호스트: 오민석, Marcus Oh, Sr. Solution Architect–Automotive IBD Korea & NVIDIA
Katie Washabaugh, Automotive Marketing Manager, NVIDIA
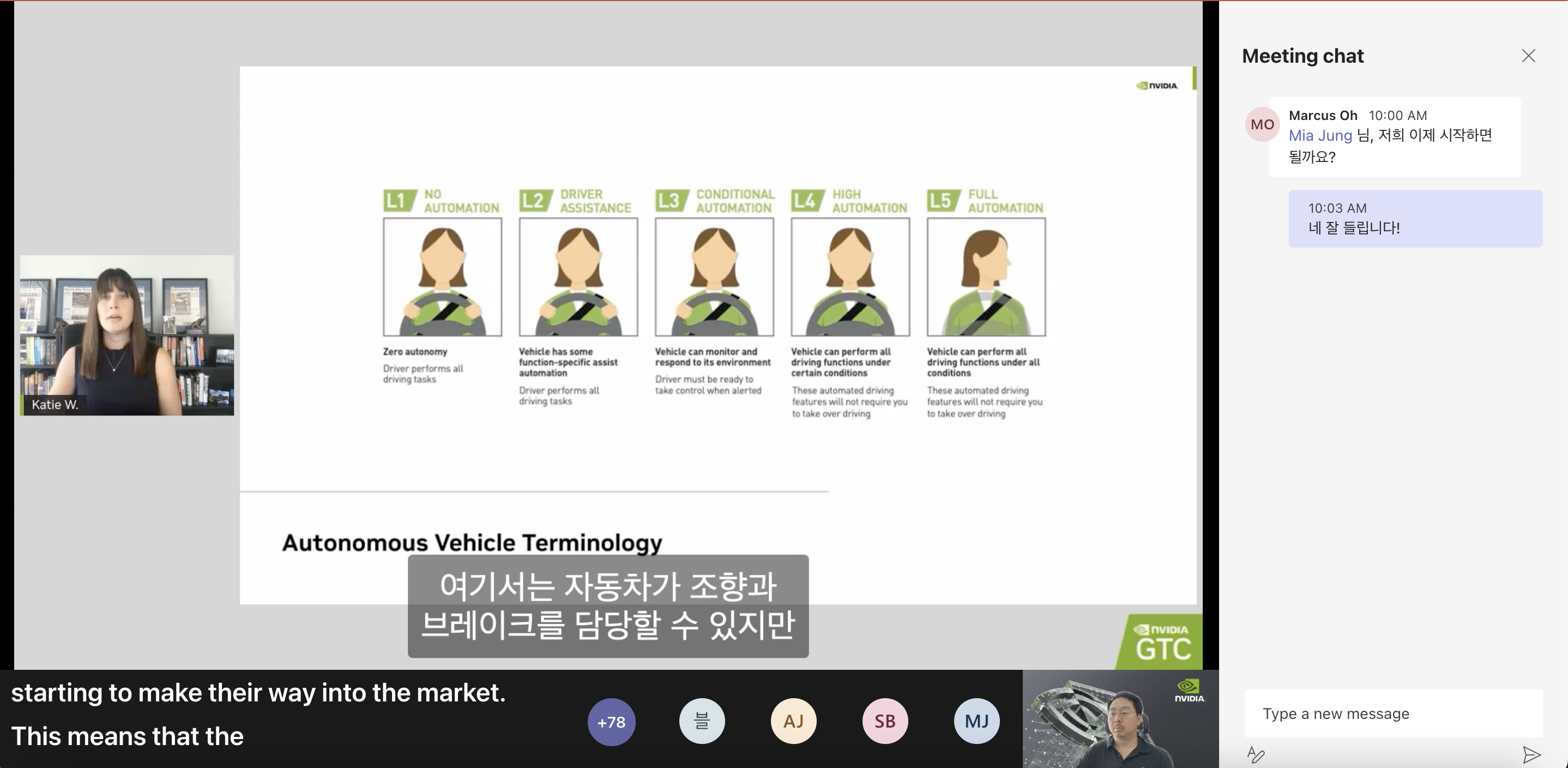
지금 보여지는 사진은 어떤 센서에서 받은 데이터를 시각화한 건가요?
- 라이다 센서라고 하시네요~
데이터를 한꺼번에 모아서 퓨전해서 처리하는 것은, 한 번 걸러진 데이터를 받는 것 대비해 구체적으로 어떤 장점이 있나요?
- 좀 더 첨언을 드리면 한번 처리된 데이터의 경우 원하는 정보가 없을 수도 있어서 점점 센서에서의 RAW data를 가지고 원하는 정보를 얻어서 처리하려는 노력이 일어나고 있습니다.
- Orin SoC가 TOPS 256이라고 했는데, Jetson 형태의 Board로 구성되어야 가능한건지 저 단일 칩으로만 구현 가능한건지요?
- 키노트 보면 차안에서의 딥러닝 데이터센터에서의 딥러닝이라고 말하는데, 예를 들어 벤츠 같은 회사에 칩을 제공하면 데이터센터는 어느회사거를 이용하는걸까요?
