2022-09-14
리눅스 파운데이션 주최 ScyllaDB 세미나에 참여했고, 그에 대한 내용을 공유한다.
Under the Hood of a Shard-per-Core Database Architecture




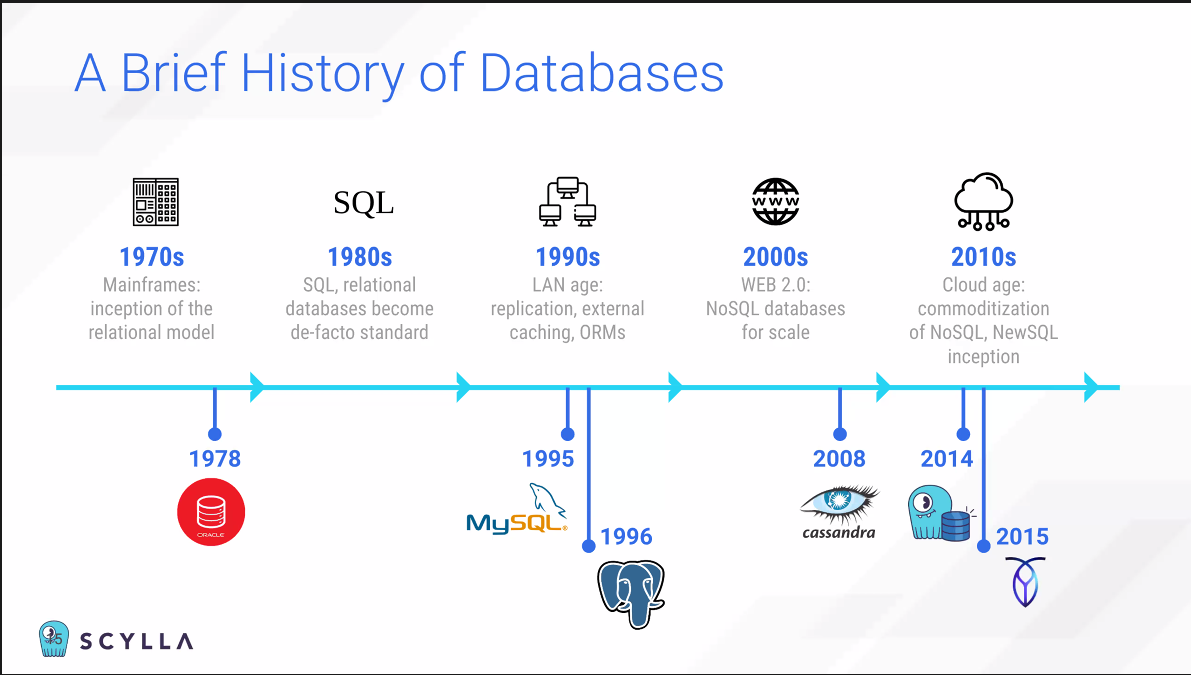
ScyllaDB는 NoSQL 데이터베이스이다. 퍼포먼스에 집중한 데이터베이스이다. 목적은 두 가지인데, throughput을 높이는 것과 latency를 낮추는 것이다. C++를 통해 깃헙 활용할 수 있으나, Docker를 통해서 패키지를 실행하면 시간을 단축할 수 있다.

