
EDA로 분석가 공고 파헤치기
1. Bigquery
- 장점 : 클라우딩 플랫폼(설치필요없음), 2단계 인증으로 데이터 보호 가능, 타 구글 플랫폼과 연동 용이, 속도, 저렴한 가격
- 단점 : 수시로 데이터를 업데이트 해야하는 경우 부적함(OLTP) (Ex. 실시간 데이터 처리 X. 하루 한번씩 업데이트하는 식)
빅쿼리 가입하기
난 이미 예전에 무료버전을 사용해서 바로 콘솔창으로 이동!
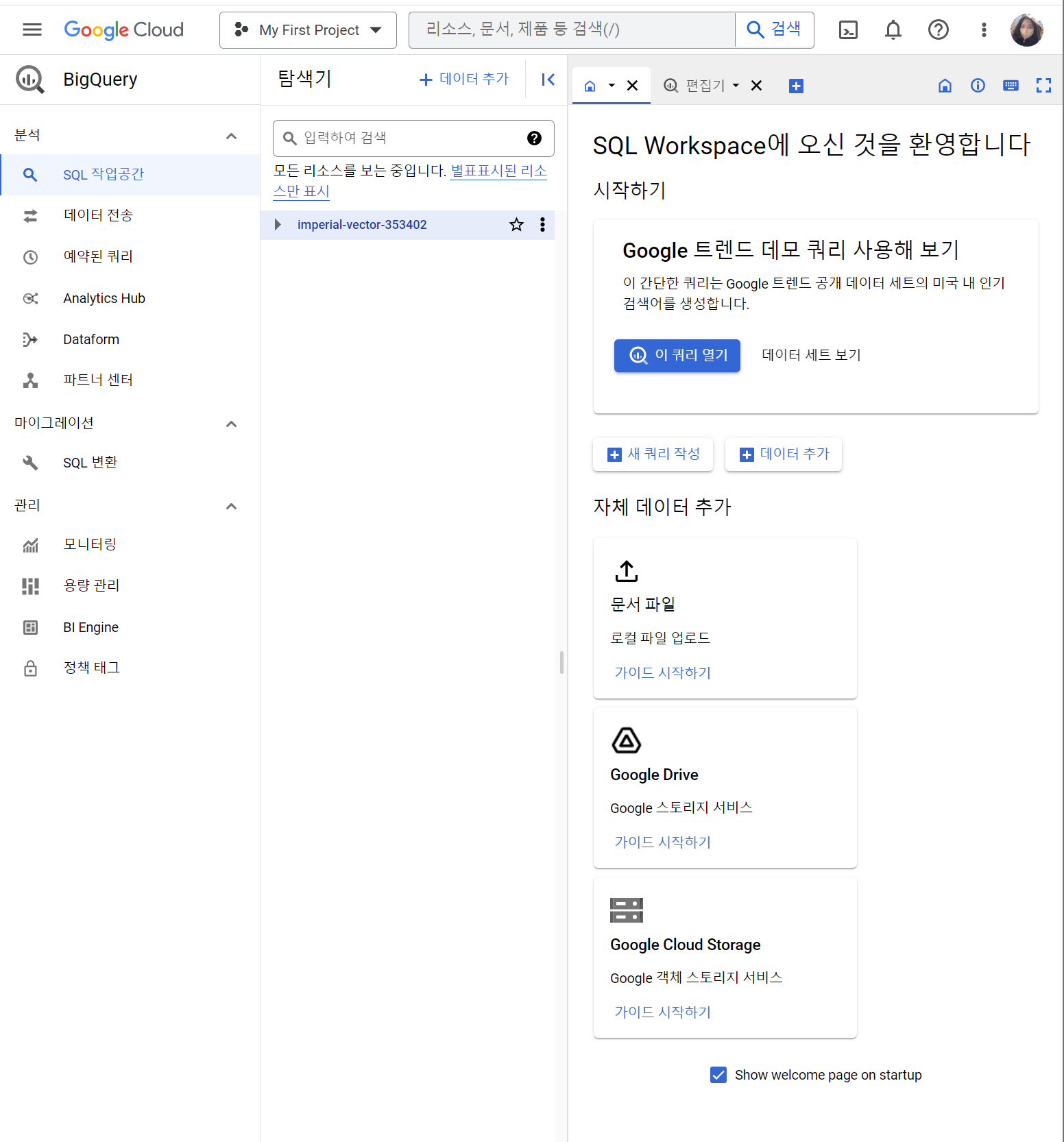
Google Trend 데모 쿼리를 사용해보면 만들어진 데이터로 쿼리를 날려보며 연습해볼 수 있다.
