람다
람다식이란?
- JDK1.8부터 추가된 기능이며, 람다식 혹은 람다함수는 함수형 언어의 특징에서 나온것으로 메서드를 하나의
식(expression)으로 표현한것이다. 실제구현에서는익명 함수형태로 사용된다.
또한 람다식은 메서드의 매개변수로 전달되어질수 있고, 메서드의 결과로 반환될 수도 있다. -> 람다식으로인해 메서드를 변수처럼 다루는것이 가능하다.
int method(){
return (int) (Math.random()*5)+1;
}
//위 메서드를 람다식으로 표현하면
(i) -> (Math.random()*5)+1;람다식을 사용하는 이유
- 불필요한 코드를 줄이고, 코드의 가독성을 높여 이해를 도와준다.
람다식의 특징
-
자바에서는
->와 같은 화살표의 형태를 기호로 사용하여 매개변수를 함수 바디로 전달한다. -
람다식의 형태는
() -> { ... };과 같이 이루어져있고()에는 파라미터가{...}에는 실행문이 들어간다.
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.stream().forEach((Integer i) -> {System.out.println("list = " + i);});
/*결과
list = 1
list = 2
list = 3
*/(Integer i) -> {System.out.println("list = " + i);}이 코드가 위에서 말한 람다식의 형태이다.(Integer i) -> System.out.println("list = " + i)실행문이 한줄로 이루어져 있을때 중괄호를 뺄수있다. 이때;세미콜론도 빼줘야한다.- 또한 위 코드처럼 파라미터의 타입이 예측가능하다면
i -> System.out.println("list = " + i)와 같이 타입을 생략해줘도 된다. - 마지막으로
System.out.println("list = " + i)
(System.out::println)와 같이 표현해줄수도있다.
-
람다표현식을 담을수 있는타입
- 람다표현식은 변수에 대입이 가능하다. 이때 변수의 타입은 함수형 인터페이스 일수있다. 함수형 인터페이스란 하나의 추상 메소드를 갖는 인터페이스를 말한다.
- 함수형 인터페이스로 사용할 인터페이스는 하나의 메서드만을 가질수있으며 이는
@FunctionalInterface를 인터페이스 위에 적어줌으로서 컴파일 검사를 진행할수있다.@FunctionalInterface // 이런식으로 public interface InterfaceSample{ void testMethod() } - 위 코드에서는
testMethod()메서드가 하나라 오류가 안나지만 추가적인 메서드가 있다면 오류가 발생하게 된다. - 우리가 함수형 인터페이스를 정의할 일은 많지않기때문에 참고만 하자.
- 람다표현식은 변수에 대입이 가능하다. 이때 변수의 타입은 함수형 인터페이스 일수있다. 함수형 인터페이스란 하나의 추상 메소드를 갖는 인터페이스를 말한다.
함수형 인터페이스
- 아래 인터페이스는 타입이 모두 Generic 타입이다. -> 기본형 타입의 값을 처리할때도 래퍼 클래스를 사용한다.
- 함수형 인터페이스 종류로는
여기서 T는 Type을 R은 Return Type을 나타낸다
java.lang.Runnable-> 매개변수도 없고, 반환값도 없다
Supplier<T>-> 매개변수는 없고, 반환값만 있다. (랜덤숫자 출력해줄때 등..)
Consumer<T>-> Supplier와 반대로 매개변수만 있고, 반환값이 없다.(매개변수를 받아 출력할때 등..)
Function<T,R>-> 일반적인 함수, 하나의 매개변수를 받아서 결과를 반환한다.(사용할때 apply 이용)public interface Function<T, R> { R apply(T t); }
Predicate<T> -> 조건식을 표현하는데 사용된다. 매개변수는 하나, 반환타입은 boolean
//Predicate<T>의 사용예시, String의 length가 0이면 true를 반환
Predicate<String> isEmptyStr = s -> s.length() ==0;
String s = "";
if(isEmptyStr(s)){
System.out.println("This is an empty String.");
}-
매개변수가 두개인 함수형 인터페이스
T,U,V,W.. 모두 매개변수를 의미한다.
