시간 복잡도, “얼마나 빠르게 실행되는가?”
문제를 해결하는 데에 걸리는 시간과 입력의 함수 관계 → 연산을 실행할 때 입력의 변화에 따라 연산 횟수 대비 시간이 얼마나 걸리는가?
효율적인 알고리즘: 입력값이 커짐에 따라 증가하는 시간의 비율을 최소화한 알고리즘 →시간 복잡도가 낮은 알고리즘
알고리즘의 로직 수행에 얼마나 오랜 시간이 걸리는지
Big-O, 최악의 경우
최악의 경우를 고려 → 프로그램 실행 과정에서 소요되는 최대 시간 고려 가능
최악의 경우도 고려해 대비하는 것이 분석에 용이 → 주로 사용되는 표기법

O(1)
Constant Complexity
입력 크기 무관하게 연산 횟수 고정
입력 크기가 증가하더라도 시간 복잡도 불변
입력 크기와 관계 없이 즉시 출력 도출 가능
ex) 배열 인덱스 접근
O(log n)
Logarithmic Complexity
연산을 수행할수록 문제 해결에 필요한 단계 감소
O(1) 다음으로 가장 빠른 시간 복잡도
ex) BST(Binary Search Tree, 이진 탐색 트리)의 탐색 연산
O(n)
Linear Complexity
입력 크기와 연산 횟수가 비례 → 선형적으로 증가
ex) 크기가 N인 배열의 선형 탐사
O(n log n)
Log-Linear Complexity
입력의 크기가 2배로 증가할 때 연산 횟수는 2배 조금 넘게 증가
ex) 힙 정렬
O(n²)
Quadratic Complexity
ex) 2중 반복문을 돌게 되는 경우
O(n!)
Factorial Complexity
가장 큰 시간 복잡도
ex) 순열의 모든 경우의 수 계산
O(2ⁿ)
Exponential Complexity
해당 시간 복잡도를 가진다면 다른 접근 방식을 고려해야 함
ex) 부분 집합의 모든 경우의 수 계산
Big-θ, 평균의 경우
함수 증가율의 상한과 하한을 모두 나타냄 → 평균
Big-Ω, 최선의 경우
Big-O와 반대로 함수 증가율의 하한을 나타냄
“최소한 이 정도는 걸린다”
공간 복잡도, “얼마나 많은 자원이 필요한가?”
프로그램 실행 후 완료까지 필요한 자원 공간의 양
정적 변수로 선언한 고정 공간 + 재귀적인 함수 등으로 인해 동적으로 필요해진 추가 공간
시간 복잡도와 반비례적인 경향을 띄므로 좋은 알고리즘의 척도는 시간 복잡도 위주
선형 자료 구조, “각 자료 간 1:1 관계를 가지는 구조”
Linked List, 연결 리스트
메모리의 동적 할당을 기반으로 구현된 리스트
자료의 논리적 순서와 메모리 상의 물리적인 순서 불일치
링크를 통해 원소에 접근 → 물리적인 순서를 맞추기 위한 작업 불필요
자료구조의 크기 동적으로 조정 가능 → 메모리의 효율적 사용
추가, 삭제: O(1), 탐색: O(n)
구조