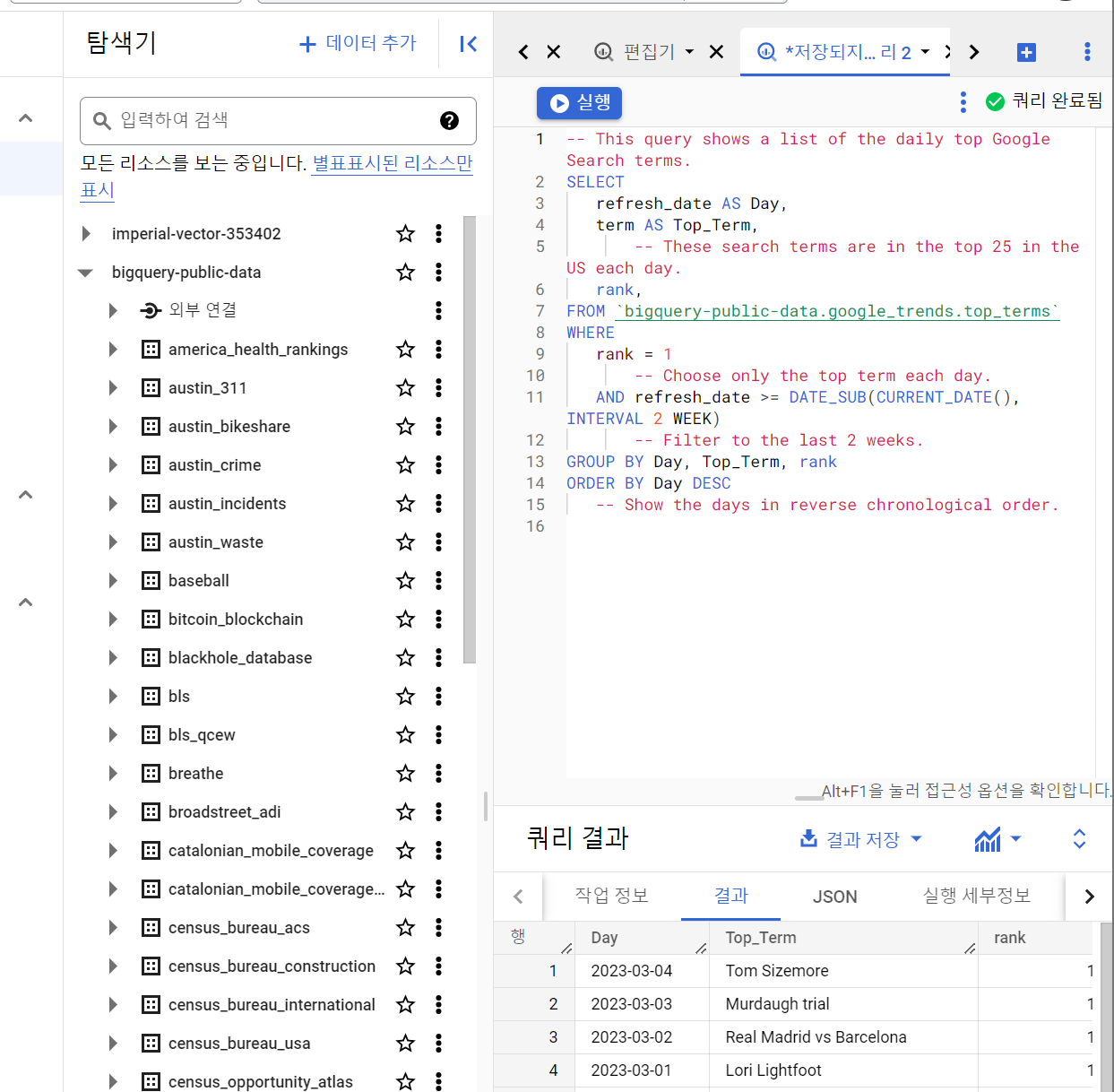
Table 만들기
데이터 세트 : 테이블들이 들어가는 곳(like folder)
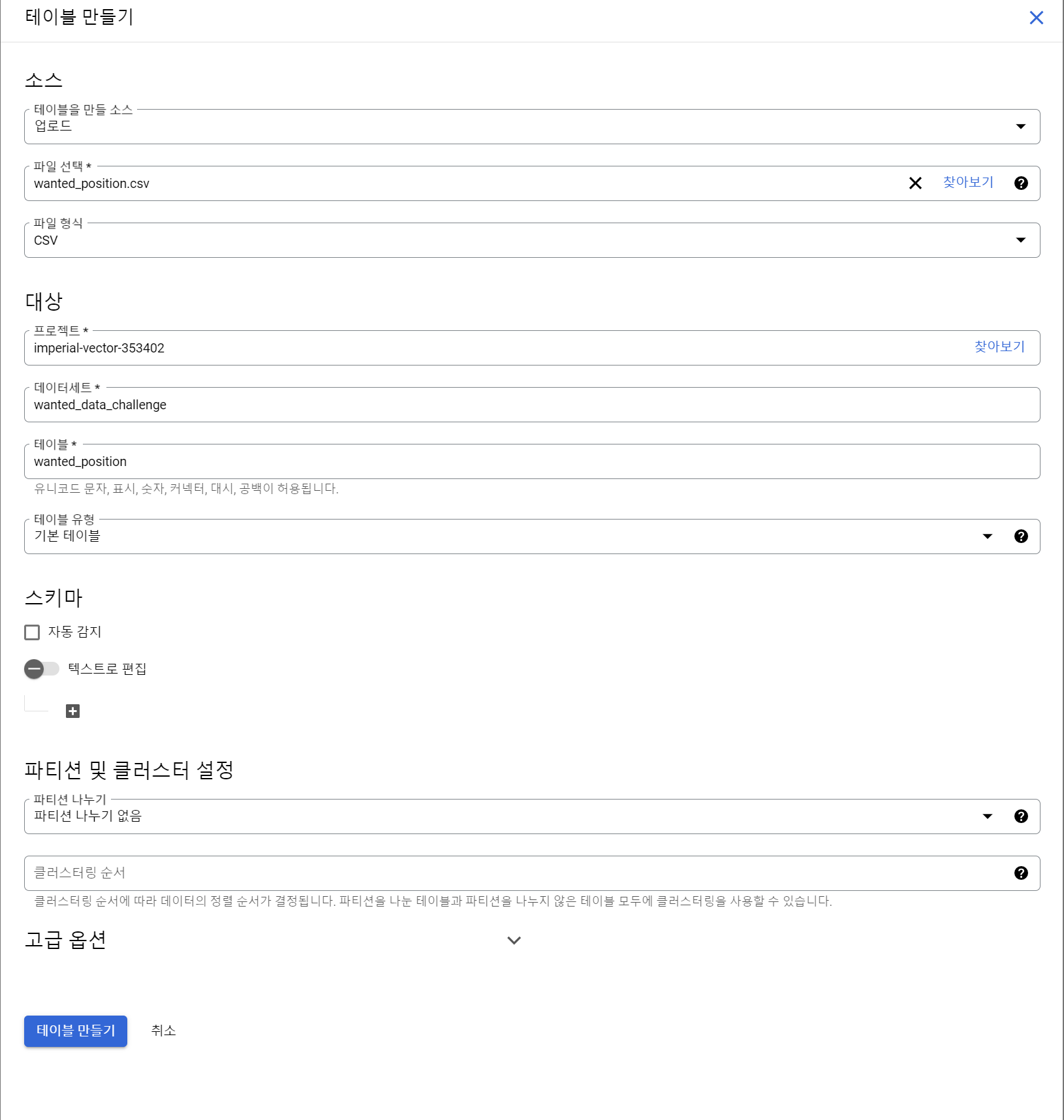
스키마를 텍스트로 간단하게 설정할 수 있어 좋아보인다

- 파티션 나누기? 데이터의 row양이 많으면 특정 기준으로 테이블을 자르는 것 (db 샤딩같은 개념?)
