인덱스
데이터베이스 분야에 있어서 테이블에 대한 동작속도를 높여주는 자료구조
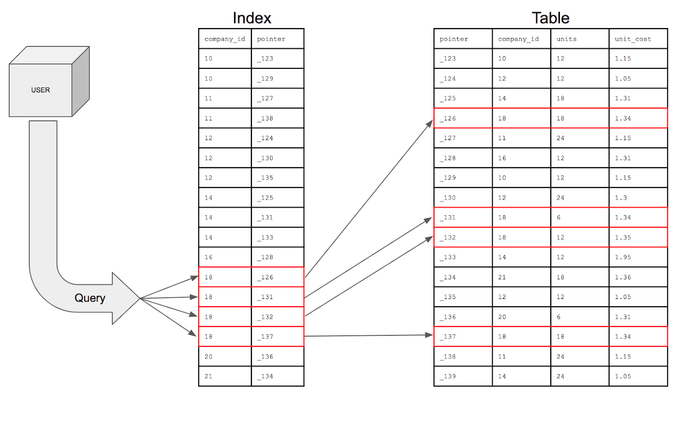
- 테이블 내 1개 컬럼 혹은 여러 개의 컬럼을 이용해 생성
- default 👉 PK or UNIQUE
- 중복도가 높은 속성을 인덱스로 가지면 효율이 떨어짐
- 키(열의 값) - 필드(ROW ID)로 구성된 테이블 부분에 대한 하나의 사본 역할
- 별도의 공간이 필요함
- 테이블이 클수록 많은 비용이 필요
- 테이블 생성시 인덱스를 지정한다면, 테이블 생성 속도가 느려짐
- 테이블에 비해서는 적은 공간필요
WHY
- 테이블의 컬럼을 색인화하여 검색 시, 해당 테이블의 레코드를
full scan하는게 아니라 색인화 되어있는 인덱스 파일을 검색해 속도에 이점을 가짐
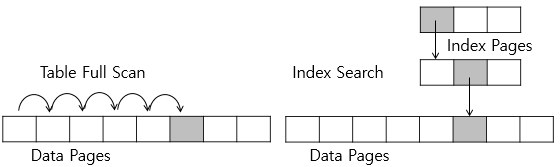
- 빠른 검색 뿐만 아니라 필요시 자료구조 자체의 특성으로 고유성을 강화할 수 있음(고유 인덱스)
WHEN
항상 쓰는게 좋을까?
- 인덱스는 DML(insert, delete, update)에 취약(인덱스 재구성 비용 때문)
- 별도의 저장공간 발생
👉 No, 항상 좋은건 아님
그럼 언제 이점을 가질까?
- 데이터의 양이 많고, 검색이 변경보다 잦은 경우
- 인덱스를 걸고자 하는 필드의 값이 다양한 값을 가지는 경우
어느 컬럼을 인덱스로 설정해야할까?
- WHERE 절에서 사용되는 열
- 데이터의 중복도가 낮은 열
- 외래키가 사용되는 열(참조 키를 빠르게 확인하고 테이블 스캔을 하지 않으려고)
- JOIN에 자주 사용되는 열
사용되는 자료구조

똑딱똑딱