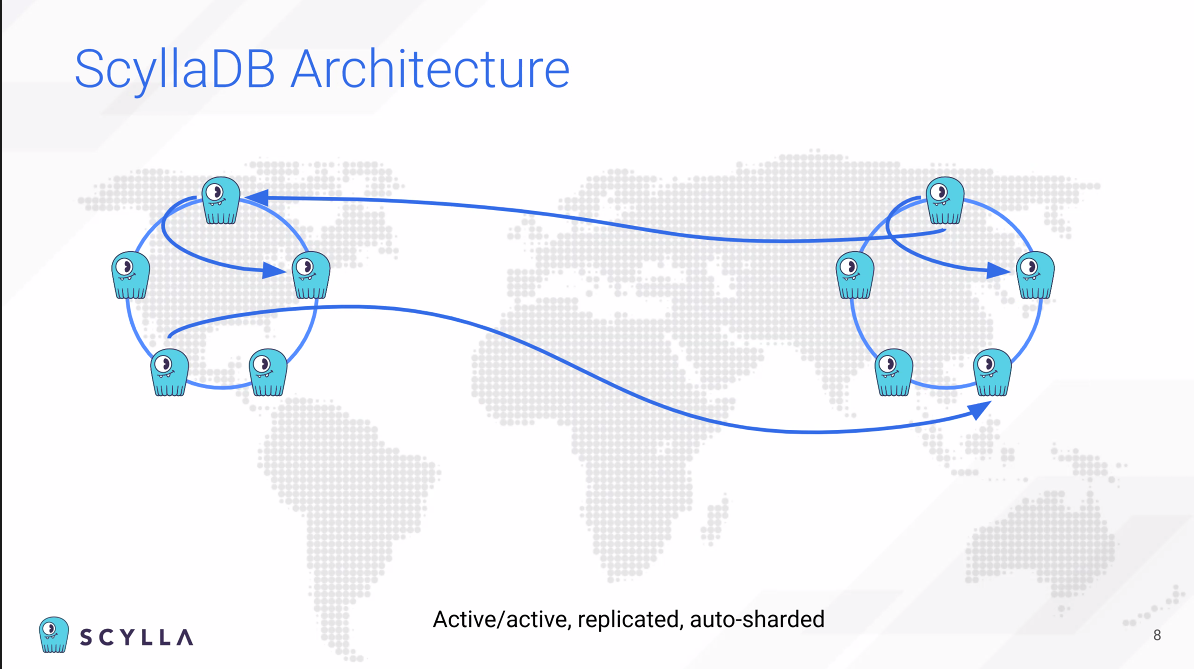
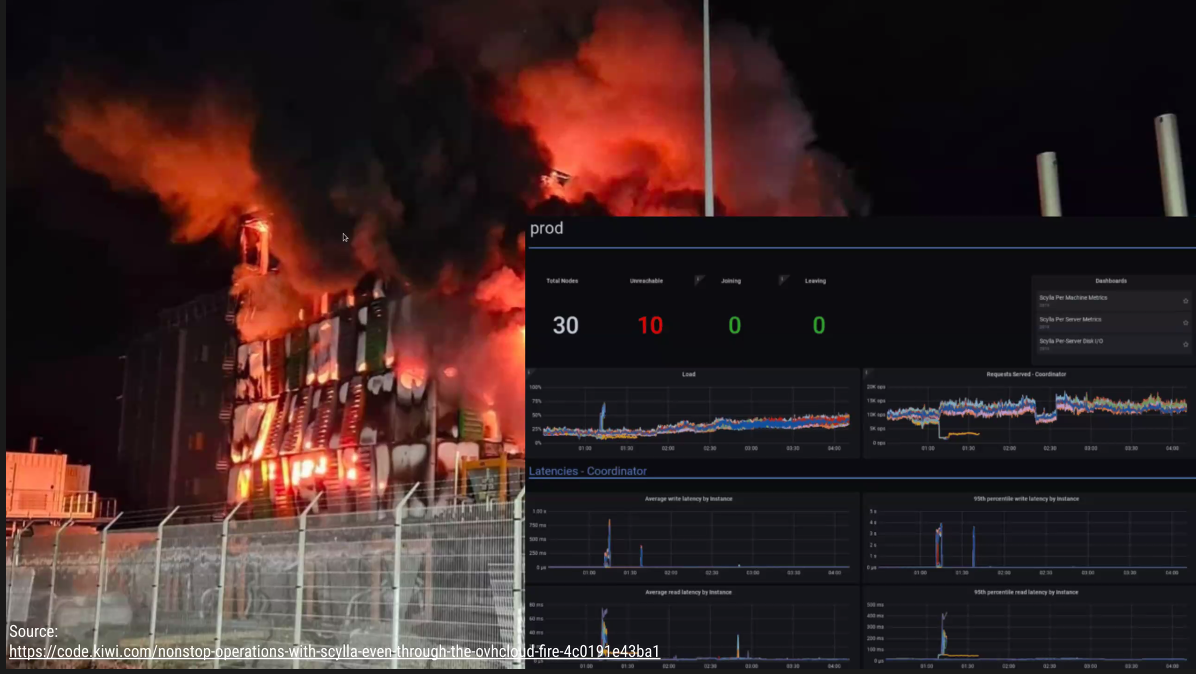
클러스터는 어떤 불타는 상황이든 계속 지속된다.

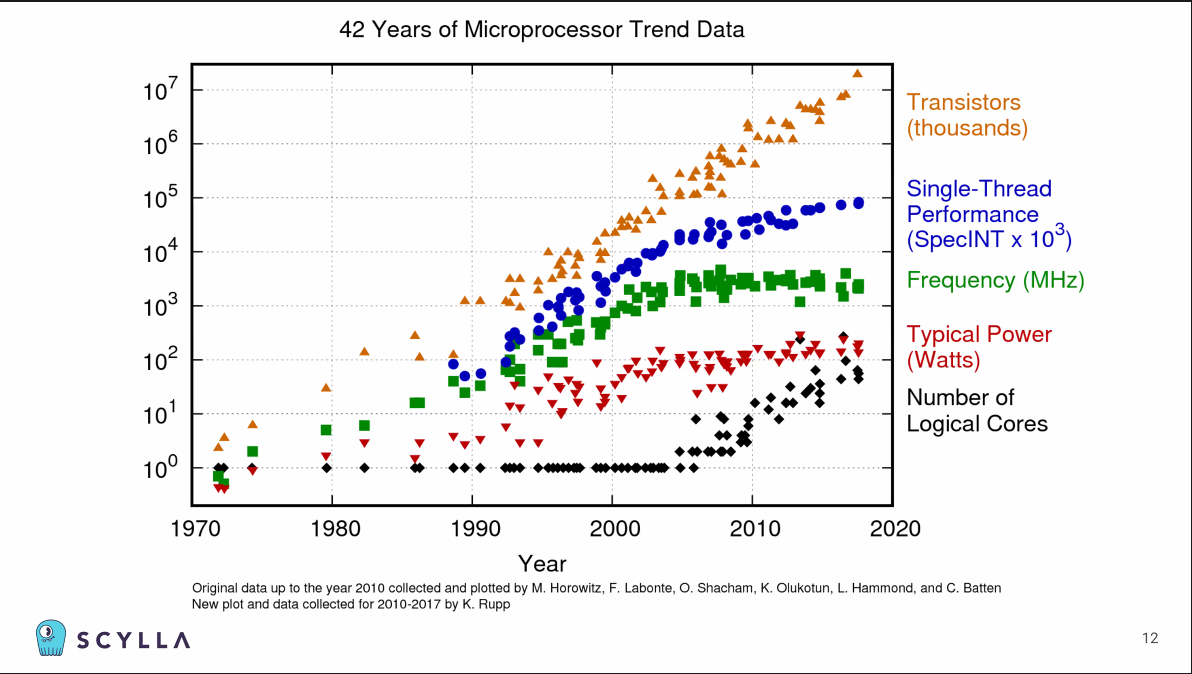
클라우드에서는 요새 코어가 90개가 넘는(96개) 등 계속 인프라가 커지고 있다.
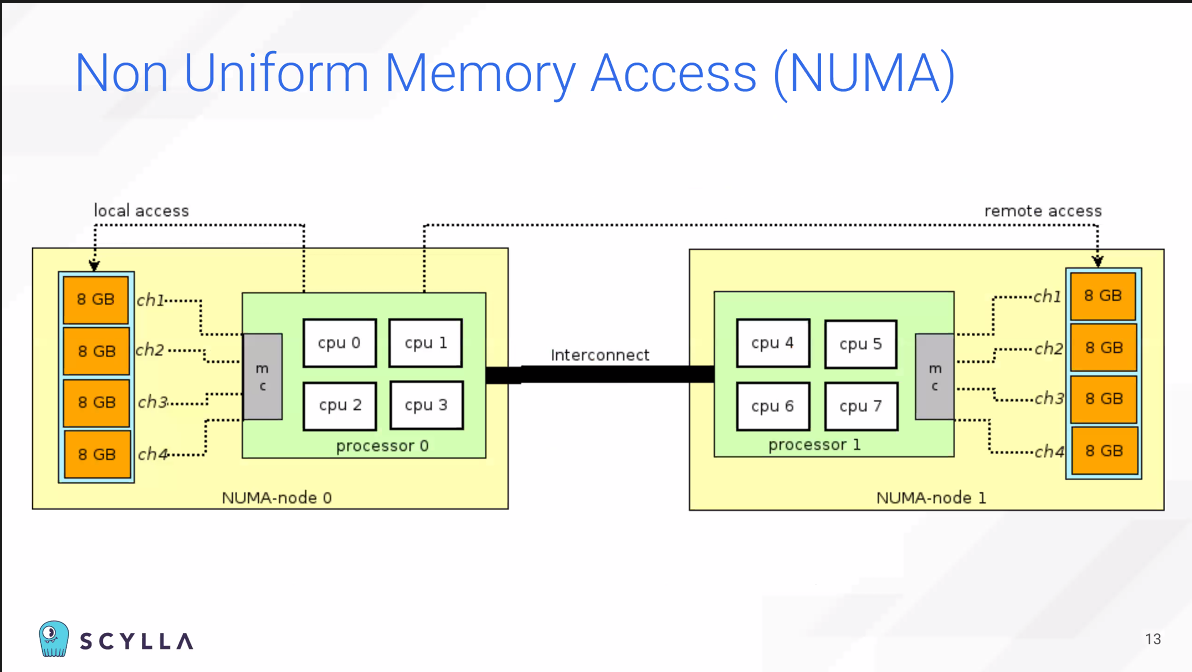

보다시피 테라바이트급으로 램이 늘었고, 계속 수치는 높아져왔다.