Node: 연결 리스트에서 하나의 원소를 표현하는 building block

Head
연결 리스트의 첫 노드에 대한 참조값 보유 → 모든 노드에 선행 노드가 있는 환경 조성
Head만 있으면 마지막 원소 접근 시 어려움 → Tail 추가 생성
Tail: 마지막 원소 추가 시마다 갱신 필요하지만 매번 Head부터 탐색하는 것보다는 효율적
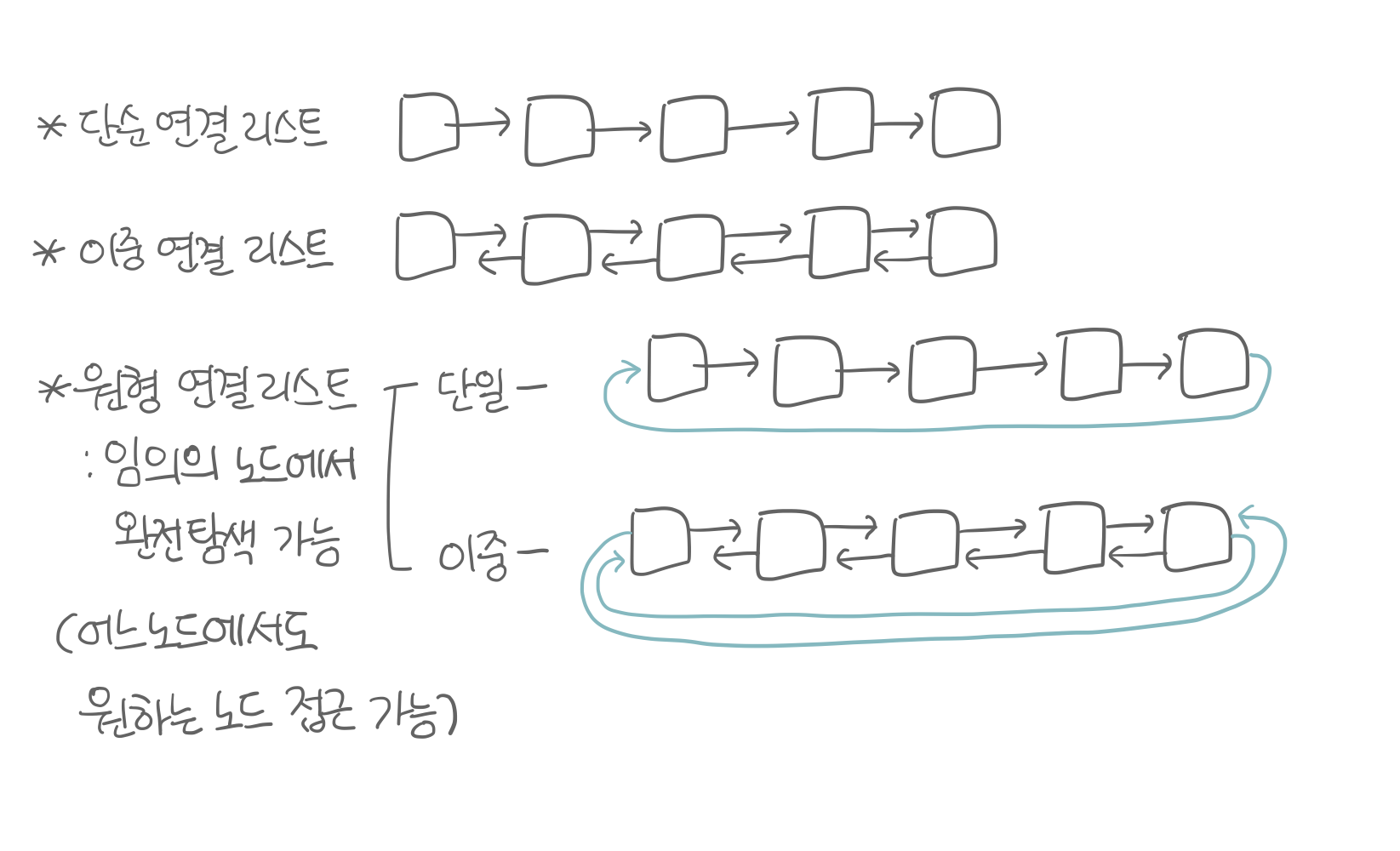
Singly Linked List, 단순 연결 리스트
링크 필드: 다음 노드만 가리킴
노드가 하나의 링크 필드를 통해 다음 노드와 연결 → 링크 필드가 연속적으로 다음 노드를 가리킴
Doubly Linked List, 이중 연결 리스트
링크 필드: 이전 노드, 다음 노드를 가리킴
양쪽 방향으로 순회할 수 있도록 노드를 연결한 리스트
이전 노드를 탐색하는 데에 용이
Circular Linked List, 원형 연결 리스트
링크 필드: 단순 or 이중인 경우 모두 일반 연결 리스트와 같지만 마지막 노드의 next 포인터가 헤드를 가리킴
어느 노드에서도 원하는 노드 접근 가능 → 임의의 노드에서 완전 탐색 가능
배열
같은 타입의 변수들을 인접한 메모리 위치에 모아놓은 고정 크기의 집합
원소마다 순서가 있어 중복이 허용됨
인덱스를 사용한 랜덤 접근 가능
랜덤 접근
배열과 같이 순차적인 데이터가 있을 때 임의의 인덱스에 해당하는 데이터에 접근 가능
↔ 순차 접근, 데이터가 저장된 순서대로만 접근 가능
추가, 삭제: O(n)
탐색: O(1)
연결 리스트와의 비교
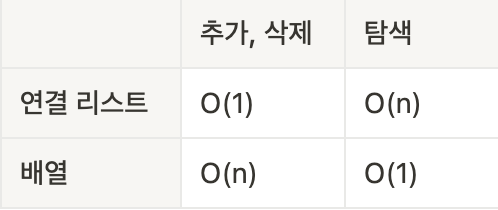
데이터의 추가, 삭제가 잦은 경우: 연결 리스트 사용
데이터의 탐색이 잦은 경우: 배열 사용
벡터
동적으로 요소를 할당할 수 있는 동적 배열 → 컴파일 시점에 원소의 개수를 알 수 없을 때 사용
원소마다 순서가 있어 중복이 허용됨
인덱스를 사용한 랜덤 접근 가능
탐색, 맨 뒤에서의 추가, 삭제: O(1)
맨 앞이나 맨 뒤가 아닌 요소의 추가, 삭제: O(n)
amortized Complexity
O(1)보다는 크지만 O(1)에 가까운 복잡도
벡터의 맨 뒤에서부터 추가하는 경우 벡터의 크기가 증가하는 시간 복잡도가 Constant Complexity와 유사
스택
LIFO(Last In First Out), 후입선출: 마지막에 저장된 자료를 가장 먼저 사용
자료의 추가, 삭제 모두 top에서만 발생
추가, 삭제: O(1), 탐색: O(n)
주요 메서드
push(): top 위치에 자료 추가
isEmpty(): 스택이 비었는지 여부
pop(): top 위치 자료 삭제
size(): 스택 원소의 개수
peek(): top 위치 자료 반환
활용
