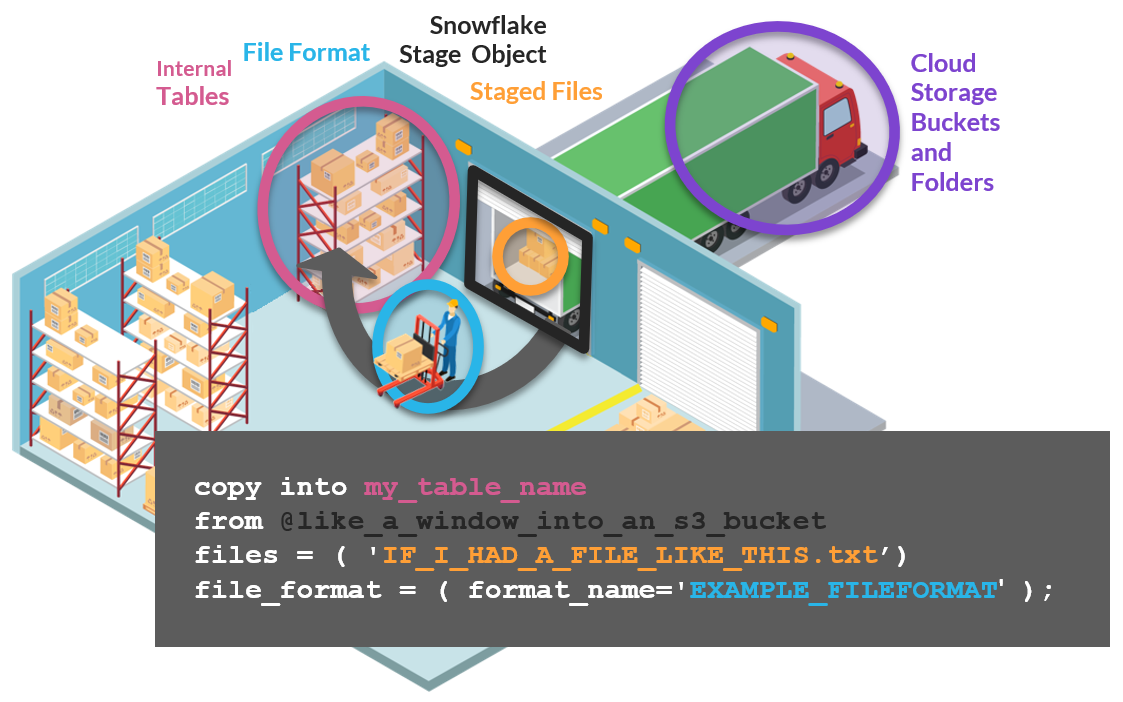
-- 테이블 생성 (veggies 테이블 선택 확인)
create or replace table vegetable_details_soil_type
( plant_name varchar(25)
,soil_type number(1,0)
);
-- 생성한 테이블에 스테이지에 있는 데이터를 로딩
copy into vegetable_details_soil_type
from @like_a_window_into_an_s3_bucket
files = ( 'VEG_NAME_TO_SOIL_TYPE_PIPE.txt')
file_format = ( format_name=PIPECOLSEP_ONEHEADROW );
-- 데이터 로딩 확인
select * from vegetable_details_soil_type-
데이터의 유형에 따라 파일포맷을 적절하게 바꿔줘야한다
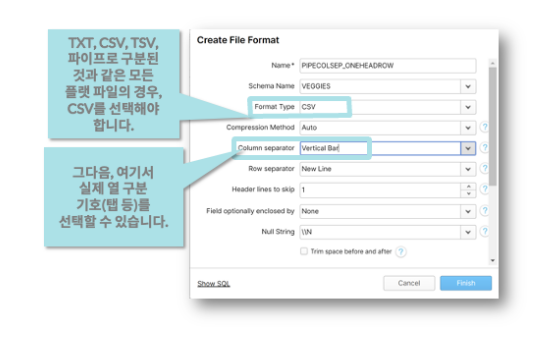
-
데이터보고 로드해오기 실습
일반적인 csv 파일 포맷
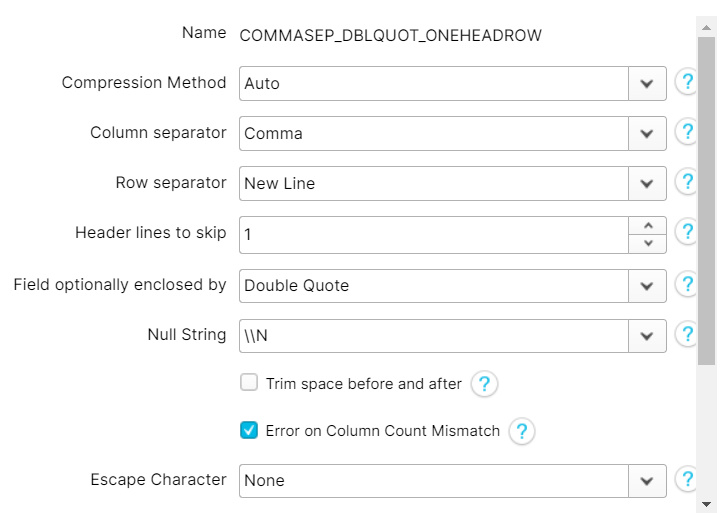
create or replace table VEGETABLE_DETAILS_PLANT_HEIGHT(
plant_name varchar(75),
UOM varchar(4),
Low_End_of_Range number,
High_End_of_Range number
);
copy into VEGETABLE_DETAILS_PLANT_HEIGHT
from @like_a_window_into_an_s3_bucket
files = ( 'veg_plant_height.csv')
file_format = ( format_name=COMMASEP_DBLQUOT_ONEHEADROW );
select * from VEGETABLE_DETAILS_PLANT_HEIGHT;다대다를 위한 테이블 형성
한권의 책에 여러 저자가 있거나, 하나의 저자가 여러권의 책을 작성했다는 가정을 통해 다대다 테이블을 만들어 매칭해보자!
use role sysadmin;
// Create a new database and set the context to use the new database
CREATE DATABASE LIBRARY_CARD_CATALOG COMMENT = 'DWW Lesson 9 ';
USE DATABASE LIBRARY_CARD_CATALOG;
// Create and Author table
CREATE OR REPLACE TABLE AUTHOR (
AUTHOR_UID NUMBER
,FIRST_NAME VARCHAR(50)
,MIDDLE_NAME VARCHAR(50)
,LAST_NAME VARCHAR(50)
);
// Insert the first two authors into the Author table
INSERT INTO AUTHOR(AUTHOR_UID,FIRST_NAME,MIDDLE_NAME, LAST_NAME)
Values
(1, 'Fiona', '','Macdonald')
,(2, 'Gian','Paulo','Faleschini');
// Look at your table with it's new rows
SELECT *
FROM AUTHOR;- 추가 데이터시 시퀀스를 이용해 넘버링
use role sysadmin;
// Create a new database and set the context to use the new database 데이터베이스 생성
CREATE DATABASE LIBRARY_CARD_CATALOG COMMENT = 'DWW Lesson 9 ';
-- 디비 사용 가능하게 열어놈
USE DATABASE LIBRARY_CARD_CATALOG;
// Create and Author table
CREATE OR REPLACE TABLE AUTHOR (
AUTHOR_UID NUMBER