Cassandra는 distribution을 위해 개발이 되었지만, scale-per-core가 아니기 때문에 Scylla와 다르다.




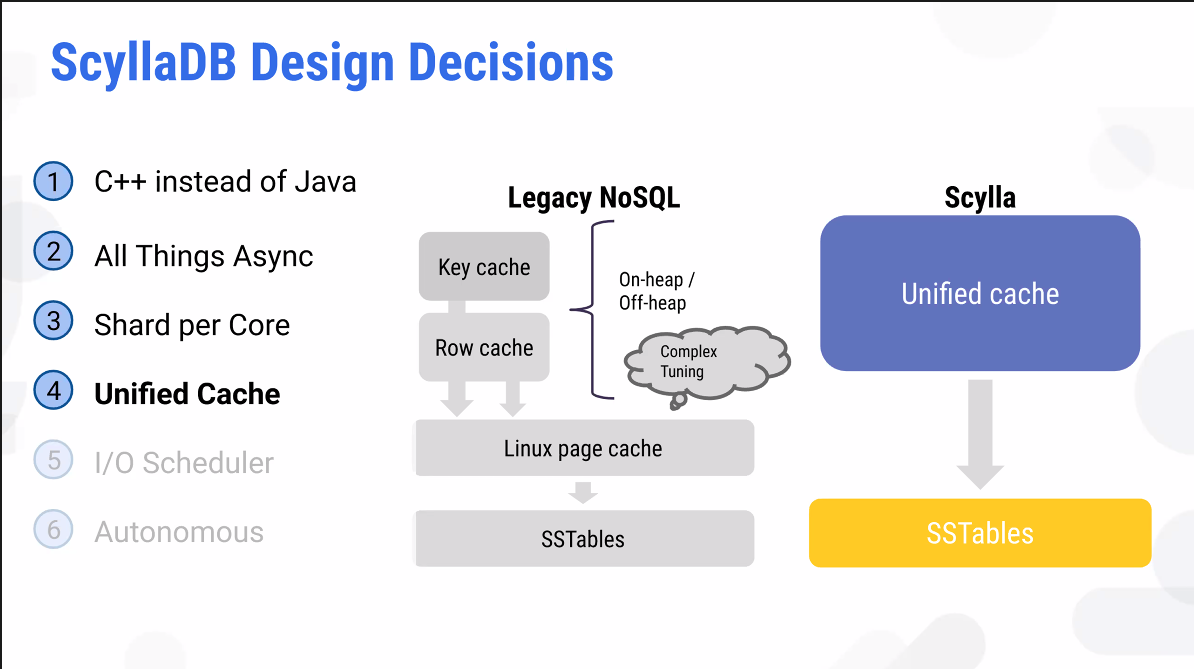
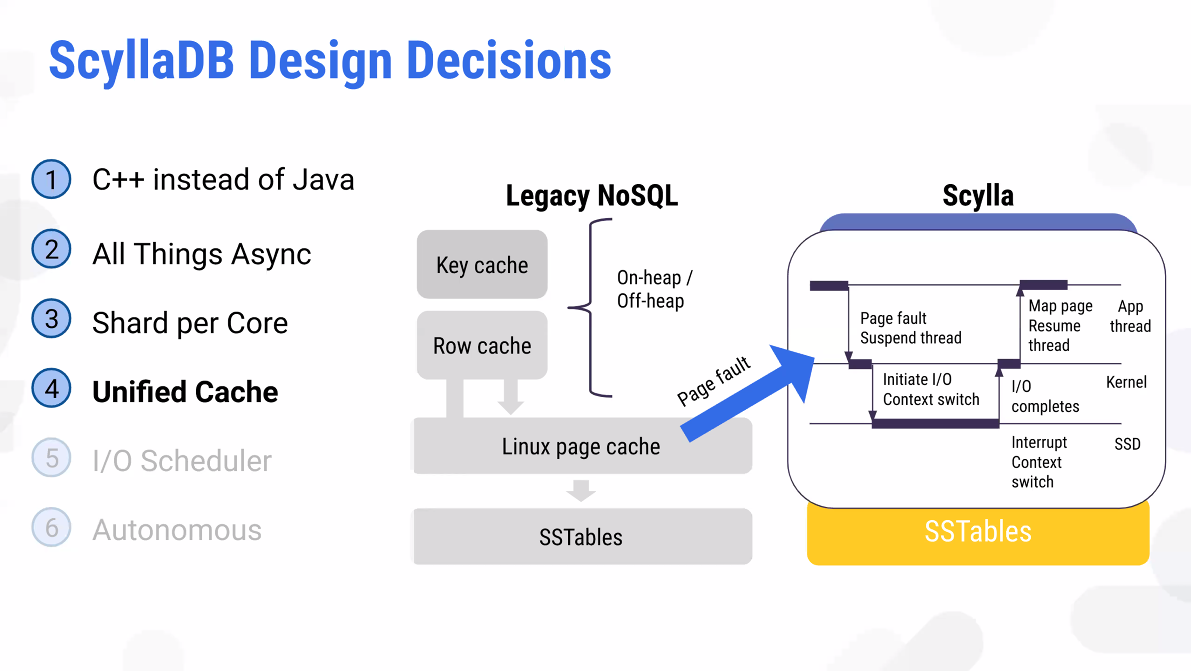