재귀 함수, 함수 호출, DFS
큐
FIFO(First In First Out), 선입선출: 자료가 저장된 순서대로 사용
자료의 추 가는 Front, 삭제는 Rear에서 발생
추가, 삭제: O(1), 탐색: O(n)
주요 메서드
offer(): enQueue, Front에 자료 추가
isEmpty(): 큐가 비었는지 여부
poll(): deQueue, Rear에 자료 삭제
size(): 큐 원소의 개수
peek(): Rear 위치 자료 반환
활용
캐시 구현, 프로세스 관리, BFS
데크, Deque, Double ended queue
양방향으로 이어 붙인 큐
스택과 큐 모두로 사용 가능
양 끝 원소에 접근하여 추가, 삭제 시 매우 빠른 속도로 연산 수행
추가, 삭제: O(1), 탐색: O(n)
비선형 자료 구조, “각 자료 간 1:N 관계를 가지는 구조”
그래프
정점(Vertex)과 간선(Edge)으로 이루어진 자료 구조
outdegree: 정점에서 나가는 간선
indegree: 정점으로 들어오는 간선
가중치: 정점과 정점 사이에 드는 비용
트리
자료가 트리 구조로 배열된 일종의 계층적 데이터 집합
아래의 조건이 지켜지는 특수한 형태의 그래프
부모, 자식의 계층 구조
E = V-1 → 간선의 수 = 노드의 수 - 1
한 노드에서 다른 노드까지 가는 경로는 반드시 존재
구성
루트 노드: 트리에서 가장 위에 있는 노드, 탐색의 출발점
내부 노드: 루트 노드와 리프 노드 사이의 노드
리프 노드: 자식 노드가 없는 말단의 노드
관련 용어
깊이(depth): 루트 노드부터 특정 노드까지의 최단 거리, 노드마다 다른 값 보유
높이(height): 루트 노드부터 리프 노드까지의 최장 거리
레벨(level): 깊이와 비슷한 개념, 루트 노드의 레벨을 어떻게 설정하느냐에 따라 해당 노드의 레벨 결정
서브 트리(sub tree): 트리 내의 하위 집합, 트리 내의 부분 집합
이진 트리
자식의 수가 두 개 이하인 트리
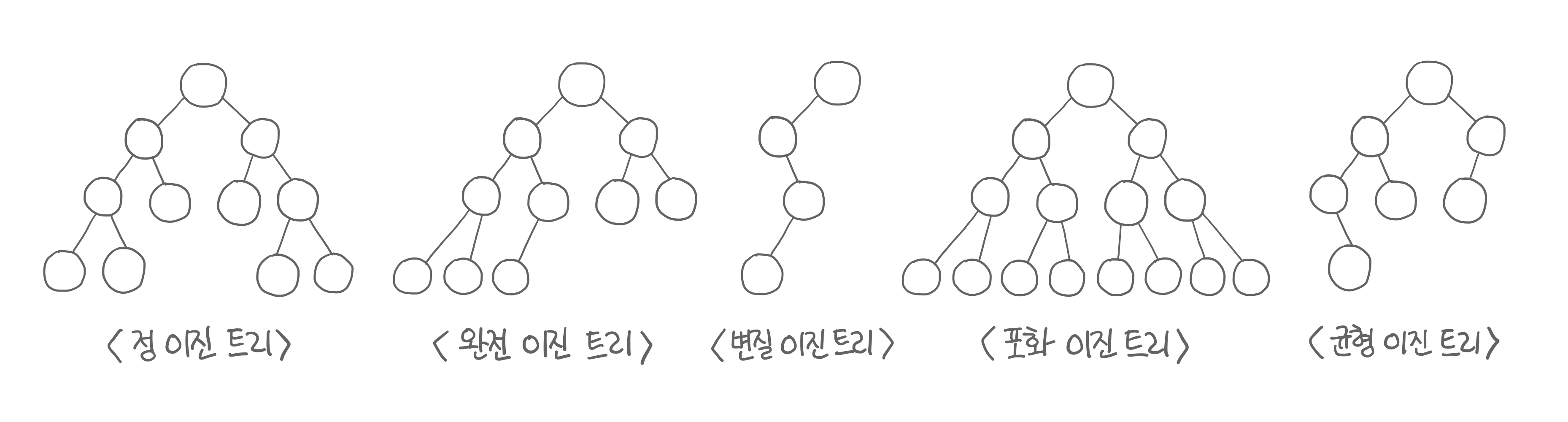
정이진 트리(full binary tree): 자식 노드가 없거나 2개인 이진 트리
완전 이진 트리(complete binary tree): 왼쪽부터 채워진 이진 트리, 마지막이 아닌 레벨은 완전히 채워짐
변질 이진 트리(degenerate binary tree): 자식 노드가 1개뿐인 이진 트리
포화 이진 트리(perfect binary tree): 모든 노드가 꽉 차 있는 이진 트리
균형 이진 트리(balanced binary tree): 왼쪽과 오른쪽 노드의 높이 차이가 1 이하인 이진 트리
이진 탐색 트리, BST(Binary Search Tree)