,FIRST_NAME VARCHAR(50)
,MIDDLE_NAME VARCHAR(50)
,LAST_NAME VARCHAR(50)
);
// Insert the first two authors into the Author table
INSERT INTO AUTHOR(AUTHOR_UID,FIRST_NAME,MIDDLE_NAME, LAST_NAME)
Values
(1, 'Fiona', '','Macdonald')
,(2, 'Gian','Paulo','Faleschini');
// Look at your table with it's new rows
SELECT *
FROM AUTHOR;
use role sysadmin;
//Drop and recreate the counter (sequence) so that it starts at 3
// then we'll add the other author records to our author table
-- 시퀀스 생성 시퀀스 명, 스타트, 증가스텝
CREATE OR REPLACE SEQUENCE "LIBRARY_CARD_CATALOG"."PUBLIC"."SEQ_AUTHOR_UID"
START 3
INCREMENT 1
COMMENT = 'Use this to fill in the AUTHOR_UID every time you add a row';
//Add the remaining author records and use the nextval function instead
//of putting in the numbers
INSERT INTO AUTHOR(AUTHOR_UID,FIRST_NAME,MIDDLE_NAME, LAST_NAME)
Values
(SEQ_AUTHOR_UID.nextval, 'Laura', 'K','Egendorf')
,(SEQ_AUTHOR_UID.nextval, 'Jan', '','Grover')
,(SEQ_AUTHOR_UID.nextval, 'Jennifer', '','Clapp')
,(SEQ_AUTHOR_UID.nextval, 'Kathleen', '','Petelinsek');
-- 데이터 확인
SELECT *
FROM AUTHOR;
---- 이제 Book 관련 디비로 넘어감
-- DB 초이스
USE DATABASE LIBRARY_CARD_CATALOG;
// Create a new sequence, this one will be a counter for the book table
CREATE OR REPLACE SEQUENCE "LIBRARY_CARD_CATALOG"."PUBLIC"."SEQ_BOOK_UID"
START 1
INCREMENT 1
COMMENT = 'Use this to fill in the BOOK_UID everytime you add a row';
-- Book 테이블 생성
// Create the book table and use the NEXTVAL as the
// default value each time a row is added to the table
CREATE OR REPLACE TABLE BOOK
( BOOK_UID NUMBER DEFAULT SEQ_BOOK_UID.nextval
,TITLE VARCHAR(50)
,YEAR_PUBLISHED NUMBER(4,0)
);
-- data input
// Insert records into the book table
// You don't have to list anything for the
// BOOK_UID field because the default setting
// will take care of it for you
INSERT INTO BOOK(TITLE,YEAR_PUBLISHED)
VALUES
('Food',2001)
,('Food',2006)
,('Food',2008)
,('Food',2016)
,('Food',2015);
