📕 U-Net
- U-Net은 이미지 분할(Image Segmentation)을 목적으로 제안된 End-to-End 방식의 Fully-Convolutional Network 기반 모델이다.
- 네트워크 구성의 형태(‘U’)로 인해 U-Net이라는 이름이 붙여졌다.
📗 U-Net Architecture
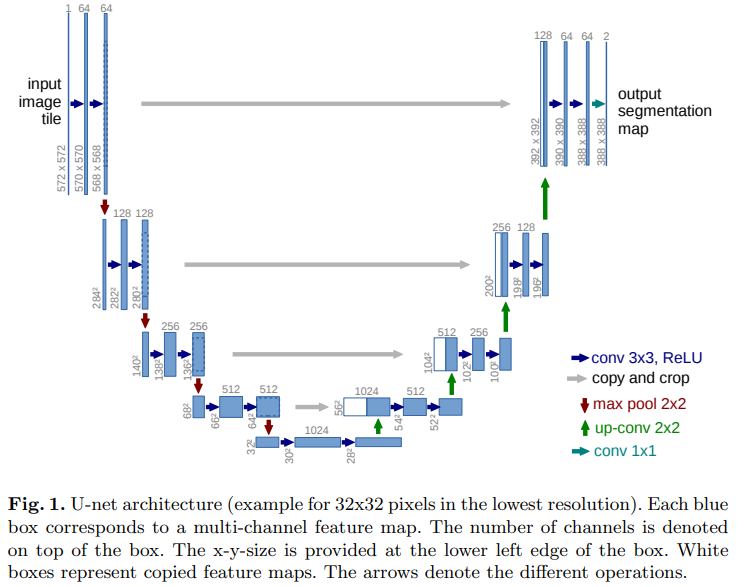
📘 Architecture Detail
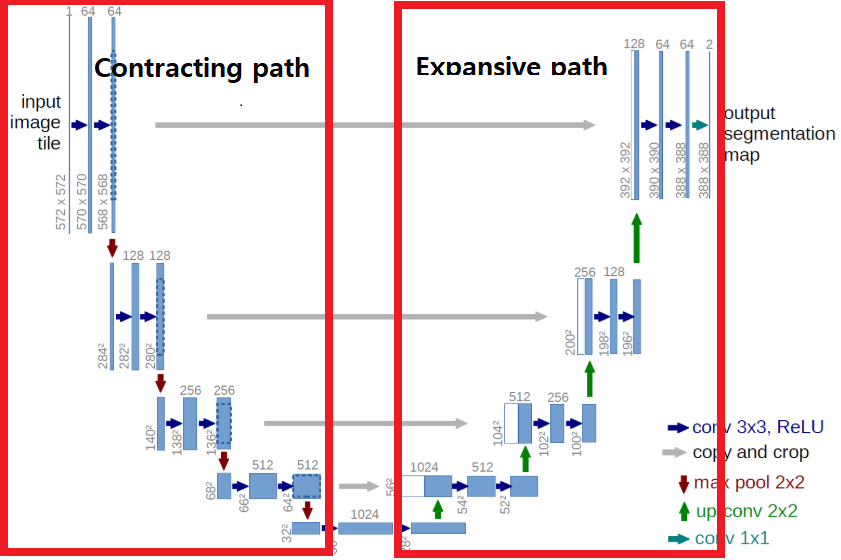
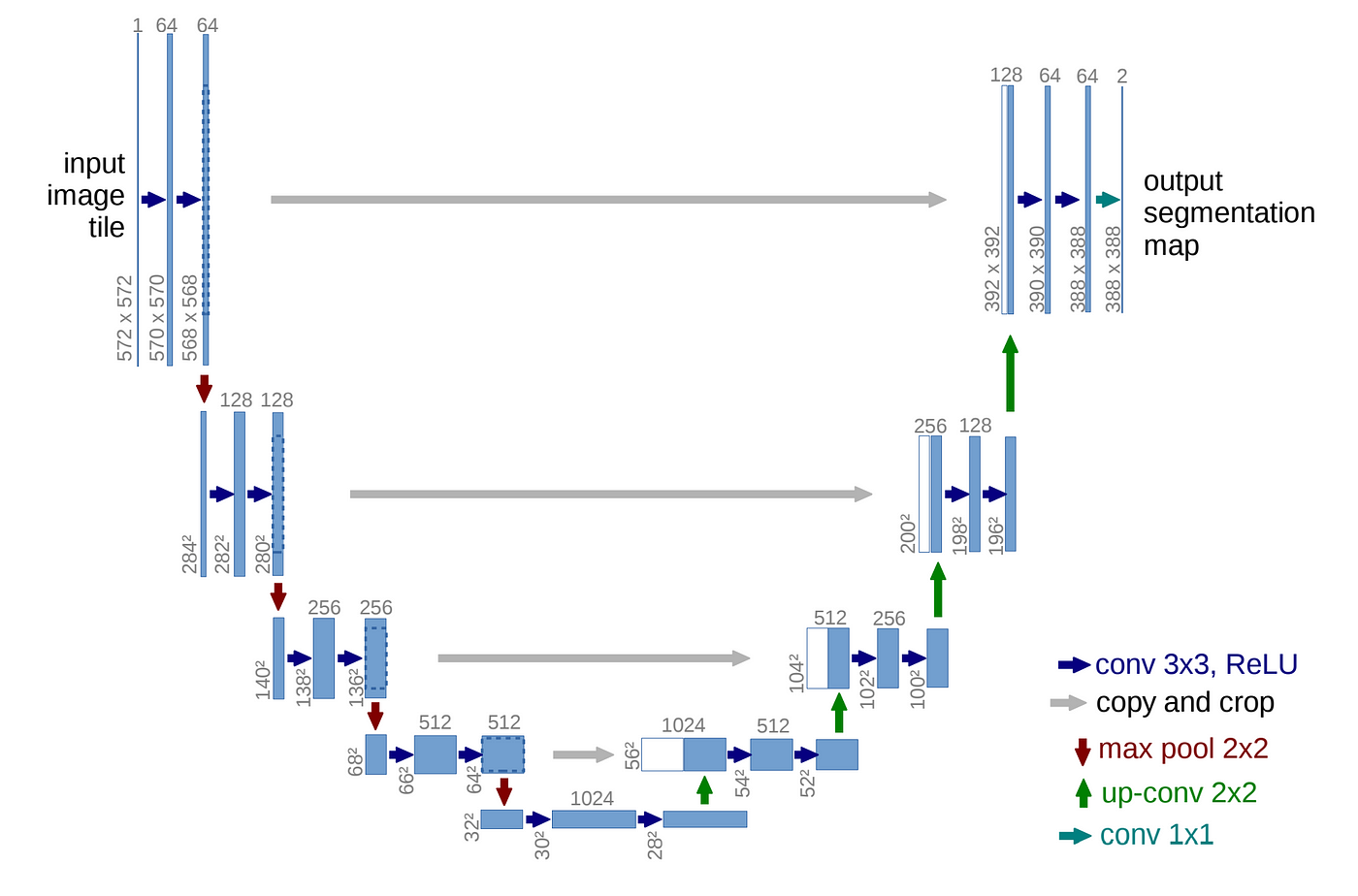