Biconsumer<T,U>-> 두개의 매개변수만 있고, 반환값이 없다.
BiPredicate<T,U>-> 조건식을 표현하는데 사용, 매개변수는2개, 반환값은 boolean.
BiFunction<T,U,R>-> 두개의 매개변수를 받아 하나의 결과를 반환
-
매개변수가 3개 이상일때
- 매개변수가 3개이상일때는 우리가 직접 함수형 인터페이스를 선언하여 만들어야한다.
메서드 참조
- 메서드 참조를 통해 람다식을 간략히 작성할수 있다.
단 메서드 참조를 사용하기 위해서는하나의 메서드만을 호출하는 람다식이여야한다.
- 메서드 참조로 바꾸는 여러 예제
Functional<String,Integer> f = (String s) -> Integer.parseInt(s);
Functional<String,Integer> f = Integer::parseInt;
//생성자의 메소드 참조
Supplier<MyClass> s = () -> new MyClass();
Supplier<MyClass> s = MyClass::new;
//매개변수가 있는 생성자
Function<Integer,MyClass> f = (i) -> new MyClass(i); //람다식
Function<Integer,MyClass> f2 = new MyClass:: new; // 메서드 참조Stream
Stream이란
-
Collection F/W를 통해 관리하는 데이터를 처리하기 위해 주로 사용한다.
-
기존에 우리는 List 에서는 정렬을위해 Collection.sort()를 사용하고, 배열을 정렬할때는 Arrays.sort()를 사용했는데 스트림을 사용하면 데이터 소스를 추상화시켜 같은 기능의 메서드들의
중복을 해결할수 있다.
Stream의 특징
- Stream은 데이터 소스를 변경하지 않는다.
스트림은 데이터 소스로부터 데이터를 읽기만하며, 데이터 소스를 변경하지않는다. 정렬된 결과가 필요하다면 결과값을 컬렉션이나 배열에 담아 반환할수 있다.
Stream<String> strStream1 = strList.stream();// strList는 정렬되지 않은 list라 할때
List<String>sortedStrList = strStream1.sorted().collect(Collectors.toList()); //이런식으로 정렬한 Stream을 저장후 사용가능하다-