파티션이 있으면 분석가가 쿼리를 날릴 때 WHERE절로 기간을 설정하지 않으면 돌아가지 않도록 설정
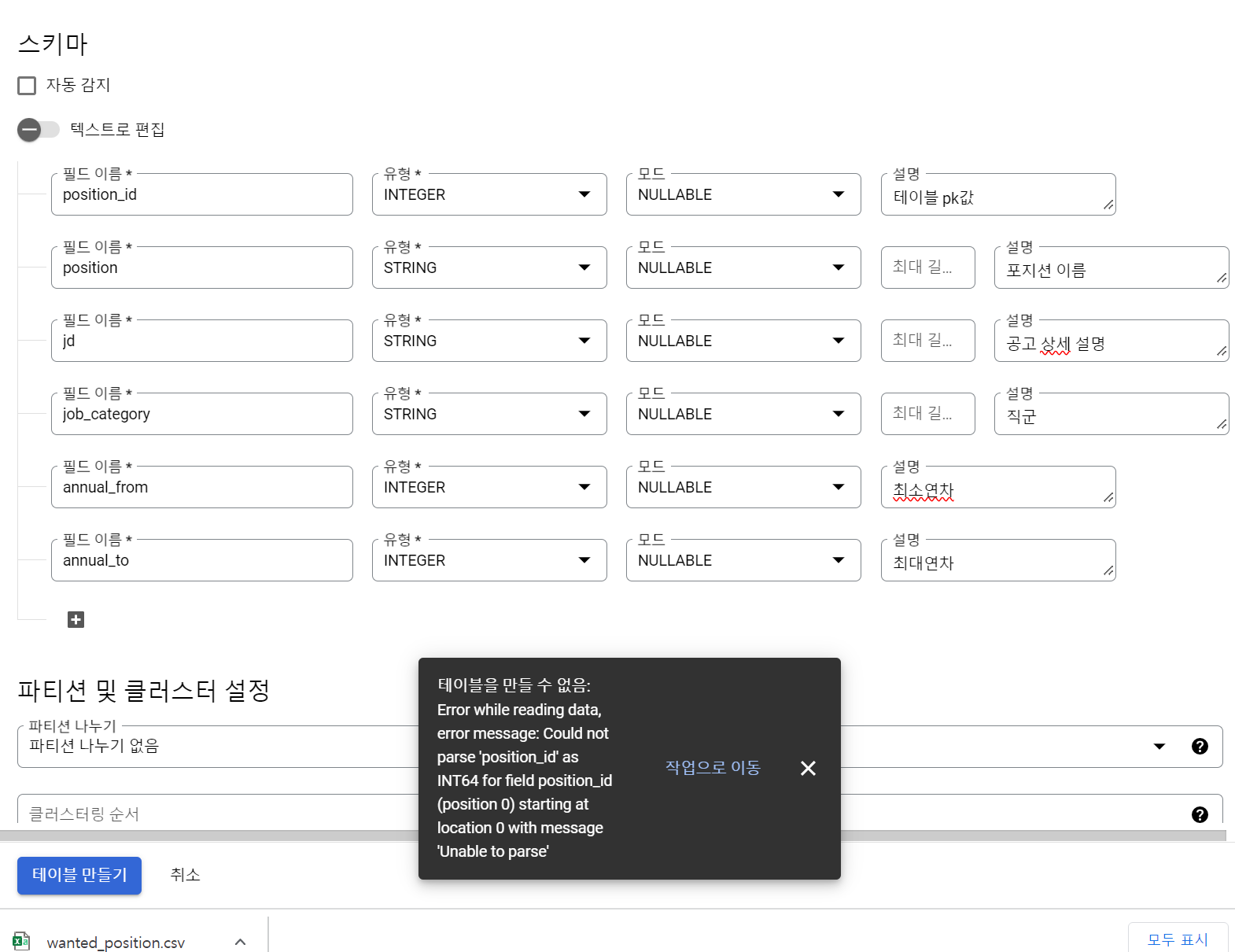
- 역시 그냥되면 섭하지..
테이블을 만들 수 없음: Error while reading data, error message: Could not parse 'position_id' as INT64 for field position_id (position 0) starting at location 0 with message 'Unable to parse'이라는 오류가 발생했다. CSV 파일에 헤더가 있어서 발생하는 오류라는데(헤더가 INT가 아니기 때문에), 밑에 고급설정에서 헤더 패스로 1을 넘겨주고 다시 고고!
- 역시 또 그냥 넘어갈 수 없지...
테이블을 만들 수 없음: Error while reading data, error message: CSV table references column position 5, but line starting at position:59 contains only 3 columns.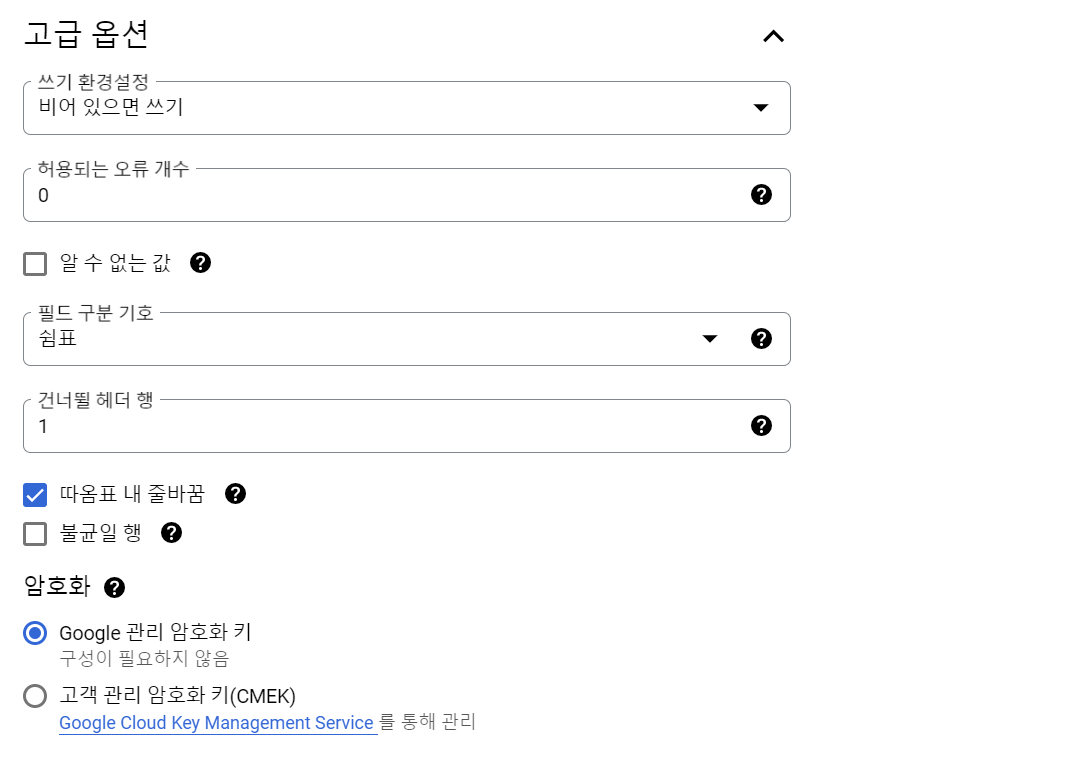
이렇게 따옴표 내 줄바꿈까지 해주면 해결 된다!
