🔥 HashMap (해시맵)
1. 해시맵(HashMap)이란?
'HashMap' 은 키(Key)와 값(value)쌍을 저장하는 자료 구조이다.
각 키는 고유하며, 키를 사용하여 해당하는 값을 빠르게 검색할 수 있다.
* 해싱 (Hashing) :
'HashMap'의 핵심 원리이다.
'해싱 함수(Hashing Functoin)'는 키(key)를 받아서
정수값인 '해시코드(Hashcode)'를 반환하고,
반환된 해시코드는 Hash 배열의 각 요소인 '버킷(Bucket)'의 인덱스가 된다.
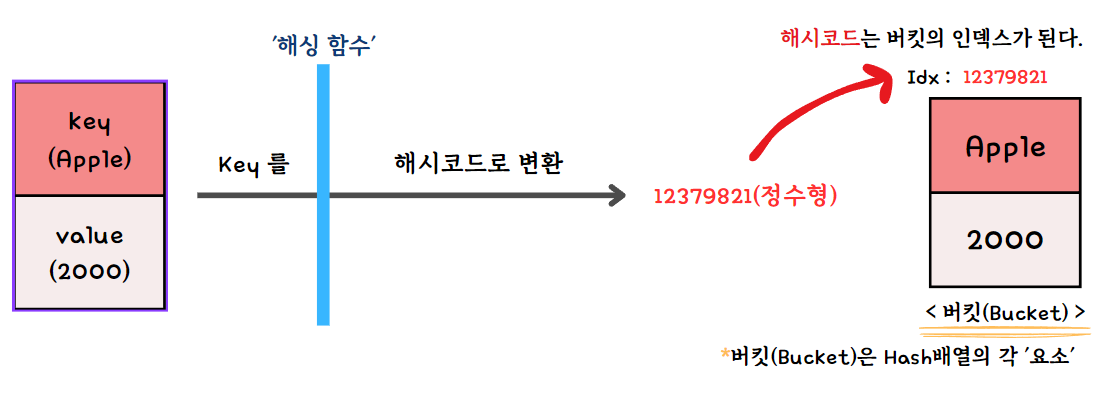
** 아래는 해시맵(HashMap)의 예시이다.
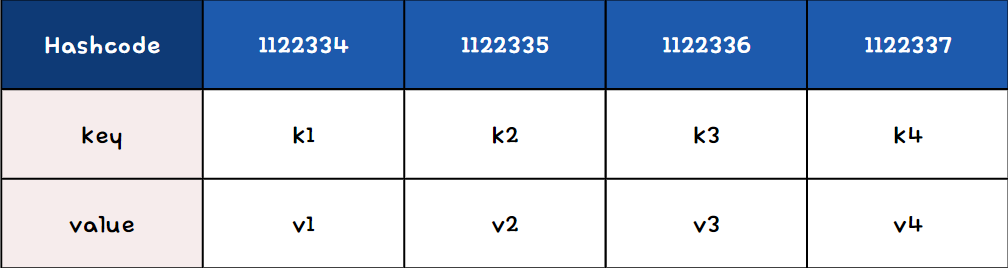
이 예시에서도 보이듯이 배열의 각 요소를 '버킷'이라고 한다.
요약하면,
키(key)를 주면 해싱 함수에 의해 해시코드로 변환되고, 해당 해시코드는 배열의 각 요소인. 버킷의 인덱스 역할을 한다. 해당 버킷을 찾아가면 값을 삽입 및 조회할 수 있다.
2. 특징
-
키 기반의 빠른 액세스 : 키를 사용하여 값을 빠르게 검색하거나 수정할 수 있다.
-
순서를 보장하지 않음 : 'HashMap' 은 내부적으로 키의 순서를 보장하지 않는다.
-
키의 중복 불가 : 같은 키를 중복해서 사용할 수 없다. 이미 존재하는 키에 대해 값을 저장하면 기존 값이 덮어씌워진다.
-
null 키와 값 : 'HashMap'은 null 키와 null 값을 저장할 수 있다. 하지만 키는 중복이 불가하므로 null 키는 하나만 저장될 수 있다.
-
키 기반의 유연성 : 어떤 객체든 키로 사용할 수 있다.
-
* 해싱 충돌 : 두 개 이상의 키가 동일한 해시 코드를 가질 때 충돌이 발생한다. 이는 성능 저하를 초래할 수 있다.
* 키 값이 다른데 동일한 해시코드를 갖는다 ?
'이게 무슨 소리일까?' 싶을 것이다.