Stream은 일회용이다.
스트림은 한번 사용하면 닫혀서 다시사용할수없다. 이미 사용한 스트림을 재사용하고싶다면 스트림을 다시 생성해야한다. -
스트림은 작업을 내부 반복으로 처리한다.
스트림은 반복문을 내부에 숨길수있다. forEach()라는 스트림에 정의된 메서드를 통해 반복된 행위를 할수있다.
for(String str:strList)
System.out.println(str);
stream.forEach(System.out::println) // (str) -> System.out.println(str)을 메서드 참조를 통해 표현;Stream메소드
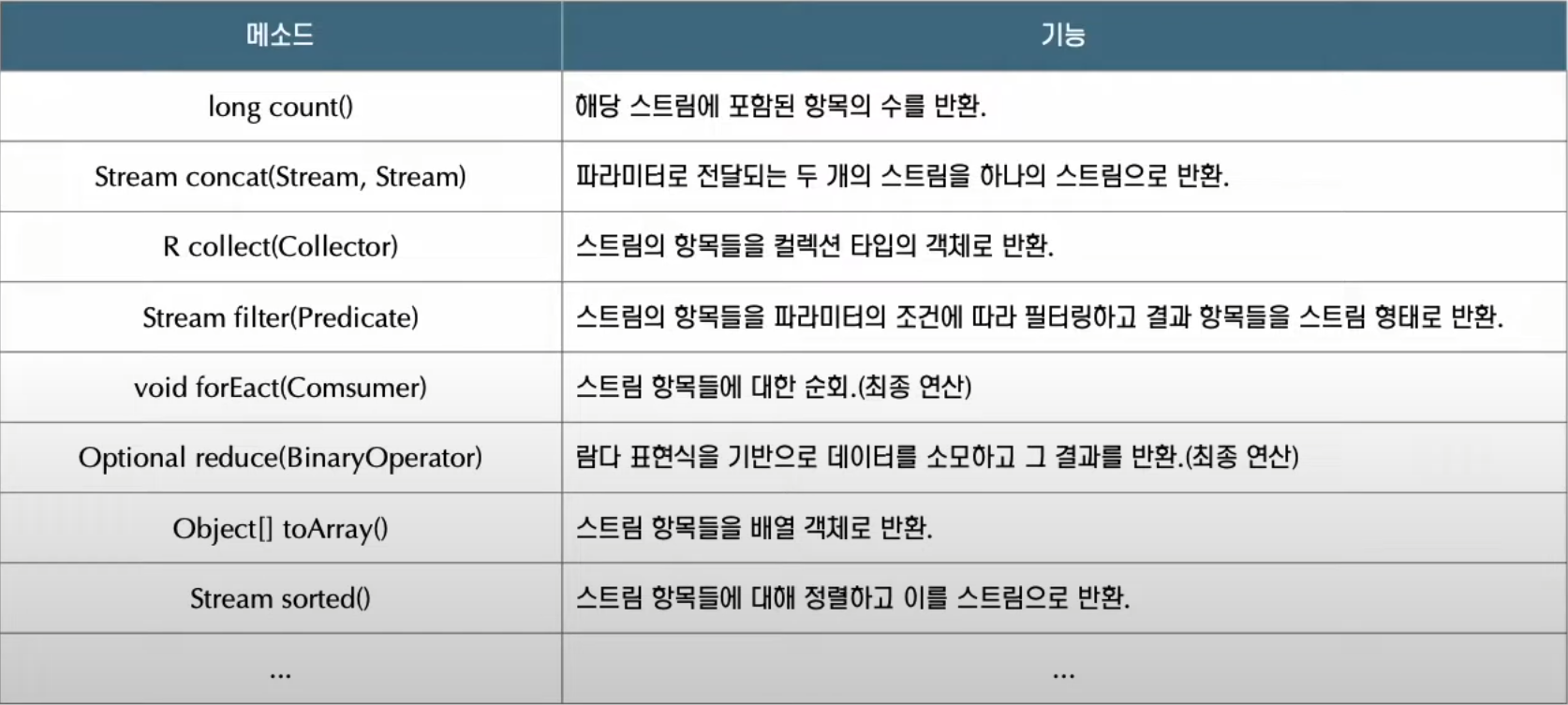
오타(forEact -> forEach)
Stream 객체 생성
-
Collection
List<String> list = Arrays.asList("A","B","C"); Stream<String> stream = list.stream();
- stream()은 컬렉션들의 최고 조상인 Collection에 정의되어 있기때문에 Collection의 자손인 List와 Set을 구현한 컬렉션 클래스들은 모두 .stream()을 통하여 스트림을 생성할수있다.
- 배열
- stream.of 또는 Arrays.stream을 사용하여 문자열 스트림을 생성할수있다.
- int, long, double과 같은 기본형 배열을 소스로 하는 스트림은 IntStream,Arrays.stream을 사용하여 만들수있다.
- 특정 범위
IntStream과LongStream은 지정된 범위의 연속된 정수를 스트림으로 생성하는range()와rangeClose()를 가지고있다.
range()-> 경계의 끝이 포함되지 않는다.
ranged()-> 경계의 끝이 포함된다.
Stream 파이프라인
-
Stream은 연산의 연결을 통해 파이프라인을 구성할수있다. 즉 다양한 연산을 조합할수 있다.
-
이때 각 연산에 필요한 람다표현식을 적용하는것이 중요하다
-
스트림은 중간연산과 최종 연산이 있다.
-
중간 연산
최종 연산이 실행되어야 중간연산이 처리된다.즉 중간연산들로만 구성된 메소드 체인은 실행되지 않는다.