U-Net 은 인코더 또는 축소경로(contracting path)와 디코더 또는 확장경로(expending path)로 구성되며 두 구조는 서로 대칭적이다. 인코더와 디코더를 연결하는 부분을 브릿지(bridge)라고 한다. 인코더와 디코더에서는 모두 3x3 컨볼루션을 사용한다.
✍ contracting path
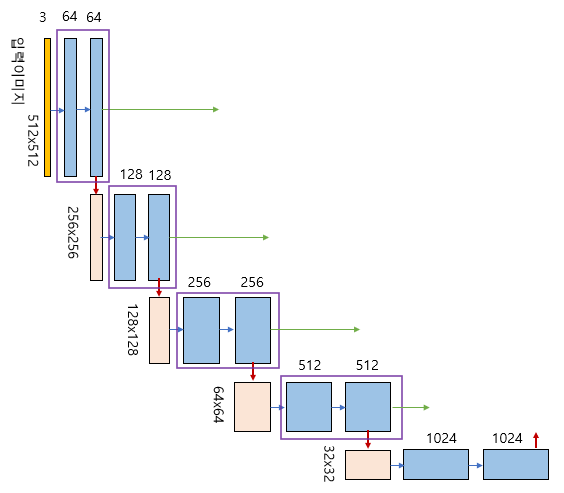
그림에서 세로 방향 숫자는 맵(map)의 차원을 표시하고 가로 방향 숫자는 채널 수를 표시한다.
파란색 박스가 인코더의 각 단계마다 계속 반복하여 나타나는 것을 볼 수 있는데, 이 박스는 3x3 컨볼루션, Batch Normalization, ReLU 활성화 함수가 차례로 배치된 것을 나타낸다.
