클라우드 데이터 플랫폼을 구성하는 최신 기술 알아보기
강웅석 발표자
주관이 은연 들어갔을 수도 있다.
- 데이터 플랫폼의 과거와 현재
- 다양한 클라우드 데이터 플랫폼 패러다임 살펴보기
- 차세대 데이터 플랫폼 기술 살펴보기 - Apache Iceberg, Delta Lake
Hadoop? Cloudera? Hortonworks?
-> Amazon Redshift? Amazon Athena? Google BigQuery? MySQL?
데이터 플랫폼 춘추전국시대이다.

그래서 데이터 플랫폼이 뭔데?
- 아주 다양한 형태의 데이터를 (정형, 비정형, 반정형)
- 엄청 많이 저장할 수 있고 (PB+)
- 내 인내심을 자극하지 않은 선에서 조화가 가능
- 사내 구성원 모두가 동시에 데이터를 조회해도 잘 조회되어야 하고
- 보안 문제
- 적은 비용 유지보수
- 퇴사해도 돌아갈 수 있고
- 개발자 아닌 사람도 보고
- 인프라 비용 너무 많이 안 써도 되고
...

근데 데이터 플랫폼이 왜 필요한데?
- 다양한 지표와 통계(매출, AU...)
- 데이터를 통한 의사결정
- 데이터 기반 서비스(검색, 추천, 인기도...)
데이터 플랫폼의 여러 패러다임
- Data Warehouse (DB w/ Distributed Storage, Query Engine)
- Data Lake (Distributed Storage / Distributed Query Engine / Meta Store)
- Data Lakehouse (?) - 약간 마케팅 용어라고 생각합니다.

데이터 웨어하우스랑 레이크 옛날부터 있었다. 웨어하우스에 MySQL과 레이크에 Hadoop처럼.
Pros of Data Lake
- 아무 데이터 막 저장 가능 (ETL) > image, audio도 가능
- 별도의 ingestion 과정이 필요 없다: storage에 적재하면 끝
- Storage가 SSoT가 되기 때문에 풍부한 storage 기능 사용 가능 + 입맛에 맞는 query engine 사용 가능(SQL, API, Code, Framework, External read를 지원하는 다양한 제품들)
- 대부분의 클라우드는 storage가 제일 저렴하다. 또한, 안 쓰는 데이터에 대해 tiering도 가능. (그냥 hard storage에 넣으면 가격이 높을 위험이 있다.)
- External, schema-on-read 방식의 비교적 유연하고 programmatic API를 지원하는 metadata system: Hive, Glue, Dataproc Metastore 등.
Cons of Data Lake
- Underlying storage의 제약을 그대로 적용받는다(e.g. EC, rename, ACID, streaming, ...)
- 사용자가 storage를 어떻게 사용하느냐에 따라 성능이 천차만별이다: data type, format, compression, directory structure, block size, ...)
- Lake를 구성하ㅏ는 component가 너무 많다: storage, query engine, metastore, ...
- 데이터 관리가 상대적으로 더 어렵다 = Data swamp
- External schema 관리가 복잡하다 = file format 별로, store 별로, query engine 별로 다르고 schema evolution이 비가역적인 경우도 있다. Column 추가가 불가하다.
- SQL 만으로 데이터 관리를 할 수 없다. - Update, Delete?
stripe 구조,
Pros of Data Warehouse
- 사용자가 신경 쓸 것이 많이 없다: ingestion하고, 나머지는 전부 DW가 알아서 해주거나 사용자가 DW의 기능을 이용해서 customize하면 된다.
- Internal metadata (schema-on-write)기 때문에 schema evolution 같은 것이 비교적 자유롭다.
-- 다만 돈이 들 수 있다. 특정 연산들은 전체를 다 날리고 새로 만드는 경우가 있음. - 단순 query engine 이상의 기능들을 제공하는 경우가 있다: ...
Cons of Data Warehouse
- Ingestion 과정이 있다.
- DW에서 지원해주지 않은 기능은 사용할 수 없다: image, audio...