- 플러스로 멘토님은 구글 스프레드 시트에 파일을 upload해서 첫 줄을 없앤 후 구글 시트로 테이블을 만드는 방법을 택하셨당
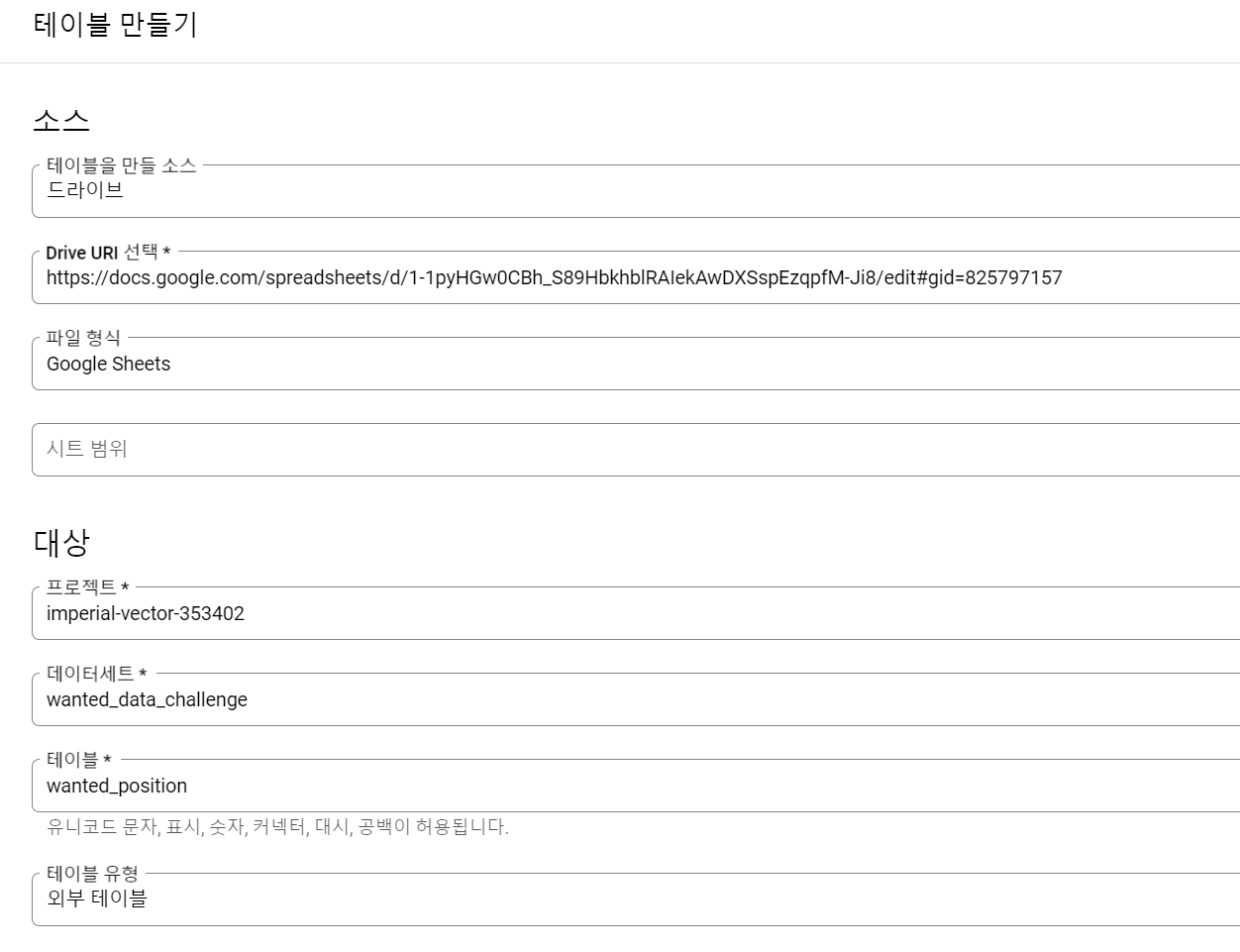
쿼리
쿼리를 누르면 이렇게 위치가 나온다
SELECT * FROM `imperial-vector-353402.wanted_data_challenge.wanted_position` LIMIT 1000
# FROM wanted_data_challenge.wanted_position 이렇게 해도됨!테이블 재세팅
- 현재 jd => 회사소개, 주요업무, 자격요건, 우대사항, 복지 및 혜택 순으로 되어있으니 이를 각각의 컬럼으로 나눠주는 쿼리를 실행해보자.
SELECT
position_id,
position,
SPLIT(SPLIT(jd, '주요업무')[safe_offset(1)], '자격요건')[safe_offset(0)] AS responsibilities,
SPLIT(SPLIT(jd, '자격요건')[safe_offset(1)], '우대사항')[safe_offset(0)] AS requirements,
SPLIT(SPLIT(jd, '우대사항')[safe_offset(1)], '혜택 및 복지')[safe_offset(0)] AS preference,
annual_from,
annual_to,
GENERATE_ARRAY(annual_from, annual_to, 1) AS target_annual #min, max, step
FROM `imperial-vector-353402.wanted_data_challenge.wanted_position` LIMIT 1000-
SPLIT(jd, '주요업무')[safe_offset(1)]#주요업무라는 단어가 나올때마다 쪼개고, 그 다음에 나오는 데이터 다 넣음 (python으로 치면.split('주요업무')[1]로 보면 될 것 같다. safe 가 붙는 이유는, 해당 index가 없으면 값을 리턴하지 않기 때문이라고 한다.
