[Java] 함수형 인터페이스 (Functional Interface) (ft. 메서드 참조, Boxing/Unboxing)
오늘은 함수형 인터페이스에 대해서 정리해보려고한다.
이 내용은 몰랐던 내용이어서 처음에는 이해하기 어려웠고 함수 하나를 정의하려고 뭐하러 만들어놨나 했는데 동작을 이해하고 콜백함수라는 개념을 이전에 학습하고 보니까 아주 편리한 패키지라는 생각이 들었다.
함수형 인터페이스란?
- 하나의 추상 메서드만 갖는 인터페이스
- 단, Object 클래스의 메서드(toString, equals 등)는 제외된다
- 추상 메서드는 하나여야 하지만 default, static 메서드는 여러 개 있어도 된다

자바에 함수형 인터페이스가 왜 있나?
자바는 원래 객체지향 언어 → "함수만 전달"하는 것이 불가능하다.
그런데 함수형 프로그래밍 패러다임(스트림 API, 병렬 처리 등)을 지원하려면 "함수를 값처럼 전달"할 방법이 필요하다
그래서 람다식 + 함수형 인터페이스를 도입한 것이다.
함수형 인터페이스는 람다의 타입을 정해주는 역할을 하며, 자바 코드의 간결성, 가독성, 재사용성을 크게 높인다.
(일반적으로 T는 Type을, U는 두 번째 Type을, R은 Return을, E는 Element를 의미)
(1) Supplier
설명: 매개변수 없고, T 타입 결과만 반환
메서드: T get()

예시

(2) Consumer
설명: T 타입 매개변수만 받고, 반환 없음
메서드: void accept(T t)

예시

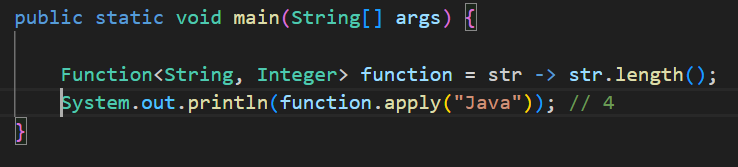
(3) Function<T,R>
설명: 입력 T → 출력 R
메서드: R apply(T t)

예시
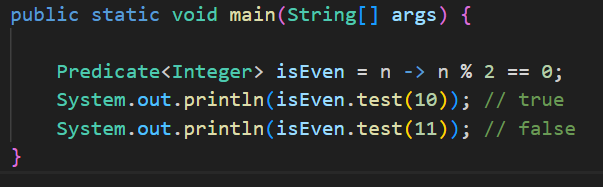
(4) Predicate
설명: 입력 T → 출력 boolean
메서드: boolean test(T t)

예시
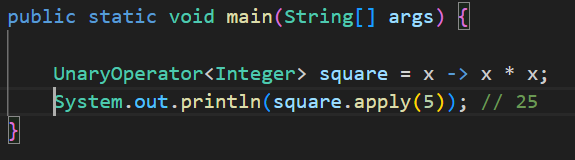
(5) UnaryOperator
설명: 입력 T → 출력 T (Function의 특수화)

- 추가 메서드 없이 Function<T,T> 그대로 사용
- static 메서드 몇 개 있을 수 있음
예시
(6) BinaryOperator
설명: (T, T) → T (Function의 특수화)
- 추가 메소드 없음
- minBy, maxBy 제공
- BiFunction<T, T, T>를 확장한 특화 인터페이스
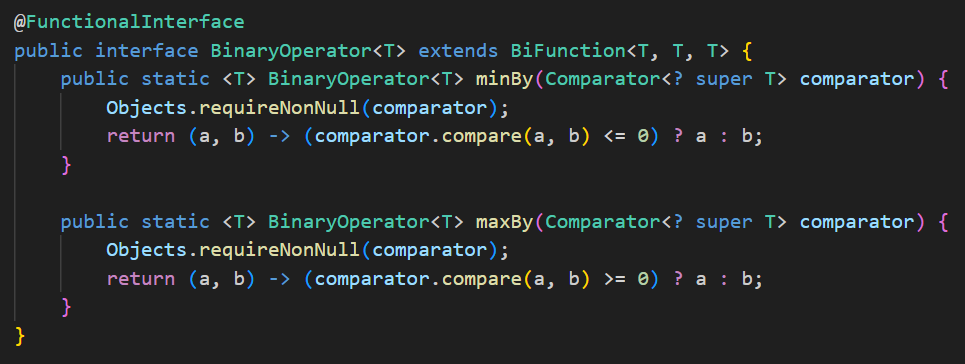
예시