-- 다대다 관계 맺어주는 테이블 생성
// Create the relationships table
// this is sometimes called a "Many-to-Many table"
CREATE TABLE BOOK_TO_AUTHOR
( BOOK_UID NUMBER
,AUTHOR_UID NUMBER
);
//Insert rows of the known relationships
INSERT INTO BOOK_TO_AUTHOR(BOOK_UID,AUTHOR_UID)
VALUES
(1,1) // This row links the 2001 book to Fiona Macdonald
,(1,2) // This row links the 2001 book to Gian Paulo Faleschini
,(2,3) // Links 2006 book to Laura K Egendorf
,(3,4) // Links 2008 book to Jan Grover
,(4,5) // Links 2016 book to Jennifer Clapp
,(5,6);// Links 2015 book to Kathleen Petelinsek
-- 테이블 쪼인
//Check your work by joining the 3 tables together
//You should get 1 row for every author
select *
from book_to_author ba
join author a
on ba.author_uid = a.author_uid
join book b
on b.book_uid=ba.book_uid; XML 파일 로드!
이번엔 sql문으로 파일포맷을 만들어 업로드하자
// Create an Ingestion Table for XML Data
CREATE TABLE LIBRARY_CARD_CATALOG.PUBLIC.AUTHOR_INGEST_XML
(
"RAW_AUTHOR" VARIANT
);
//Create File Format for XML Data
CREATE FILE FORMAT LIBRARY_CARD_CATALOG.PUBLIC.XML_FILE_FORMAT
TYPE = 'XML'
COMPRESSION = 'AUTO'
PRESERVE_SPACE = FALSE
STRIP_OUTER_ELEMENT = FALSE
DISABLE_SNOWFLAKE_DATA = FALSE
DISABLE_AUTO_CONVERT = FALSE
IGNORE_UTF8_ERRORS = FALSE; - 해더가 있는 경우, 없는 경우를 나눠 로드할 수 있다
<dataset>태그와</dataset>태그를 제거하면 문제가 해결되지만, 로드하려는 모든 XML 파일에 대해 이와 같은 작업을 수행하는 것은 귀찮기 때문에,,, 해당 작업으로 진행해준다ㅋㅋ
-- 테이블 생성
// Create an Ingestion Table for XML Data
CREATE TABLE
LIBRARY_CARD_CATALOG.PUBLIC.AUTHOR_INGEST_XML
(
"RAW_AUTHOR" VARIANT
);
-- 파일 포맷 생성 (Classic Console에서 GUI로 생성가능)
//Create File Format for XML Data
CREATE FILE FORMAT LIBRARY_CARD_CATALOG.PUBLIC.XML_FILE_FORMAT
TYPE = 'XML'
COMPRESSION = 'AUTO'
PRESERVE_SPACE = FALSE
STRIP_OUTER_ELEMENT = FALSE
DISABLE_SNOWFLAKE_DATA = FALSE
DISABLE_AUTO_CONVERT = FALSE
IGNORE_UTF8_ERRORS = FALSE;
-- Classic Console에서 데이터 업로드
-- 데이터 확인
select * from LIBRARY_CARD_CATALOG.PUBLIC.AUTHOR_INGEST_XML
-- XML 쿼리 날리기 ($표시시 뷰로 볼 수 있음?)