이제 거기서 쪼개고 쪼개고 하는 식! -
강사님 Code
SELECT
position_id
, position
, SPLIT(SPLIT(jd, '주요업무')[safe_offset(1)], '자격요건')[safe_offset(0)] AS responsibilities
, SPLIT(SPLIT(SPLIT(jd, '주요업무')[safe_offset(1)], '자격요건')[safe_offset(1)], '우대사항')[safe_offset(0)] AS requirements
, SPLIT(SPLIT(SPLIT(SPLIT(jd, '주요업무')[safe_offset(1)], '자격요건')[safe_offset(1)], '우대사항')[safe_offset(1)], '혜택 및 복지')[safe_offset(0)] AS preference
, annual_from
, annual_to
, GENERATE_ARRAY(annual_from, annual_to, 1) AS target_annual
FROM wanted_data_challenge.wanted_position
#WHERE 쓰지 않도록 하겠습니다.
#position_id | position | responsibilities | requirements | preference | annual_from | annual_to | target_annual
# 회사소개 , 주요업무, 자격요건, 우대사항, 복지 및 혜택 - 뚞딱뚝딱 쿼리를 날리면
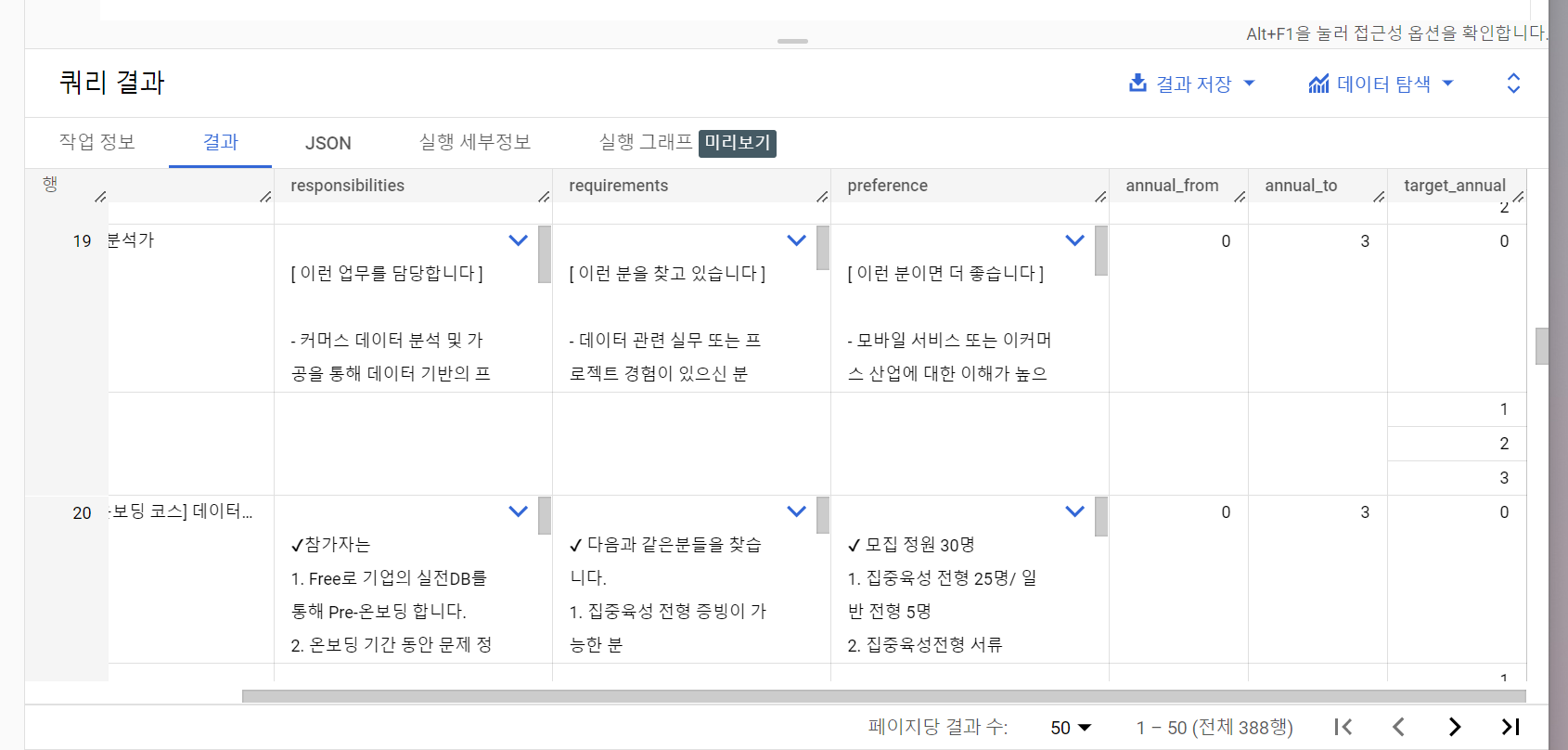
짠!
이 결과를 이제 코랩에서 시각화할 예정이다!
빅쿼리가 좋은건 여기서 데이터 탐색 버튼을 누르고 colab노트북으로 탐색을 눌러 바로 처리가 가능하다!