✍ expansive path
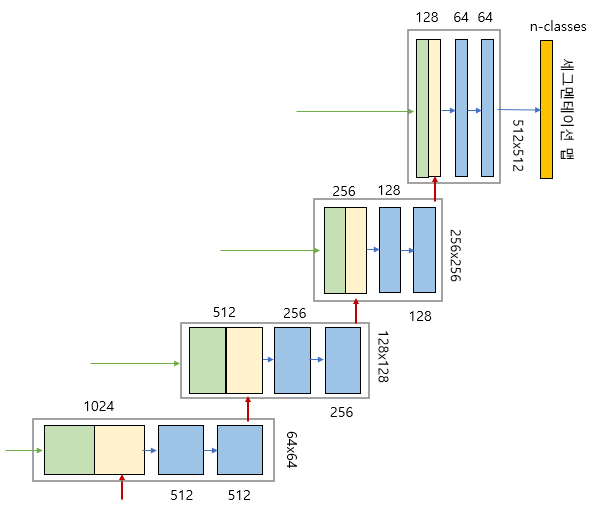
파란색 박스 2개는 인코더에 있는 ConvBlock와 동일하다. 녹색 박스는 스킵 연결을 통해서 인코더에 있는 맵을 복사한 것이다. 노란색 박스는 디코더의 하위 단계에서 전치 컨볼루션(transposed convolution)을 통해서 맵의 차원을 두배로 늘리면서 채널 수를 반으로 줄인 것이다. 두 개의 맵을 서로 합쳐서(concatenation) 저차원 이미지 정보뿐만 아니라 고차원 정보도 이용할 수 있는 것이다.
📙 U-Net Code (Pytorch)
import os
import cv2
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from tqdm import tqdm
import albumentations as A
from albumentations.pytorch import ToTensorV2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# RLE 디코딩 함수
def rle_decode(mask_rle, shape):
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
img[lo:hi] = 1
return img.reshape(shape)
# RLE 인코딩 함수
def rle_encode(mask):
pixels = mask.flatten()
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return ' '.join(str(x) for x in runs)
class SatelliteDataset(Dataset):
def __init__(self, csv_file, transform=None, infer=False):
self.data = pd.read_csv(csv_file)
self.transform = transform
self.infer = infer
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img_path = self.data.iloc[idx, 1]
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
if self.infer:
if self.transform:
image = self.transform(image=image)['image']
return image
mask_rle = self.data.iloc[idx, 2]
mask = rle_decode(mask_rle, (image.shape[0], image.shape[1]))
if self.transform:
augmented = self.transform(image=image, mask=mask)
image = augmented['image']
mask = augmented['mask']
return image, mask
transform = A.Compose(
[
A.Resize(224, 224),
A.Normalize(),
ToTensorV2()
]
)
dataset = SatelliteDataset(csv_file='./train.csv', transform=transform)
dataloader = DataLoader(dataset, batch_size=16, shuffle=True, num_workers=4)
# U-Net의 기본 구성 요소인 Double Convolution Block을 정의합니다.
def double_conv(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1),
nn.ReLU(inplace=True)
)
# 간단한 U-Net 모델 정의
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.dconv_down1 = double_conv(3, 64)
self.dconv_down2 = double_conv(64, 128)
self.dconv_down3 = double_conv(128, 256)
self.dconv_down4 = double_conv(256, 512)
self.maxpool = nn.MaxPool2d(2)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.dconv_up3 = double_conv(256 + 512, 256)
self.dconv_up2 = double_conv(128 + 256, 128)
self.dconv_up1 = double_conv(128 + 64, 64)
self.conv_last = nn.Conv2d(64, 1, 1)
def forward(self, x):
conv1 = self.dconv_down1(x)
x = self.maxpool(conv1)
conv2 = self.dconv_down2(x)
x = self.maxpool(conv2)
conv3 = self.dconv_down3(x)
x = self.maxpool(conv3)
x = self.dconv_down4(x)
x = self.upsample(x)
x = torch.cat([x, conv3], dim=1)
x = self.dconv_up3(x)
x = self.upsample(x)
x = torch.cat([x, conv2], dim=1)
x = self.dconv_up2(x)
x = self.upsample(x)
x = torch.cat([x, conv1], dim=1)
x = self.dconv_up1(x)
out = self.conv_last(x)
return out
# model 초기화
model = UNet().to(device)
# loss function과 optimizer 정의
criterion = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# training loop
for epoch in range(10): # 10 에폭 동안 학습합니다.
model.train()
epoch_loss = 0
for images, masks in tqdm(dataloader):
images = images.float().to(device)
masks = masks.float().to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, masks.unsqueeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {epoch_loss/len(dataloader)}')
test_dataset = SatelliteDataset(csv_file='./test.csv', transform=transform, infer=True)
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=False, num_workers=4)
with torch.no_grad():
model.eval()
result = []
for images in tqdm(test_dataloader):
images = images.float().to(device)
outputs = model(images)
masks = torch.sigmoid(outputs).cpu().numpy()
masks = np.squeeze(masks, axis=1)
masks = (masks > 0.35).astype(np.uint8) # Threshold = 0.35
for i in range(len(images)):
mask_rle = rle_encode(masks[i])
if mask_rle == '': # 예측된 건물 픽셀이 아예 없는 경우 -1
result.append(-1)
else:
result.append(mask_rle)Reference

Vancouver