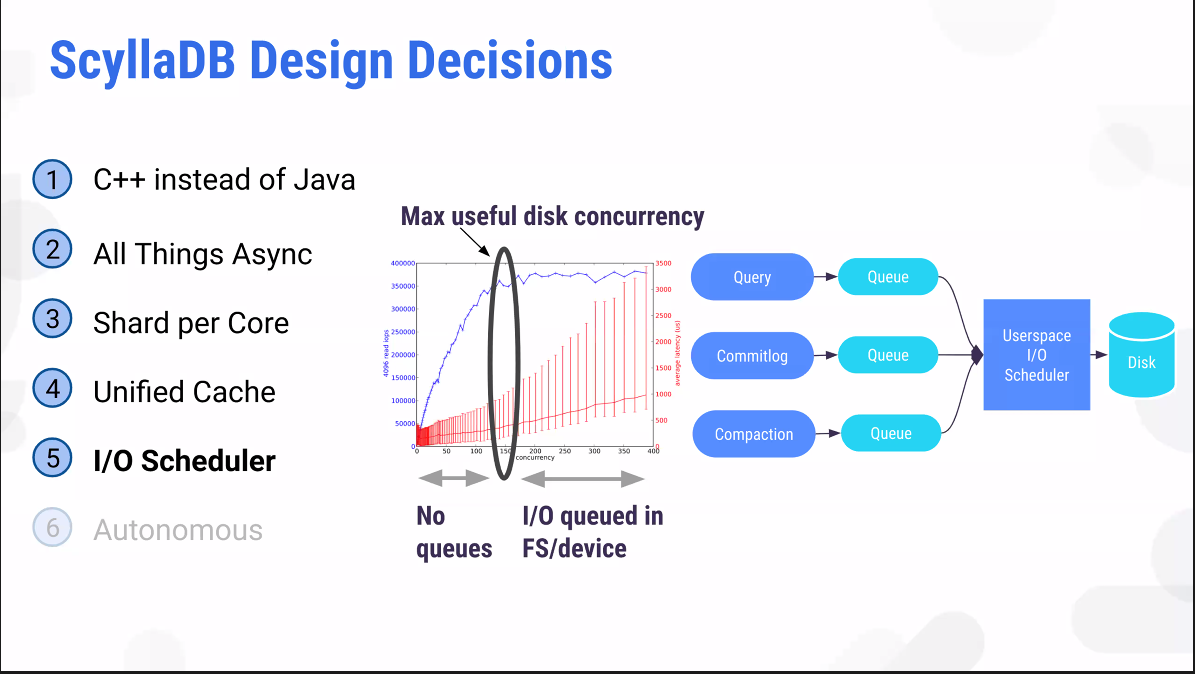
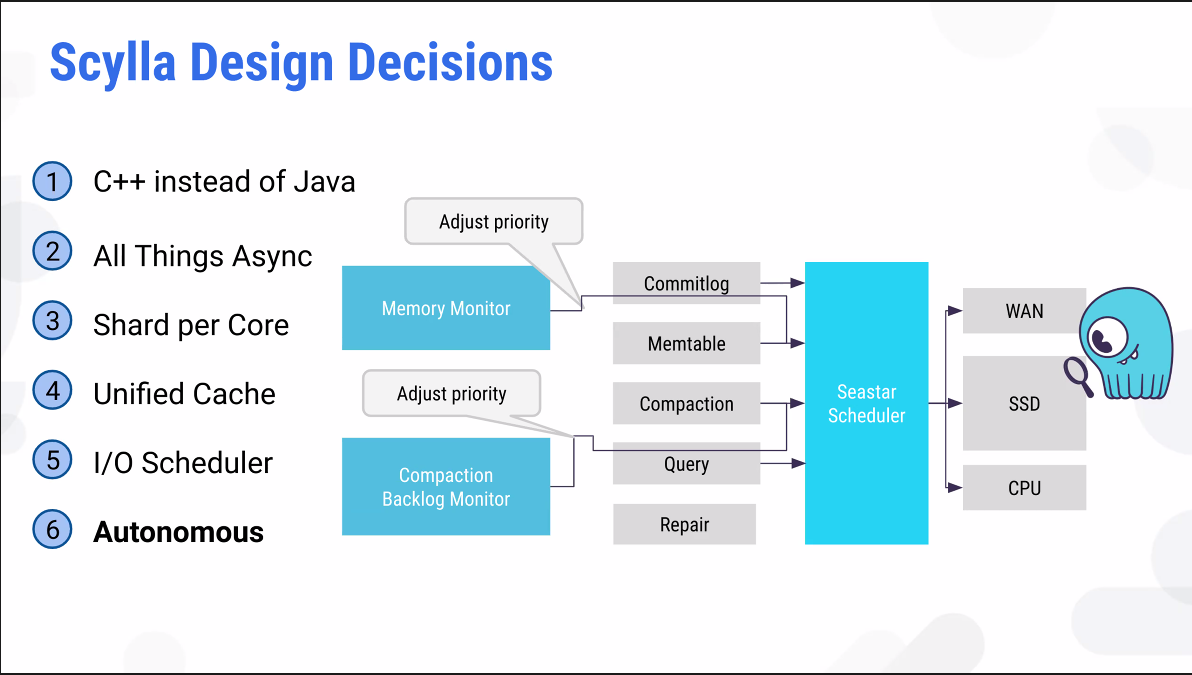

코어가 많을수록 멀티쓰레딩에 대한 효율성이 떨어진다. 1-thread-per-core로 한정한다면 context switch 없이해도 되고, block할 필요가 없다.