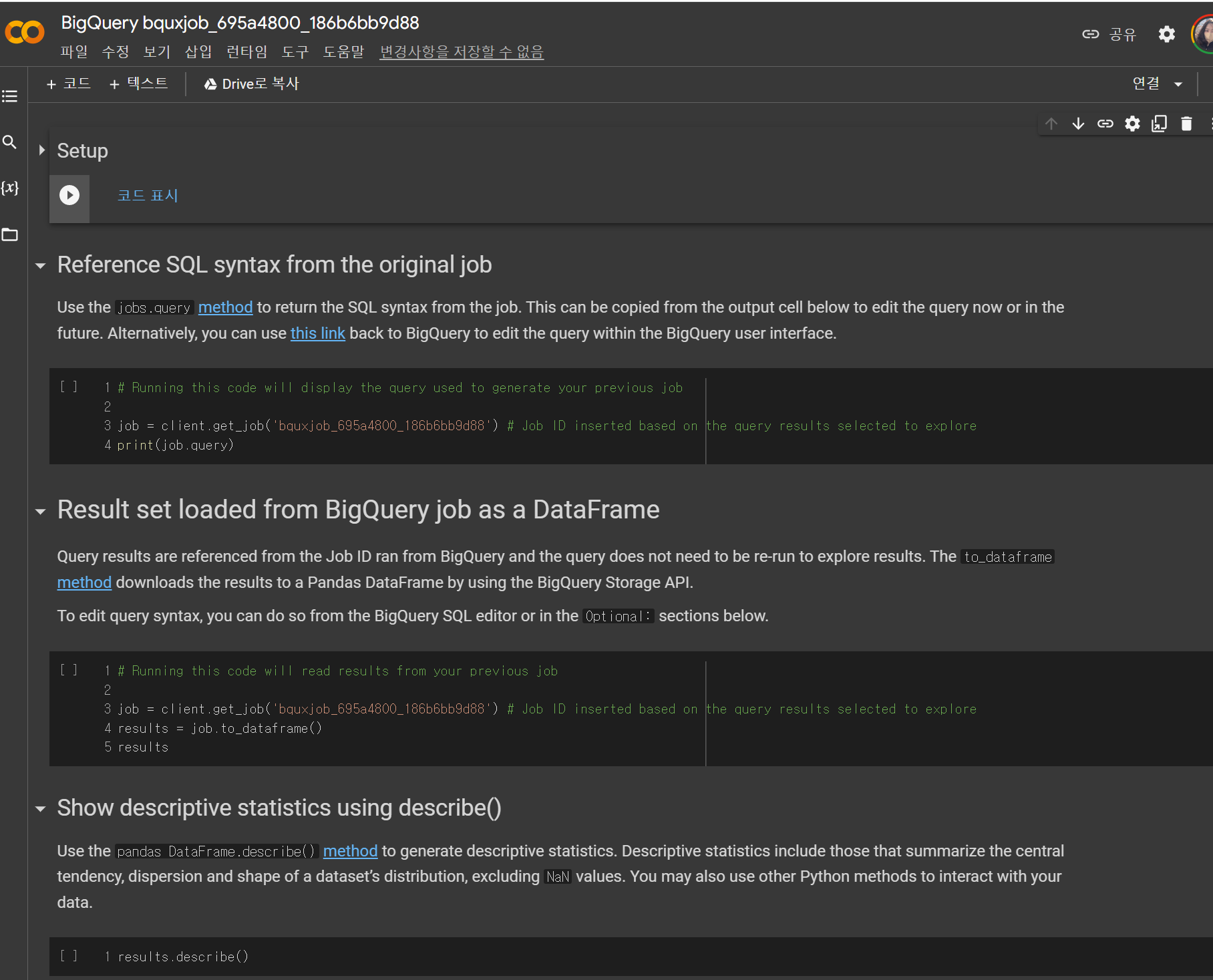
2. colab으로 시각화
setup 실행
- 라이브러리 import, db연결
Reference SQL syntax from the original job
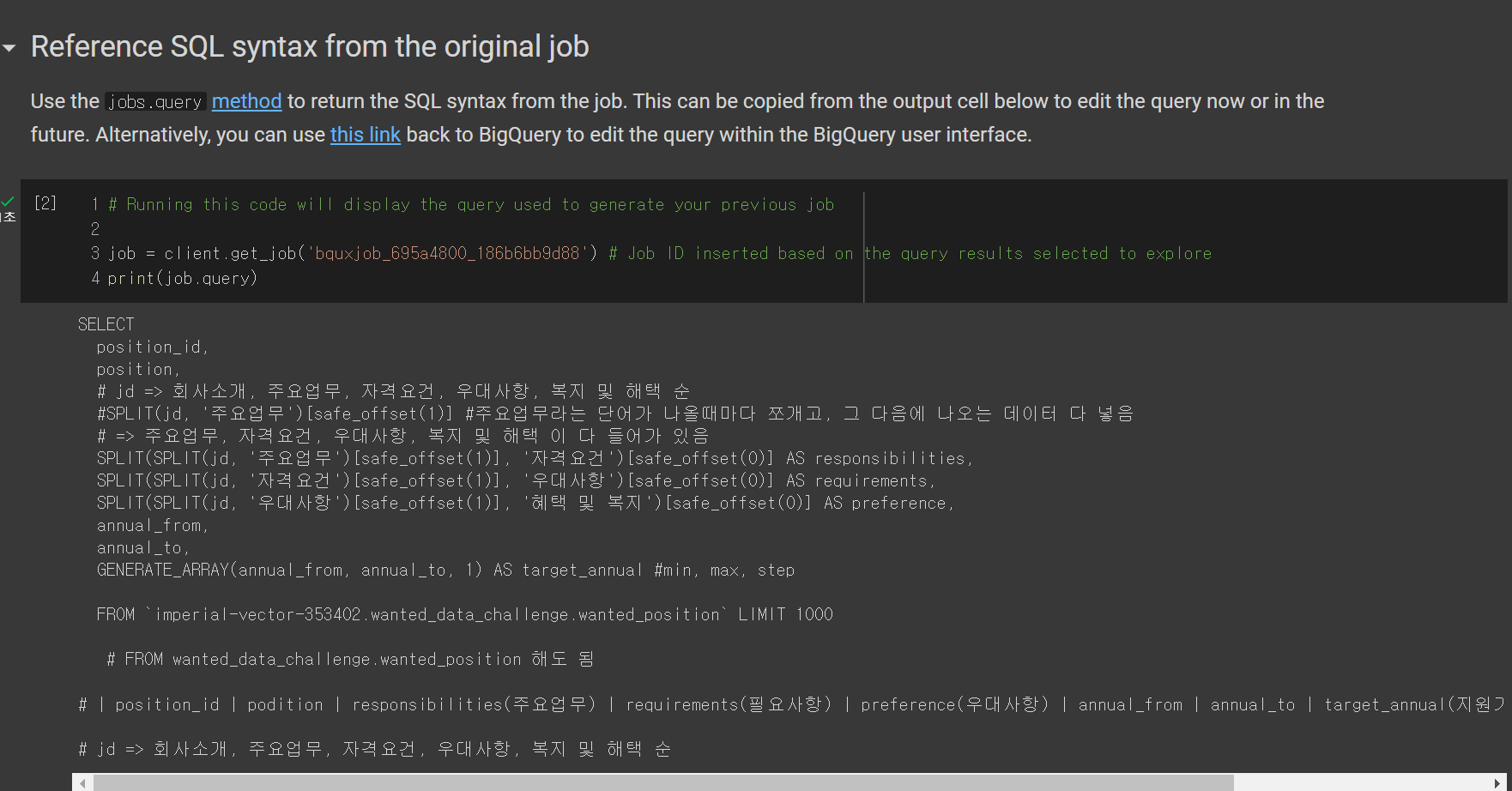
- 내가 빅쿼리에서 어떤 쿼리문을 날렸는지 확인