해싱 함수는 결코 완벽하지 않다. 실제로 많은 키가 있을 때 서로 다른 키가 동일한 해시코드를 생성할 가능성은 항상 존재한다.
대신, 해싱 충돌을 처리하기 위한 주요 방법들이 있다.
⚡️ 해싱 충돌 해결방법
1) 체이닝 (Chaining)
이 방법에서 각 버킷은 연결리스트로 구현된다.
충돌이 발생하면, 해당 버킷의 연결리스트에 새로운 키-값 쌍을 추가한다.
체이닝은 구현이 간단하고, 메모리 할당이 동적으로 이루어진다.
2) 개방 주소법 (Open Addressing)
모든 키-값 쌍이 해시테이블의 배열 내에 직접 저장된다.
충돌이 발생하면, 다른 버킷의 위치를 찾아 삽입을 시도한다.
"다른 위치를 찾는" 과정은 또 여러 방법으로 나뉜다.
- 선형 조사 (Linear Probing):
초기 위치에서 일정 간격으로 버킷을 조사하여 빈 위치를 찾는다. - 제곱 조사 (Quadratic Probing):
충돌 발생 시 제곱만큼 떨어진 위치를 조사한다. - 이중 해싱 (Double Hashing):
두 번째 해시 함수를 사용하여 버킷 위치를 찾는다.
3) 재해싱 (Rehashing)
해시 테이블이 가득 차거나 충돌이 너무 많이 발생할 경우, 해시 테이블의 크기를 늘리고 모든 키-값 쌍을 새로운 크기에 맞게 재삽입하는 방법.
이 방법은 메모리 사용량을 늘리는 대신 충돌을 줄이고 성능을 향상시키는 데 효과적이다.
4) 버킷 확장 (Bucket Expansion)
충돌이 일어나면 해당 버킷의 크기를 확장하여 여러 키-값 쌍을 저장할 수 있게 한다.
5) 커스텀 해시 함수 사용
데이터의 특성에 맞게 설계된 커스텀 해시 함수를 사용하여 충돌을 최소화한다.
3. 자바에서의 'HashMap'
자바의 'java.util' 패키지에는 'HashMap'클래스가 포함되어 있다. 주요 메서드로는 put(), get(), remove(), containsKey(), size() 등이 있다.
import java.util.HashMap;
import java.util.Map;
public class HashMapExam {
public static void main(String[] args) {
// HashMap 생성
HashMap<String, Integer> map = new HashMap<>();
// 요소 추가 - put(key, value);
map.put("Apple", 1000);
map.put("Banana", 2000);
map.put("Orange", 3000);
// 요소 가져오기 - get(key);
int appleValue = map.get("Apple");
System.out.println("사과의 가격 : " + 1000);
// 특정 키가 HashMap에 있는지 확인 - containsKey(key);
boolean containsBanana = map.containsKey("Banana");
System.out.println("바나나 있어? " + containsBanana); // true
// 특정 값이 HashMap에 있는지 확인 - containsValue(value);
boolean contains3000 = map.containsValue(3000);
System.out.println("3000원짜리 있니? " + contains3000); // true
// 요소 제거 - remove(key)
map.remove("Orange");
// 모든 키-값 쌍을 순회하면서 출력 - entrySet()
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// HashMap의 크기 - map.size()
int size = map.size();
System.out.println("해시맵 크기 : " + size); // 2
// HashMap 비우기
map.clear();
}
}
4. 언제 사용하면 좋을까?
데이터의 순서가 중요하지 않고, 키를 기반으로 빠른 데이터 액세스가 필요할 때 사용하면 좋다. 또한 어떤 객체든 키로 사용할 수 있기때문에 그런 점도 고려하면 좋다.
5. 해시테이블
해시테이블은 일반적인 컴퓨터 과학의 자료구조 원칙이다.
해시맵(HashMap)은 해시 테이블의 한 구현체이고 Java에서 제공한다.
그래도 hash-map이라는 용어는 Java말고도 다른 프로그래밍 언어나 라이브러리에서도 비슷한 구조나 개념을 나타내는 데 사용한다.
(Python에서는 'dict'라는 이름의 해시맵 같은 구조가 존재한다!)
언어마다 각각 제공하는 특징이나, 동작방식은 다를 수 있다.
따라서 "해시테이블"은 보다 일반적인 자료 구조 원칙 또는 개념을 의미하며, "해시맵"은 그 원칙을 구체적으로 구현한 특정 클래스나 자료구조를 의미한다.

이해 짱짱 잘 되었습니다.감사합니다.