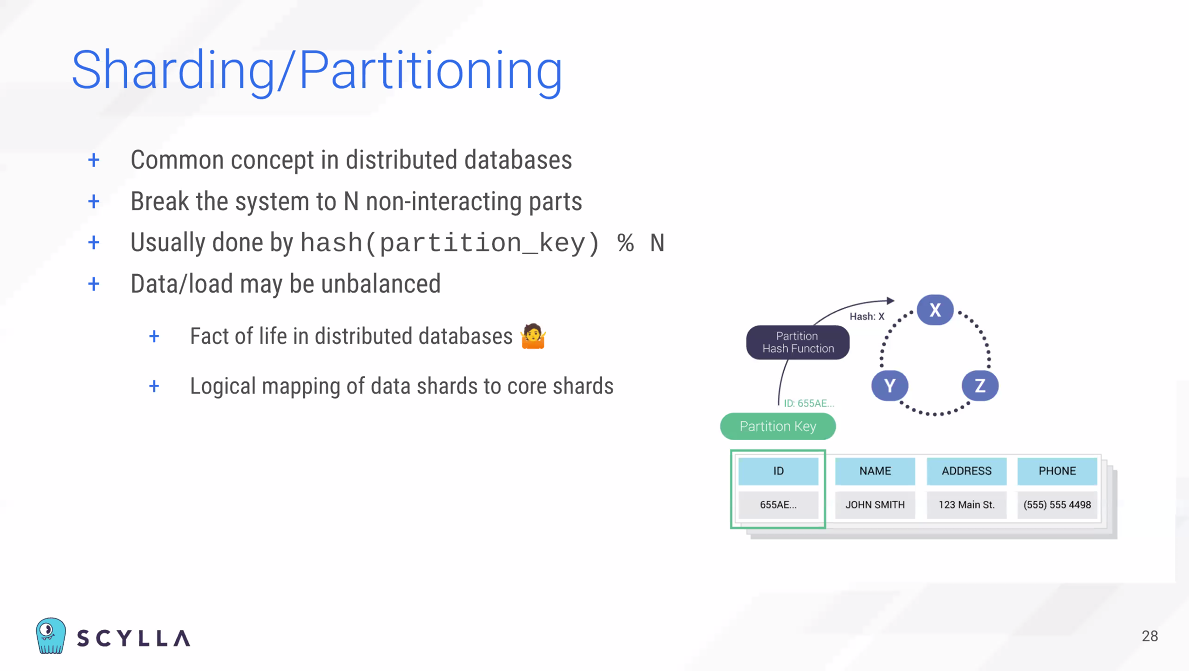
노드 베이스로 파티셔닝을 해서 Scylla는 특별하다고 볼 수 있다.
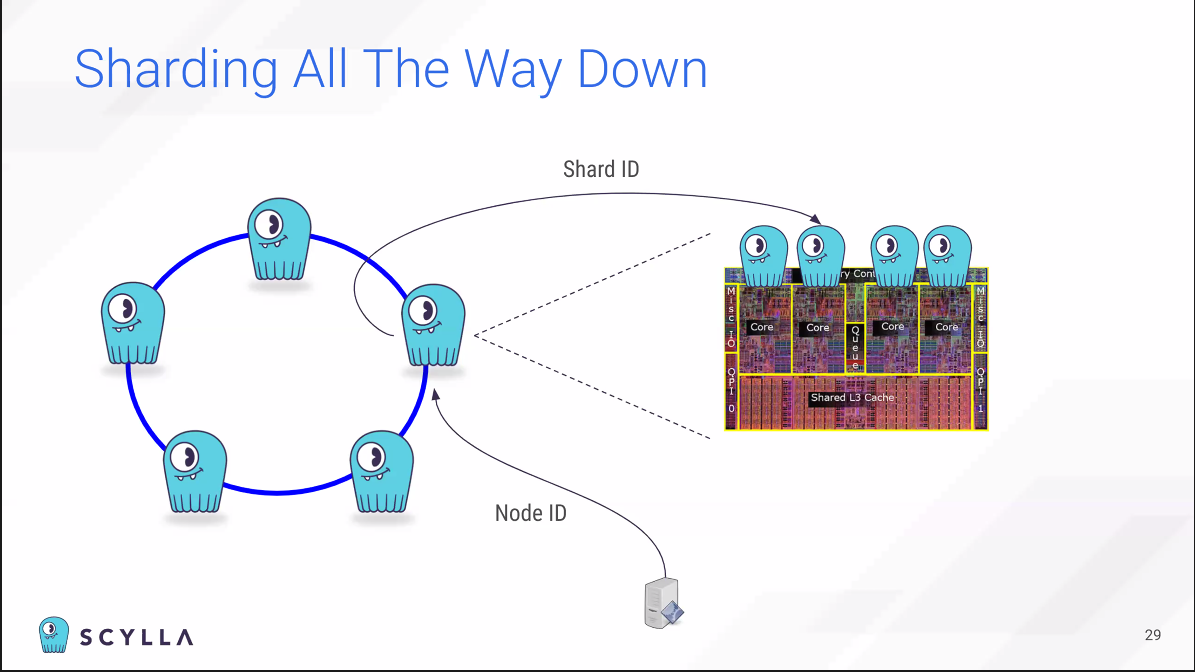
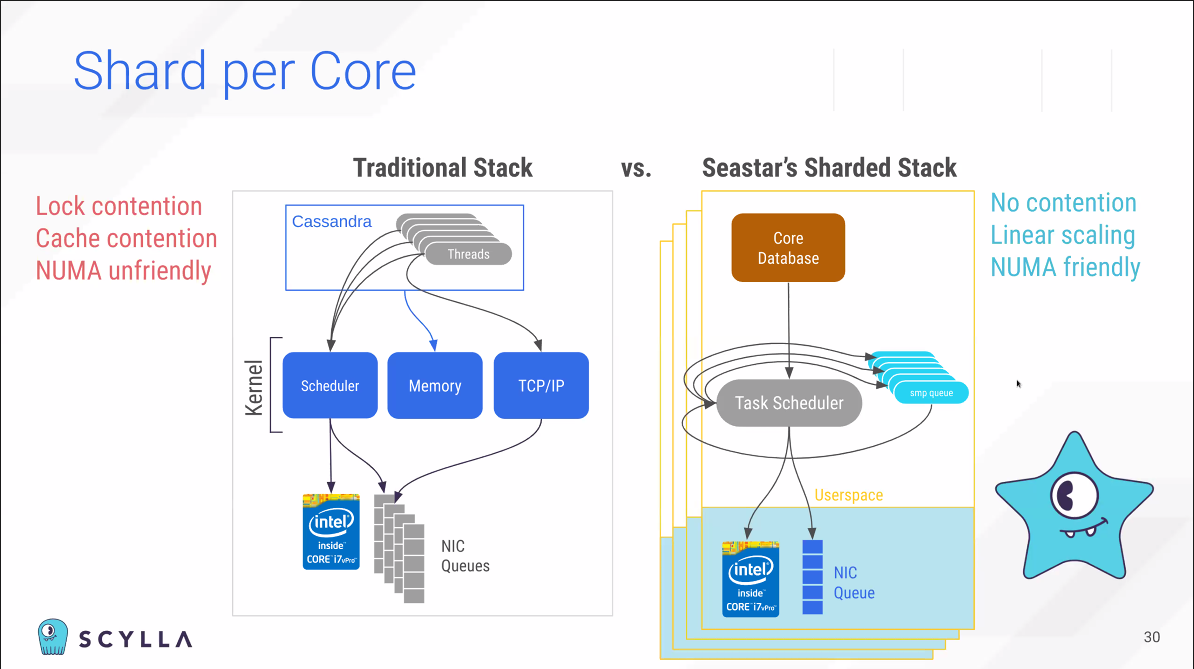
오픈소스 라이브러리 Seastar를 확인해보자.