Result set loaded from BigQuery job as a DataFrame
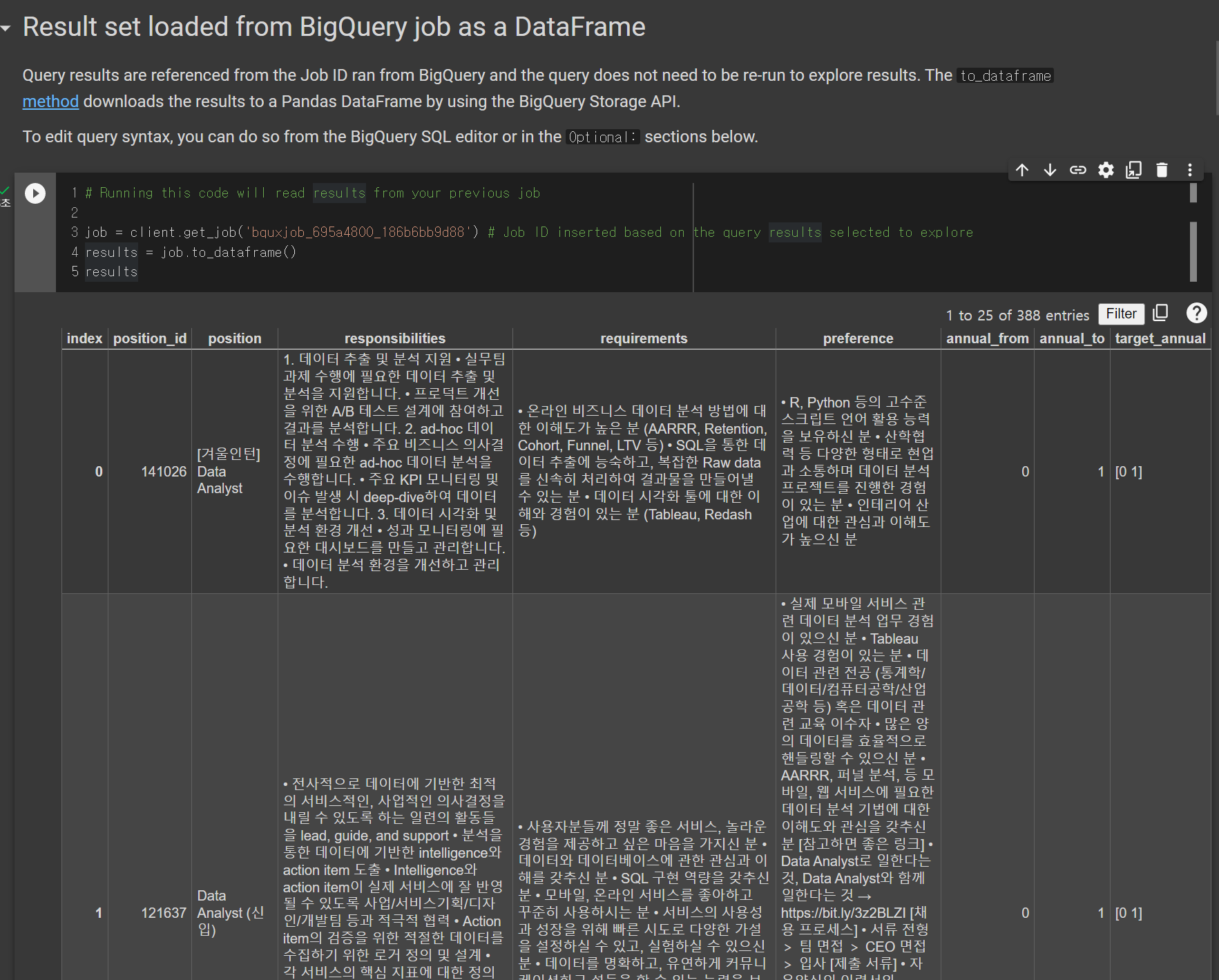
- 바로 DataFrame화까지...
Show descriptive statistics using describe()
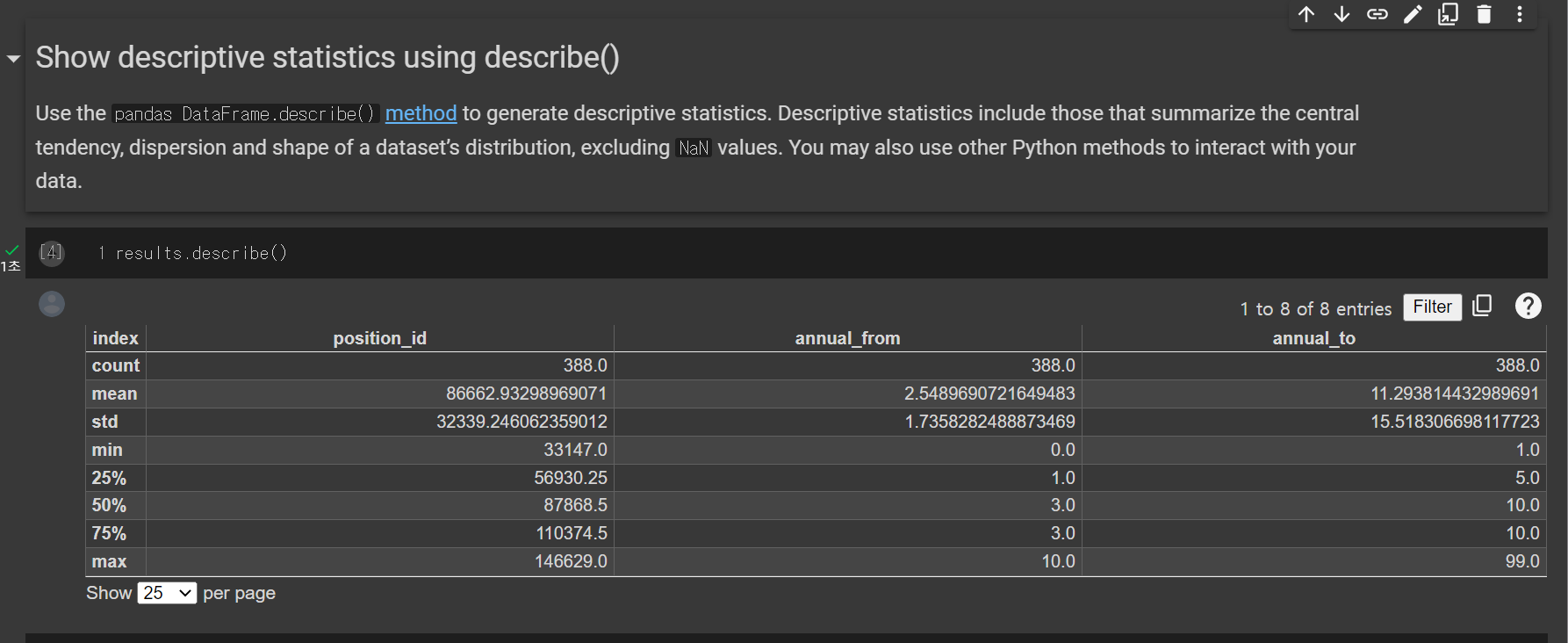
- 빠질 수 없는 describe 까지..!!!!