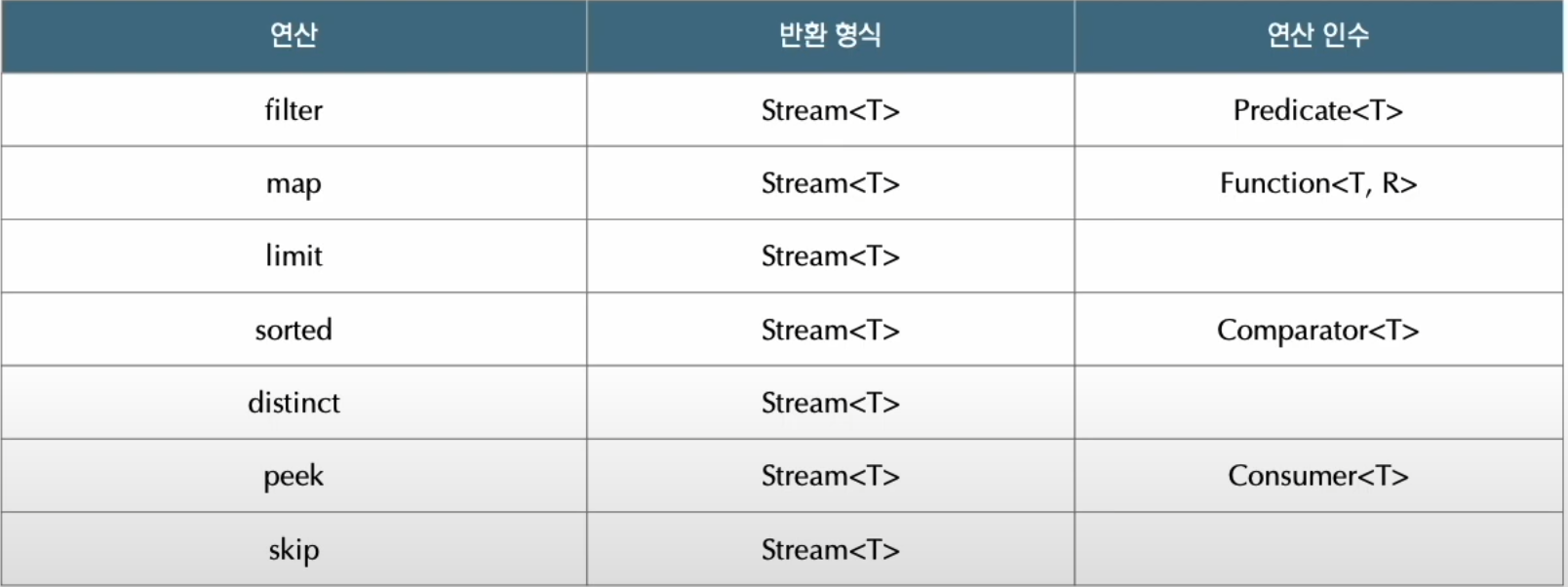
-
skip(), limit()
skip(3)-> 처음 3개의 요소를 건너뛴다.
limit(5)-> 스트림의 요소를 5개로 제한한다.IntStream intStream=IntStream.rangedClosed(1,10); intStream.skip(3).limit(5).forEach(System.out::print); //4,5,6,7,8 -
filter(),distinct()
distinct()-> 중복된 요소들을 제거한다.
filter()-> 주어진 조건에 맞지 않는 요소를 걸러낸다. 이때 filter()는 매개변수로 Predicate를 필요로한다
Predicate대신 i -> i%2 ==0 와 같은 람다식을 사용해도 된다.intStream.filter(i->i%2==0).forEach(System.out::print);
필요에따라 .filter().filter() 처럼 여러개의 filter를 연결해도 된다.
-
sorted()
sorted()는 Stream을 정렬할때 사용한다.
-
map()
map()은 Stream의 요소에서 저장된 값들중 원하는 필드만 뽑아내거나 특정 형태로 변환할때 사용하며, 연산결과는Stream<T>이다.List<String> names=Arrays.asList("John","Jane","Jim"); // Use the map method to convert each name to uppercase List<String> upperCaseNames=names.stream() .map(name->name.toUpperCase()) .collect(Collectors.toList()); // Print the result upperCaseNames.forEach(System.out::println); //result JOHN JANE JIM -
mapToInt(),mapToLong(),mapToDouble()
-
map()의 연산결과는
Stream<T>이다. 이때 스트림의 요소를 숫자로 변환하는 경우IntStream과 같은 기본형 스트림으로 반환하는게 더 유리할때가 있다. 이때 사용하는것이 위 3개의 메서드이다. -
Stream<T>는 count()만 지원하지만 IntStream과 같은 기본형 스트림은sum(), average(), max(), min()숫자를 다루기 편한 메서드를 제공한다. -
sum(), average(), max(), min()이 4개의 메서드들은 최종연산이라sum()과average()를 출력한다던가 두개를 연속으로 사용할수 없다. -
반대로
IntStream을 Stream로 변환할때는mapToObj()를 Stream로 반환할때는boxed()를 사용한다.