//Returns entire record
SELECT raw_author
FROM author_ingest_xml;
// Presents a kind of meta-data view of the data
SELECT raw_author:"$"
FROM author_ingest_xml;
//shows the root or top-level object name of each row
-- @는 Top-level 확인
SELECT raw_author:"@"
FROM author_ingest_xml;
//returns AUTHOR_UID value from top-level object's attribute
SELECT raw_author:"@AUTHOR_UID"
FROM author_ingest_xml;
//returns value of NESTED OBJECT called FIRST_NAME
SELECT XMLGET(raw_author, 'FIRST_NAME'):"$"
FROM author_ingest_xml;
//returns the data in a way that makes it look like a normalized table
SELECT
raw_author:"@AUTHOR_UID" as AUTHOR_ID
,XMLGET(raw_author, 'FIRST_NAME'):"$" as FIRST_NAME
,XMLGET(raw_author, 'MIDDLE_NAME'):"$" as MIDDLE_NAME
,XMLGET(raw_author, 'LAST_NAME'):"$" as LAST_NAME
FROM AUTHOR_INGEST_XML;
//add ::STRING to cast the values into strings and get rid of the quotes
SELECT
raw_author:"@AUTHOR_UID" as AUTHOR_ID
,XMLGET(raw_author, 'FIRST_NAME'):"$"::STRING as FIRST_NAME
,XMLGET(raw_author, 'MIDDLE_NAME'):"$"::STRING as MIDDLE_NAME
,XMLGET(raw_author, 'LAST_NAME'):"$"::STRING as LAST_NAME
FROM AUTHOR_INGEST_XML;
JSON 파일 업로드
use role sysadmin;
//Create a new database to hold the Twitter file
CREATE DATABASE SOCIAL_MEDIA_FLOODGATES
COMMENT = 'There\'s so much data from social media - flood warning';
USE DATABASE SOCIAL_MEDIA_FLOODGATES;
//Create a table in the new database
CREATE TABLE SOCIAL_MEDIA_FLOODGATES.PUBLIC.TWEET_INGEST
("RAW_STATUS" VARIANT)
COMMENT = 'Bring in tweets, one row per tweet or status entity';
-- JSON 업로드를 위한 DB 생성
//Create a JSON file format in the new database
CREATE FILE FORMAT SOCIAL_MEDIA_FLOODGATES.PUBLIC.JSON_FILE_FORMAT
TYPE = 'JSON'
COMPRESSION = 'AUTO'
ENABLE_OCTAL = FALSE
ALLOW_DUPLICATE = FALSE
STRIP_OUTER_ARRAY = TRUE
STRIP_NULL_VALUES = FALSE
IGNORE_UTF8_ERRORS = FALSE;
-- JSON 파일 업로드
-- 데이터 확인
-- 이것도 가능함
select * from TWEET_INGEST
//select statements as seen in the video
SELECT RAW_STATUS
FROM TWEET_INGEST;
SELECT RAW_STATUS:entities
FROM TWEET_INGEST;
SELECT RAW_STATUS:entities:hashtags
FROM TWEET_INGEST;
//Explore looking at specific hashtags by adding bracketed numbers
//This query returns just the first hashtag in each tweet
SELECT RAW_STATUS:entities:hashtags[0].text
FROM TWEET_INGEST;
//This version adds a WHERE clause to get rid of any tweet that
//doesn't include any hashtags
SELECT RAW_STATUS:entities:hashtags[0].text
FROM TWEET_INGEST
WHERE RAW_STATUS:entities:hashtags[0].text is not null;
//Perform a simple CAST on the created_at key
//Add an ORDER BY clause to sort by the tweet's creation date
-- SELECT RAW_STATUS:created_at::DATE 데이트 형식으로 CAST 하는 것 까지
SELECT RAW_STATUS:created_at::DATE
FROM TWEET_INGEST
create or replace view SOCIAL_MEDIA_FLOODGATES.PUBLIC.HASHTAGS_NORMALIZED as
(SELECT RAW_STATUS:user:id AS USER_ID
,RAW_STATUS:id AS TWEET_ID
,value:text::VARCHAR AS HASHTAG_TEXT
FROM TWEET_INGEST
,LATERAL FLATTEN
(input => RAW_STATUS:entities:hashtags)
);이렇게하고 DORA언니한테 검사맡으면 끝!



차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)