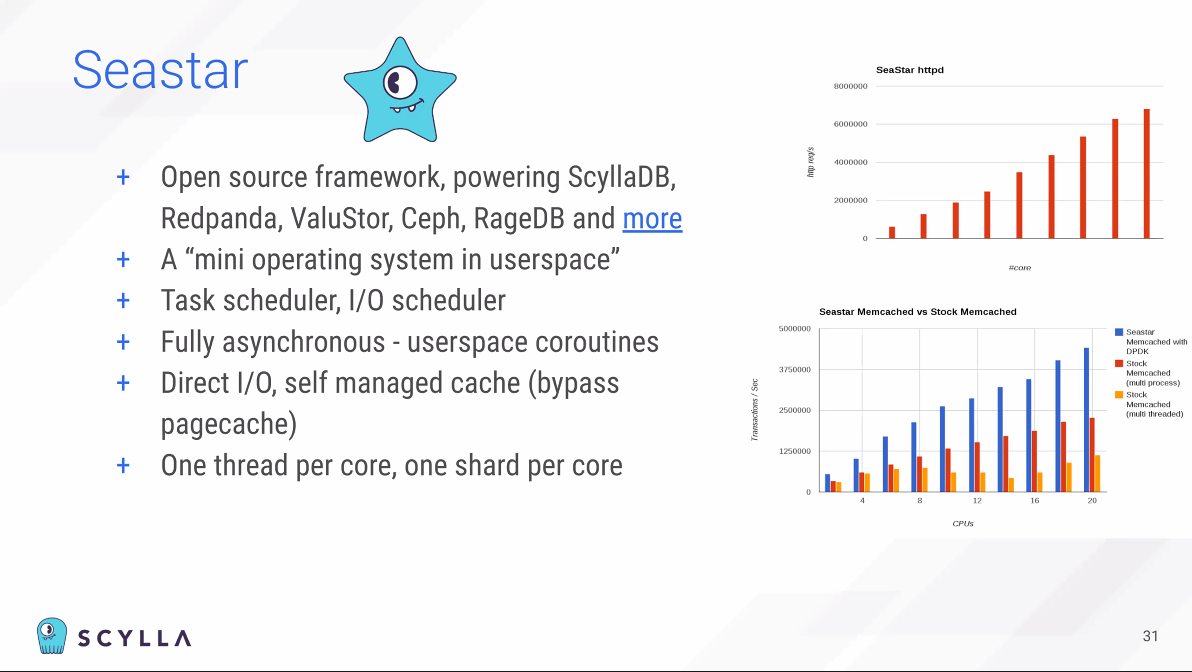
RageDB는 그래프DB이다. Core 별로 linear growth를 경험할 수 있다.

여태 코어는 독립적이라고 말했지만, 스케쥴링할 수 있다.

ScyllaDB에서는 대부분 read와 write를 수행하지만, admin 작업을 할 때도 간혹 있다.
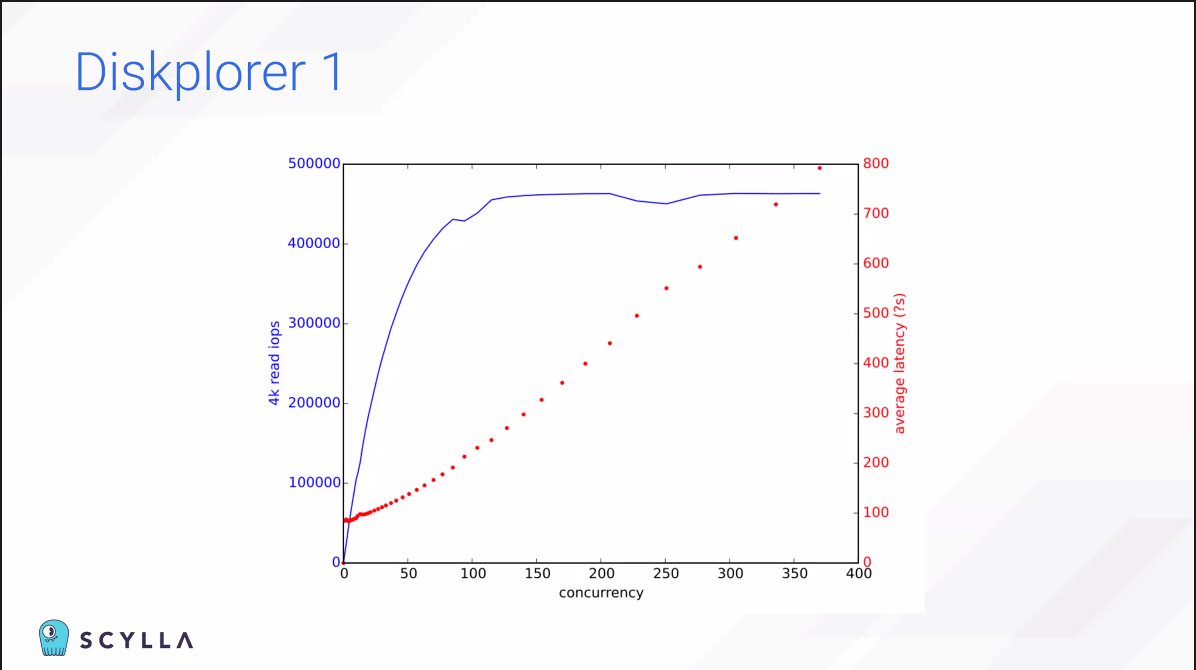
- Throughput 문제가 있다.
- Not longer prioritize the request 문제가 있다.