- flatMap()
-
스트림의 요소가 배열이거나 map()의 연산결과가 배열일때, 즉 스트림의 타입이
Stream<T[]>인 경우, Stream로 다루는게 편할때가 있는데 이때 map대신flatMap()을 사용하면 된다. -
즉, 메서드에 의해 생성된 모든 개별 스트림이 하나의 단일 스트림으로 병합된다고 생각하면된다.
- peek()
peek()은 연산과 연산 사이에 올바르게 처리가 되고있는지 확인하고 싶을때 사용한다.
filter()또는map()의 결과를 확인할때 유용하다.
-
최종연산
- 중간 연산을 통해 가공된 스트림을 최종연산을 통해 소모하며 결과를 출력한다.
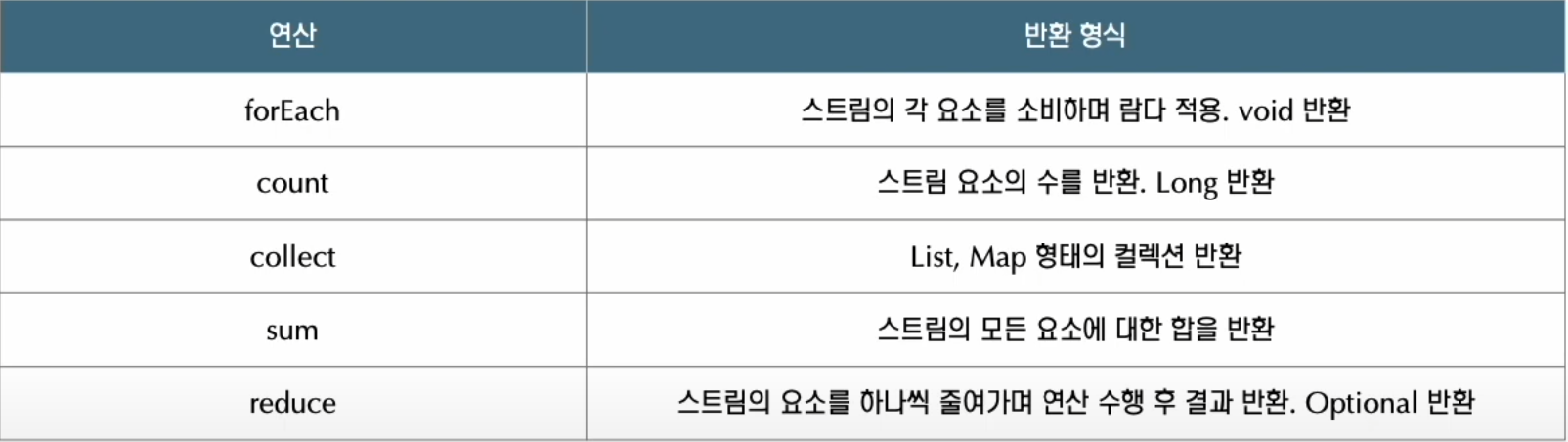
- 위에서도 말했지만 최종 연산후 소모한 스트림은 재사용이 불가능하다.
List<String> list = Arrays.asList("APPLEMANGO","BANANA","CHOCOLATE"); List<String> isContainApple = list.stream() .filter(str -> str.contains("APPLE")) .collect(Collectors.toList()); System.out.println(isContainApple); //출력 // [APPLEMANGO]- 위 코드와 같이 filter(중간연산) -> collect(최종연산) 으로 이루어져야 우리가 원하는 결과가 나온다.
- 중간 연산을 통해 가공된 스트림을 최종연산을 통해 소모하며 결과를 출력한다.
Reference