데이터 센터의 경우는 여러가지 경우가 있을 수 있어서 다양한 형태로 구성이 가능하며 데이터센터에서는 모아진 데이터를 가지고 딥러닝 모델을 만드는 작업을 진행하고 있기 때문에 서버나 NVIDIA의 SuperPOD형태의 서버를 사용해서 구성해서 데이터 처리하는 용량에 맞게 구성을 하게 됩니다.
https://developer.nvidia.com/drive
HIL 이 잘 이해가 안되는데요
자동차에 들어가는 H/W를 동일하게 구성해서 Test한다는것은 이해되는데, 어느 장치에 넣어서 어디서 평가하는걸까요?
-
예를 들어서 NVIDIA SOC로 보드를 만들고 외부에서 센서를 받을 수 있는 포트를 통해서 SIL에서 만들어진 센서 데이터를 별도의 보드를 만들어서 NVIDIA SoC로 만든 보드로 보내면 보드는 센서에서 데이터를 직접 받게 되므로 해당 보드에서 실제 딥러닝 모델이나 SW들에 대한 테스트를 실상황과 유사하게 테스트를 하게 됩니다.
-
평가의 경우는 각 회사별로 목표하시는 부분이 있을텐데, 각 평가 항목별로 리스트를 만들어서 해당 항목이 실제 HIL 상황에서 meet가 되었는지 확인을 하게 됩니다.
결국 합성 데이터(synthetic data)를 만들고, 이를 이용해서 자율주행 플랫폼을 학습시키는 것으로 이해했습니다. 합성 데이터의 품질이 실제 자율주행 플랫폼이 운영될 때의 입력 데이터 품질하고 차이가 있을 것으로 예상됩니다. 혹시 그 차이가 자율주행 플랫폼의 학습결과에 미치는 영향이 분석된 것이 있을까요?
- 결국 "유사한 데이터"를 이용해서 학습한 결과를 안전이 중요한 실제 문제에 적용할 때 발생하는 문제에 대한 검토 결과나 사례 보고가 있었는지 궁금해서 질문 드렸습니다.
국내에서 DRIVE Map 제작이 진행중이거나 구축 계획이 있을까요?
딥러닝이 확률 모델이라고 계속 강조하셨는데요, 확률을 높여나가는 것도 중요하겠지만 최근에는 결국 원격 관제, 제어 등 인간의 개입은 꼭 필요하다는 주장도 많이 나오고 있는 것 같습니다(안전관점). 혹시 여기에 대해서는 어떻게 생각하시는지 궁금합니다~
답변 감사드립니다.
추가로 연산능력이 높아지게 되면 소비전력도 자연스레 높아질것으로 예상되는데 배터리 문제도 연관될 것 같아서요.. 혹시 관련 솔루션이 있을까요??
자율주행 플랫폼 데모가 국내에서도 가능한가요?
아까 SoC 얘기할 때 계속 연산능력을 높인다고 했는데, 어제 키노트 보니깐 2000TOPS SoC도 개발 목표로 세웠더라고요. 반면, 모빌아이는 176TOPS로도 충분하다고 하는데.. 이는 어떤 차이점으로 연산능력 목표가 다르다고 이해하면 될까요..?^^;
-
센서들이 점점 많아지고 해상도가 높아지고 모델은 점점 더 복잡하고 DL모델이 많아지고 동시에 이런 것들을 실시간으로 처리하려면 SoC의 성능을 더 높아질 수 밖에 없을 거 같습니다. 이전에 말씀드린 센서의 RAW데이타를 처리하는 부분의 예를 들면 좀 더 높은 computing파워가 필요하게 되는 것으로 이해해주시면 좋을 거 같습니다.
-
오늘 함께 보신 자료는 오리지널 세션 페이지(아래 링크)에서 다운로드 가능합니다. https://www.nvidia.com/ko-kr/gtc/session-catalog/?tab.catalogallsessionstab=16566177511100015Kus&search=41086#/session/1654189465342001Qrrl
좋은 발표 감사합니다.
자율주행을 연구중인 박사과정 학생인데요, 혹시 NVIDIA에서는 자율주행을 위해 레이다를 어떤 식으로 활용하는지 알 수 있을까요?
(e.g., 사용하는 센서 종류, 카메라와 퓨전 방법, 전체 sensor suite 중 레이다의 중요도 등)
좋은 발표 감사합니다. 자율주행을 연구중인 박사과정 학생인데요, 혹시 NVIDIA에서는 자율주행을 위해 레이다를 어떤 식으로 활용하는지 알 수 있을까요? (e.g., 사용하는 센서 종류, 카메라와 퓨전 방법, 전체 sensor suite 중 레이다의 중요도 등)
-
https://developer.nvidia.com/drive/drive-hyperion
이쪽의 링크를 가보시면 저희가 사용하는 센서들에 대한 설명이 있습니다. 이부분을 참조해주시면 좋을 거 같습니다.