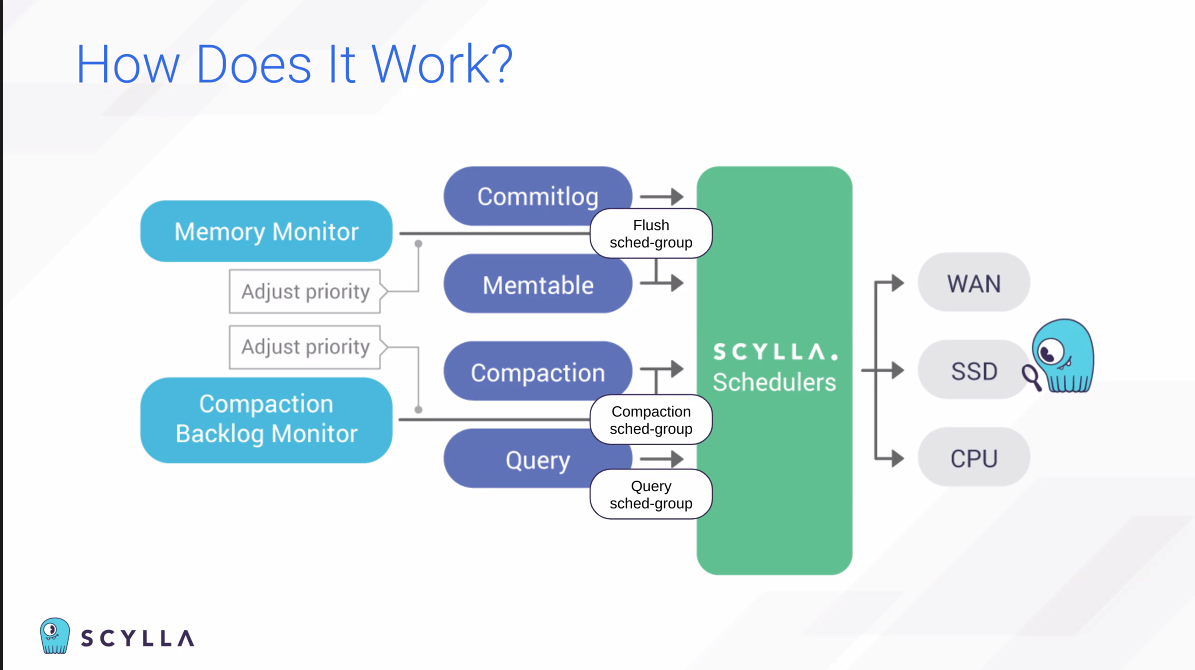
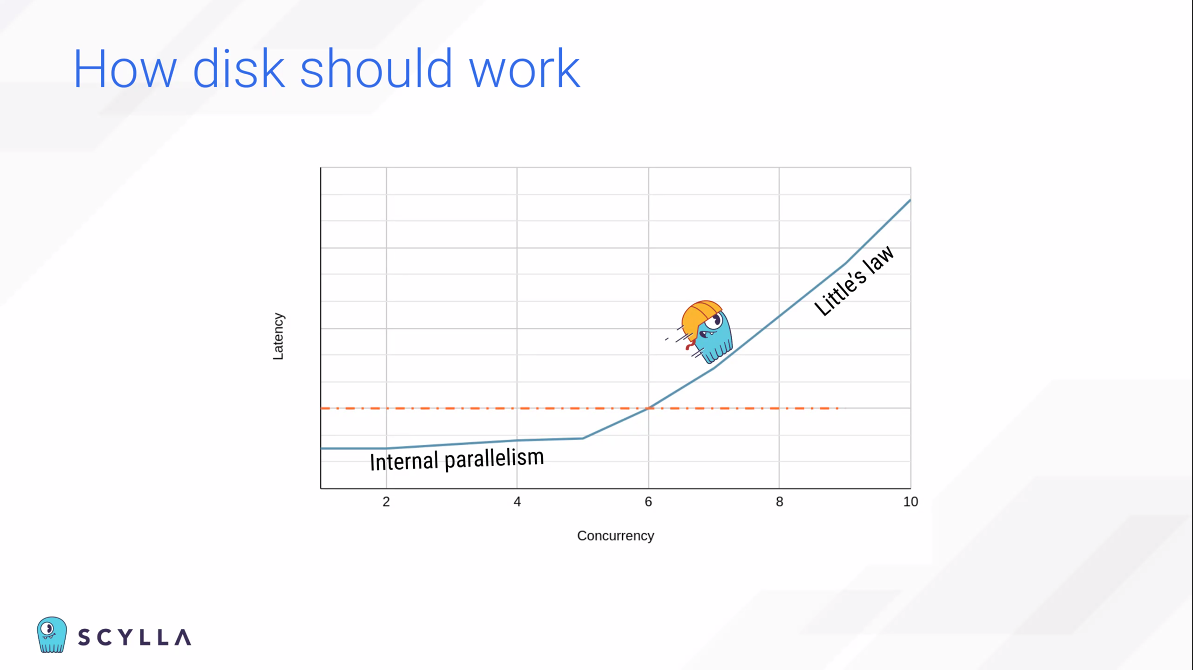
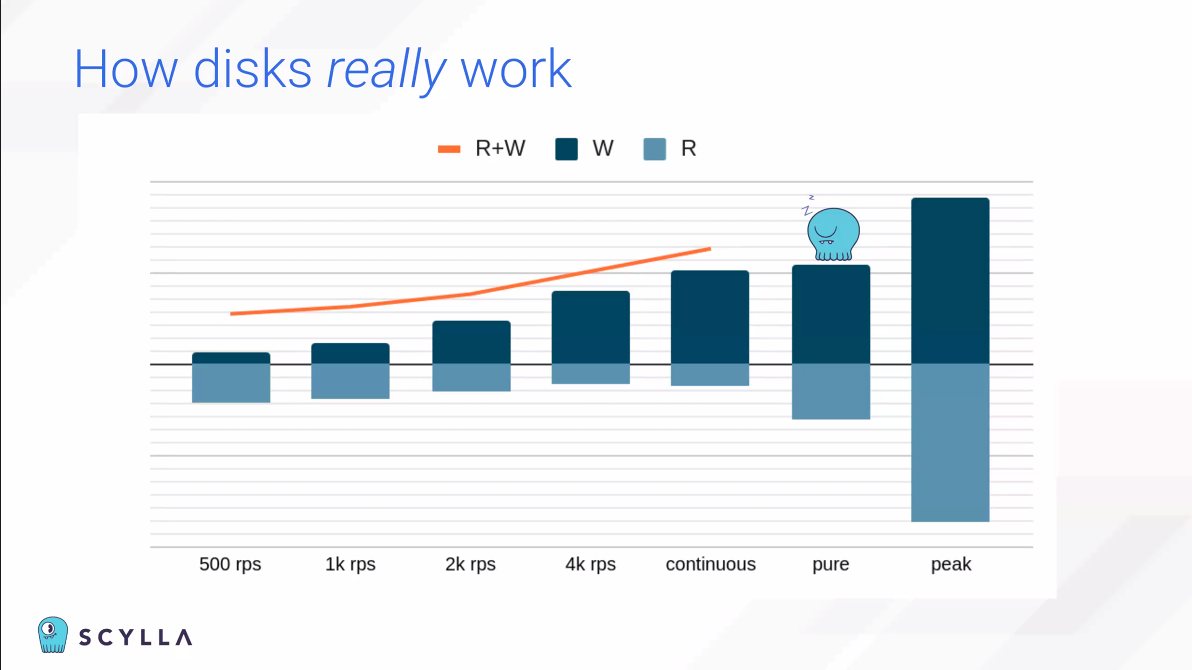
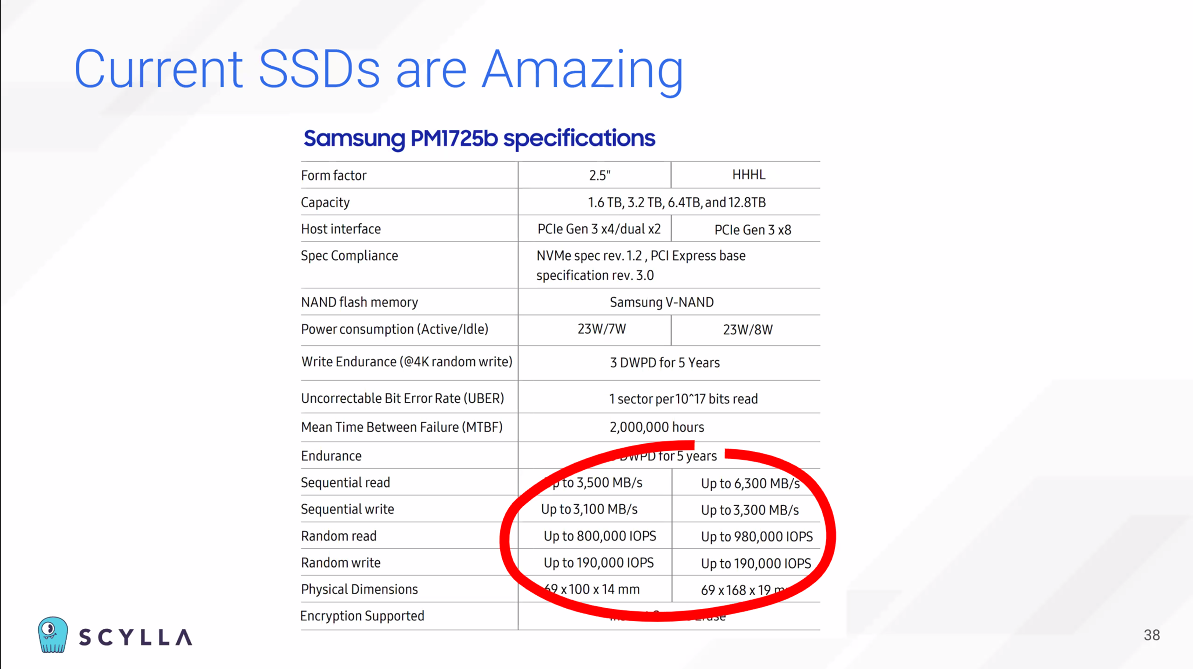