한 노드를 중심으로 왼쪽 하위 트리에는 보다 작은 값, 오른쪽 하위 트리에는 보다 큰 값이 들어 있는 트리
자료 검색 연산에 용이
탐색: 주로 O(log n), 최악의 경우 O(n)
삽입 순서에 따라 선형적인 트리 생성 가능 → 최악의 경우 발생
AVL 트리
최악의 경우 선형적인 트리가 되는 것을 방지하기 위해 스스로 균형을 잡는 이진 탐색 트리
두 자식 서브 트리의 높이 차이는 1 이하
추가, 삭제 탐색: 주로 O(log n)
Red-Black 트리
각 노드마다 빨간색, 검은색을 나타내는 추가 비트가 더해진 균형 이진 트리
추가 비트 → 트리 균형 유지 목적
“루트 노드와 모든 리프 노드는 검은색이고, 어떤 노드가 빨간색이면 그 자식은 반드시 검은색이다”의 규칙 보유
추가, 삭제, 탐색: O(log n)
힙
우선순위 큐의 구현을 위해 Complete Binary Tree(완전 이진 트리) 기반으로 구현된 자료 구조
여러 개의 자료 중 최댓값, 최솟값을 빠르게 찾을 수 있도록 설계됨
이진 탐색 트리(BST)와 달리 중복값 허용
추가, 삭제, 탐색: O(log n)
종류
최대 힙: 부모 노드의 키 값이 자식 노드의 키 값 이상인 완전 이진 트리
최소 힙: 부모 노드의 키 값이 자식 노드의 키 값 이하인 완전 이진 트리
구현
표준적으로 배열 사용
구현이 쉽도록 인덱스 0은 사용하지 않음
인덱스가 i인 노드 기준으로 아래의 공식이 적용됨
왼쪽 자식의 인덱스: 2*i
오른쪽 자식의 인덱스: 2*i+1
부모의 인덱스: i/2
종류
최대힙: 루트 노드에 있는 키는 모든 자식의 키 중 최댓값, 모든 노드에서 해당 조건 만족
최소힙: 루트 노드에 있는 키는 모든 자식의 키 중 최솟값, 모든 노드에서 해당 조건 만족
우선순위 큐
큐에서 우선순위가 높은 자료가 우선순위가 낮은 요소보다 먼저 제공되는 자료 구조
힙 기반으로 구현
맵
Key-Value 쌍으로 관리되는 자료 구조
Red Black Tree 기반으로 구현
자료 삽입 시 자동으로 정렬 수행
해시 테이블 구현 시 사용
셋
특정 순서에 따라 고유한 요소를 저장하는 자료 구조
중복 값 저장 불가 → 유니크한 값만 저장
해시 테이블
맵의 특성을 이어받아 Key-Value 쌍으로 자료 관리
자료들을 유한한 개수의 해시 값으로 매핑한 테이블
매우 빠른 삽입, 삭제, 탐색 연산 속도
공간 효율성이 떨어지며 해시 함수의 의존도가 높음
ex) 작은 캐시 메모리로 프로세스 관리
추가, 삭제, 탐색: O(1)
참조 링크
[Algorithm] 시간 복잡도(Time complexity) 학습
[알고리즘] 최소 신장 트리(MST, Minimum Spanning Tree)란 - Heee's Development Blog


이렇게 유용한 정보를 공유해주셔서 감사합니다.