Price Comparison

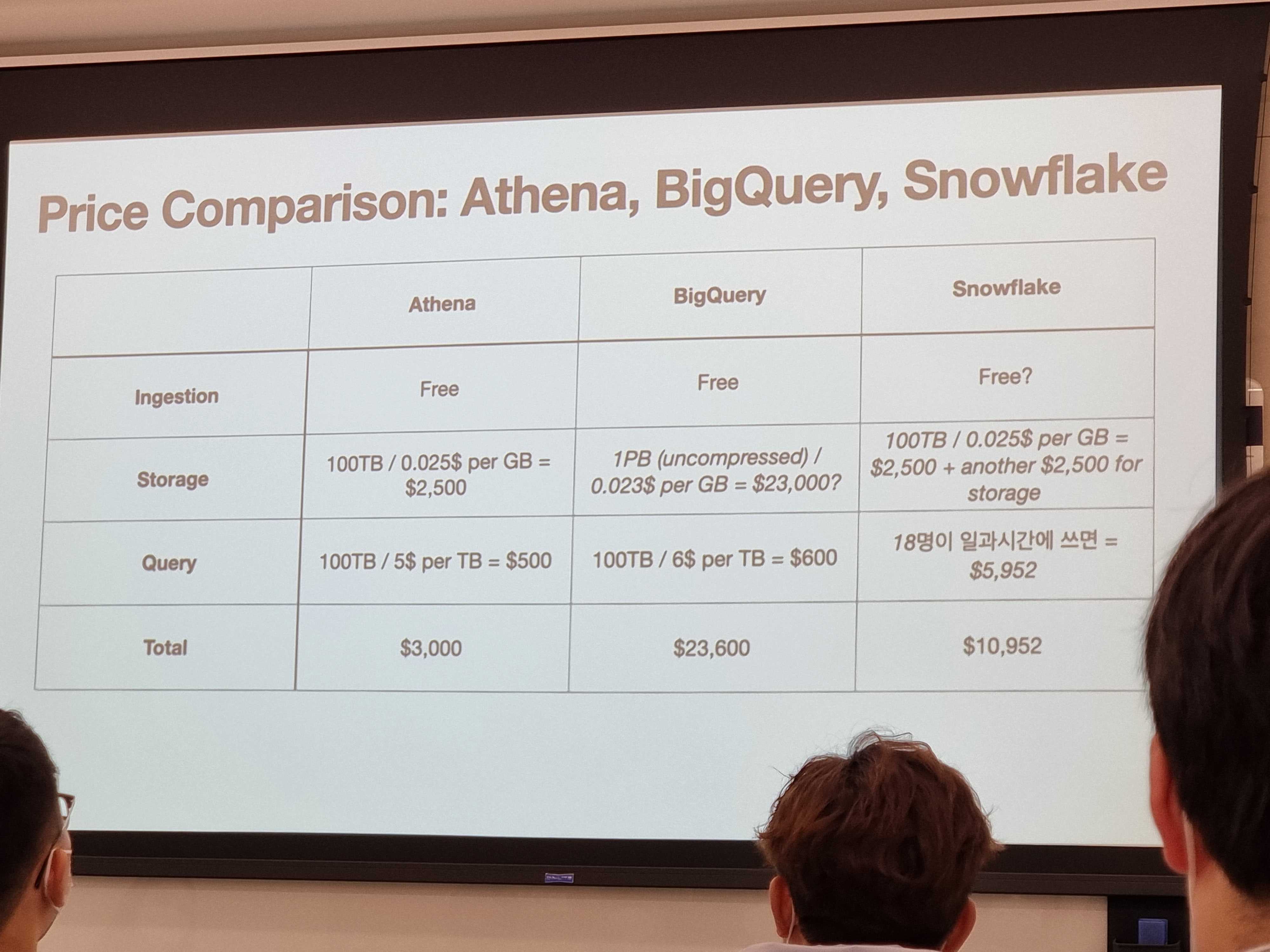
기술마다 장단점이 있지만, 보통 돈을 쓰면 장점만 남는다
또한 특정 단점들은 Warehouse에도 존재한다
차세대 데이터 플랫폼 프레임워크
- Delta Lake
- Databricks 주도로 오픈소스
- Apache Iceberg
- 오픈소스
참고로 우버에서는 Apache Hudi를 쓴다.
Features of Delta Lake / Iceberg

어떻게 쓸 수 있나요?
Iceberg는 아테나에서 네이티브로 제공.
비즈니스에 맞는 기술 선택이 중요하다.
그러려면 기술에 대한 풍부한 이해가 필요하다.
Delta Lake & Iceberg 프로덕션 써도 되나요?
- Delta Lake의 경우 외국에서 쓰이고 있고, 국내에도 몇 곳이 있다.
Athena는 BigQuery보다 느릴까?
Redshift는 별로일까?
- Redshift는 DW이긴 하지만, OLAP에 더 가깝다고 볼 수 있다.
-- Druid, Clickhouse처럼
시계열, 그래프 데이터도 데이터 플랫ㅅ폼에 넣을 수 있나요?
- 시계열
-- 물론, InfluxDB같은 것을 기대하면 안 된다. - 그래프
-- 역시 넣을 수 있지만, 그래프 형태를 row로 풀어서 넣는 것이 당장은 좋다.

For engineering purposes.