3. 데이터 시각화
시각화를 위한 라이브러리 pip, import!
!pip install krwordrank # wordcloud 형성을 위한 패키지 설치!
import pandas as pd
import matplotlib.pyplot as plt
from krwordrank.word import KRWordRank
import numpy as npDataFrame 전처리
- 먼저 result를 복사해서 df 처리한 다음 혹시 모를 NaN값을 없애준다 (뒤에서 이거 안하고 진행했다가 에러뜸^)^ㅎㅎㅎ)
df = results.copy() # result 복사
df['responsibilities'].replace(np.nan, '없음', inplace=True) # df.fillna('없음', inplace=True) 가능
df['requirements'].replace(np.nan, '없음', inplace=True)
df['preference'].replace(np.nan, '없음', inplace=True)
df.head()목표! 주요업무, 자격요건, 우대사항 각각에서 가장 많이 반복되는 단어가 무엇인지 확인하며 어떤 것을 회사에서 원하는지 시각화해보기!!
주요업무 시각화
texts = df['responsibilities'].values.tolist() # 시각화 하기 위해 column을 하나로 묶어줌
print(texts) KRWordRank를 이용해서 keyword, rank 추출
wordrank_extractor = KRWordRank(min_count =3 , # 단어 최소 빈도수 (최소 몇번은 나온애들로 만든다)
max_length = 15, # 단어 캐릭터 길이의 최댓값
verbose = True)
beta = 0.85 # PageRank의 decaying factor beta
max_iter = 10
keywords, rank, graph = wordrank_extractor.extract(texts, beta, max_iter) # 단어 추출 함수, 빈도 rank, 그래프를 output함
for word, r in sorted(keywords.items(), key = lambda x:x[1], reverse = True)[:30]: #자주 반복되는 단어 top 30
print((word, r))- 하지만 이렇게 추출하면 and, to, 위한, 등 불용어들이 들어가있어 좋은 결과를 뽑아내기 어렵다. 삭제할 stopword를 넣어주자. 그럼 우선 시각화할 데이터는 준비 완료.
stopwords = {'대한','분이면', '있습니다.','분석','데이터', '위한', '이를','and', '통해', '통한','있는','the','to','in','for','of'} #걸렀으면 하는 stopwords
passwords = {word:score for word, score in sorted(
keywords.items(), key=lambda x:-x[1])[:100] if not (word in stopwords)} #stopwords는 제외된 keywords 탑 100개
# stopwords 제외한 내용
for word, r in sorted(passwords.items(), key = lambda x:x[1], reverse = True)[:30]:
print((word, r))한글 지원 처리
#한글폰트 지원이 되지 않기 때문에 별도로 이걸 깔아줘야한다.
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
#mpl.font_manager._rebuild()
#[출처] [Google Colab] 구글 코랩 한글 적용 문제 대응, Matplotlib|작성자 넬티아WordCloud로 시각화!
from wordcloud import WordCloud, ImageColorGenerator
wc = WordCloud(font_path = fontpath, width = 1000, height = 1000, scale = 3, max_font_size = 250, background_color = 'white')
gen = wc.generate_from_frequencies(passwords)
plt.figure()
plt.imshow(gen)
- 시각화를 하고 나니 확실히 눈에 확 들어오는게 느껴진다.
- 주요업무를 보면, 다양한 비즈니스에서 서비스 기반의 인사이트를 도출하고 지표를 만드는 업무를 하나?ㅋㅋㅋㅋ
동일한 코드로 필수조건을 시각화 해보면

이런 결과가 나온다.
- 중요한 필수조건은 모다..? SQL..... 에스큐에엘!!!!!!!!!!!!!!
-
Data를 다루는 일이라면 관심이 많아서 큰 기대없이 들었는데, 크롤링 데이터에서 전처리 - 시각화 - 결과도출까지 해보는 좋은 경험이었다! With Google Bigquery~!
-
왜 다들 구글구글하는지 플랫폼의 힘을 느껴버렸다... 세상에 동기화가 이렇게 편하게 된다니... 그리고 테이블생성, 쿼리문 결과 예측 등 너무 유저친화적이었다..!
-
SQL문에서 왜
,를 앞에 붙이나 했더니 잘 안보여서 빼먹는 경우가 갱장히 많았닼ㅋㅋㅋ 나도 앞으로는 앞에 붙혀야징 -
진행하는 질문~🙋♀️
스키마 만들때 MAX값 없이 넘어가던데, 빅쿼리에서는 MAX없이 진행하면 VARCHAR 나 TEXT 중 어느유형과 비슷한 개념일까? Index 없이 생성되진않을 것 같은데 말이죠?- 공식문서에는 단순히
STRING 2 논리 바이트 + UTF-8 인코딩 문자열 크기로만 나타나 있다. 최대 행 크기는 100MB. - 근데 보다 보니,
ARRAY,STRUCT,UNNEST같은 뭔가 SQL같지 않은 자료형도 보인다. 오히려 이런 점이 빅쿼리의 퍼포먼스 개선, 데이터 저장 용량의 효율 등에 도움을 준다고 한다. 혹시나 해서 관련 블로그 (기존 자료형에서 CAST로 변환 가능) - 흠... 빅쿼리는 비정규화 됐을 때 가장 효율이 좋다고 하는데, 아예 RDS가 아니라 MAX를 안정하나
- BigQuery와 MySQL은 다른 종류의 데이터베이스 시스템이라넹... BigQuery는 데이터 웨어하우스, 컬럼 기반 데이터베이스, 빅데이터 처리 및 분석에 속하고, MySQL은 관계형 데이터베이스에 속하기때문에 두 시스템의 자료형도 다르다고...
- 공식문서에는 단순히
-
찾아보다보니, 지금 나한텐 자료형의 처리 방법도 중요하지만,,, 그보다
ARRAY,STRUCT,UNNEST이런 것들을 더 잘쓰는 것이 먼저라는 생각이 든다🫠🫠 신기하네,,, 우선 SQL 먼저 공부하고 나중에 Google Bigquery도 한번 파보고 싶다! 어떻게 돌아가는고야...핰ㅎ....