(7) BiFunction<T,U,R>
설명: (T, U) → R (두 개의 인자를 받는 Bi 인터페이스)
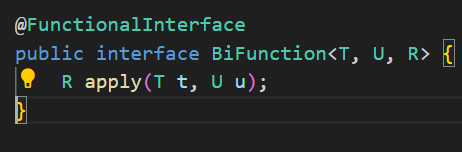
예시

(8) BiConsumer<T,U>
설명: (T, U) → void
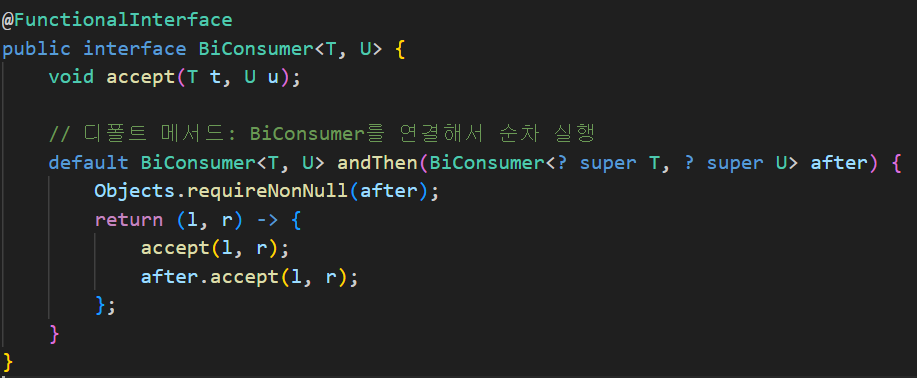
예시

(9) BiPredicate<T,U>
설명: (T, U) → boolean

예시
(10) 기본형 특화 인터페이스
박싱/언박싱 오버헤드 줄이려고, int, long, double 전용 버전도 있음
- IntSupplier, IntConsumer, IntFunction, IntPredicate, LongFunction, DoublePredicate, DoubleUnaryOperator, ...
예시
🔖 박싱(Boxing) / 언박싱(Unboxing) 이란?
자바의 데이터 타입에는 두 가지가 있다.
- 기본형(primitive): int, long, double … (가벼운 값 타입)
- 래퍼 클래스(wrapper class): Integer, Long, Double … (객체 타입)
자바는 객체만 제네릭 타입에 쓸 수 있다.
즉, Function<T, R> 같은 제네릭에 int 같은 기본형은 못 넣는다.
그래서 int → Integer로 감싸야 한다.
이걸 박싱이라고 하고, 반대로 Integer에서 int 꺼내는 걸 언박싱이라고 한다.
🔖 박싱/언박싱이 문제되는 상황
예를 들어, Predicate로 숫자를 검사한다고 해보자
Predicate<Integer> isEven = n -> n % 2 == 0;
System.out.println(isEven.test(10)); // 내부에서 Integer → int (언박싱)
System.out.println(isEven.test(20)); // 또 Integer → int (언박싱)여기서 실제 10은 기본형 int지만, Predicate를 쓰려면 자동으로 박싱/언박싱이 발생한다
이건 아주 많은 연산에서 성능 손실을 일으킬 수 있다
🔖 그래서 기본형 특화 인터페이스가 나온 것이다
자바 8은 이런 오버헤드를 줄이려고, 아예 int, long, double 전용 함수형 인터페이스를 따로 만들어놨다.
예시:
Predicate<Integer>대신IntPredicate
Function<Integer, R>대신IntFunction<R>
Supplier<Integer>대신IntSupplier
🔖 비교 예시
(1) 일반 Predicate 사용
Predicate<Integer> isPositive = n -> n > 0;
System.out.println(isPositive.test(5));
// 내부적으로 Integer → int 변환(2) 기본형 전용 IntPredicate 사용
IntPredicate isPositive = n -> n > 0;
System.out.println(isPositive.test(5));
// int 그대로 사용, 박싱/언박싱 없음→ 두 코드의 동작은 같지만, IntPredicate는 불필요한 객체 생성 없이 순수 int 연산만 하므로 효율적이다.
📌 자바 함수형 인터페이스 정리표 (java.util.function)
구분 인터페이스 메서드 시그니처 설명 사용 예시 값 생성 Supplier<T>T get()입력 없이 값 생성 Supplier<Double> sup = Math::random; sup.get();값 소비 Consumer<T>void accept(T t)입력 받아 처리, 반환 없음 Consumer<String> c = System.out::println; c.accept("Hi");BiConsumer<T,U>void accept(T t, U u)두 개 입력 소비 (name, age) -> System.out.println(name+"-"+age)조건 검사 Predicate<T>boolean test(T t)입력 → true/false Predicate<Integer> p = x -> x>0; p.test(5);BiPredicate<T,U>boolean test(T t, U u)두 입력 → true/false (a,b) -> a.equalsIgnoreCase(b)값 변환 Function<T,R>R apply(T t)T → R Function<String,Integer> f = String::length;BiFunction<T,U,R>R apply(T t, U u)(T,U) → R (a,b) -> a+bUnaryOperator<T>T apply(T t)(T→T) 자기 자신 타입 변환 UnaryOperator<Integer> u = x -> x*x;BinaryOperator<T>T apply(T t1,T t2)(T,T) → T BinaryOperator<Integer> add=(a,b)->a+b;
📌 기본형 특화 인터페이스
인터페이스 메서드 설명 예시 IntSupplierint getAsInt()int 반환 IntSupplier s=()->42;IntConsumervoid accept(int)int 소비 IntConsumer c = System.out::println;IntPredicateboolean test(int)int 조건 검사 x->x>0IntFunction<R>R apply(int)int → R (x)->"num="+xIntUnaryOperatorint applyAsInt(int)int → int x->x*2IntBinaryOperatorint applyAsInt(int,int)(int,int)→int (a,b)->a+bToIntFunction<T>int applyAsInt(T)T → int (s)->s.length()ObjIntConsumer<T>void accept(T,int)(T,int) 소비 (name,score)->...
📌 Long 전용
인터페이스 메서드 설명 LongSupplierlong getAsLong()long 반환 LongConsumervoid accept(long)long 소비 LongPredicateboolean test(long)long 조건 검사 LongFunction<R>R apply(long)long → R LongUnaryOperatorlong applyAsLong(long)long → long LongBinaryOperatorlong applyAsLong(long,long)(long,long) → long ToLongFunction<T>long applyAsLong(T)T → long ObjLongConsumer<T>void accept(T,long)(T,long) 소비
📌 Double 전용
인터페이스 메서드 설명 DoubleSupplierdouble getAsDouble()double 반환 DoubleConsumervoid accept(double)double 소비 DoublePredicateboolean test(double)double 조건 검사 DoubleFunction<R>R apply(double)double → R DoubleUnaryOperatordouble applyAsDouble(double)double → double DoubleBinaryOperatordouble applyAsDouble(double,double)(double,double) → double ToDoubleFunction<T>double applyAsDouble(T)T → double ObjDoubleConsumer<T>void accept(T,double)(T,double) 소비
📌 핵심 요약
일반(Generic): Supplier, Consumer, Function, Predicate (+Bi, +Operator)
기본형 특화: IntXXX, LongXXX, DoubleXXX (+ToIntFunction 등)
효과:
-
기본형을 Integer, Double로 박싱/언박싱하지 않고 직접 처리 가능
-
성능 최적화 + 불필요한 객체 생성 방지
메서드 참조란?
람다식에서 이미 있는 메서드를 그대로 호출만 하는 경우, 람다를 더 간단히 표현하는 문법
즉, str -> str.length() 이걸 String::length 로 줄여 쓸 수 있는 것.
람다식 ↔ 메서드 참조 1:1 변환 표
람다식 메서드 참조 대상 인터페이스(예) x -> System.out.println(x)System.out::printlnConsumer<T>s -> s.length()String::lengthToIntFunction<String>/Function<String,Integer>s -> s.toLowerCase()String::toLowerCaseFunction<String,String>s -> Integer.parseInt(s)Integer::parseIntFunction<String,Integer>(a,b) -> Integer.compare(a,b)Integer::compareIntBinaryOperator/Comparator<Integer>list -> list.size()List::sizeToIntFunction<List<?>>(map,k) -> map.get(k)Map::getBiFunction<Map<K,V>,K,V>() -> new ArrayList<>()ArrayList::newSupplier<List<?>>n -> Math.abs(n)Math::absIntUnaryOperator/Function<Integer,Integer>len -> new String[len]String[]::newIntFunction<String[]>
🔹오늘 성취한 것
늘 익숙하게 사용하던 것을 반복해서 사용하지 새로운건 선뜻 받아들이기 어려운데 오늘 드디어 맨날 보고 지나가기만 했던 람다를 정리했다.
🔹겪은 문제와 개선 방법
아무래도 수업을 듣다가 내가 막히는 부분이 생기면 다음으로 넘어가기가 힘든데 이렇게 글로 일목요연하게 정리를 하니 좀 더 정리가 되는 것 같다.
🔹오늘 학습한 것
자바에서는 콜백함수를 안써봐서 함수형 인터페이스는 몰랐는데 이렇게 공부할 수 있어서 좋았다. 내부적으로 구현되어있는 코드와 함수를 보면서 예전에는 C와 크게 다르지 않게 자바를 사용했는데 유용한 패키지를 공부하며 한걸음 더 성장할 수 있었던 것 같다.