SSD 태스크를 하나씩만 순차적으로 수행할 수 있다.

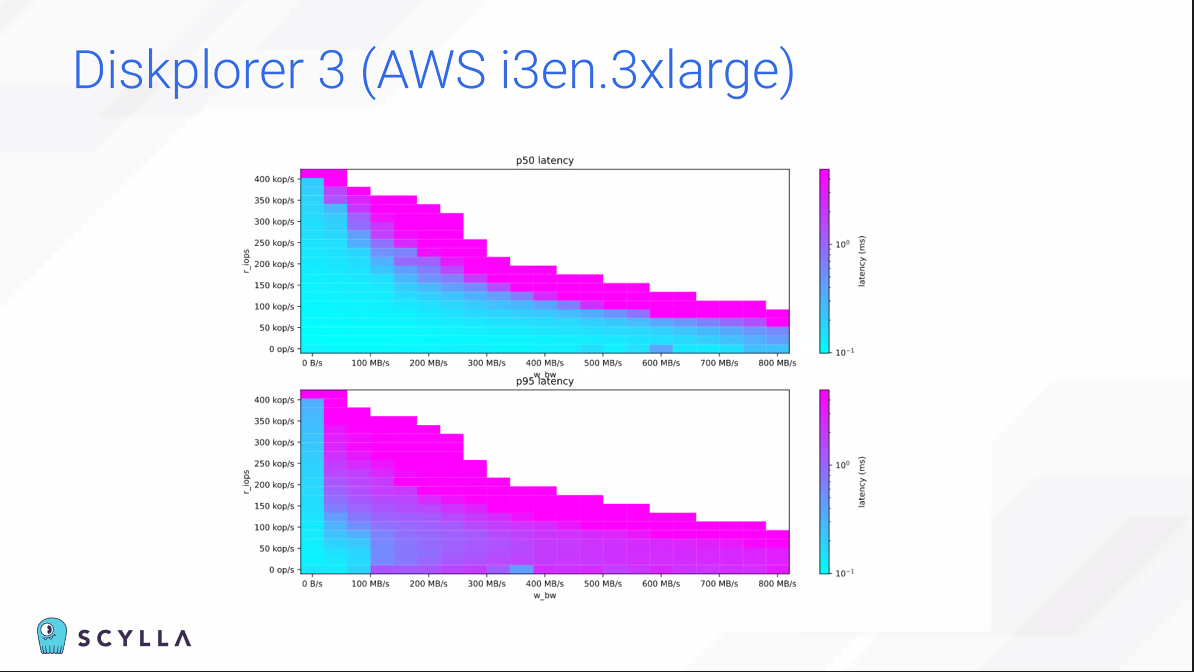
많은 data point를 분석해서 Diskplorer3은 Diskplorer1보다 더 현실적인 storgage를 그릴 수 있다.
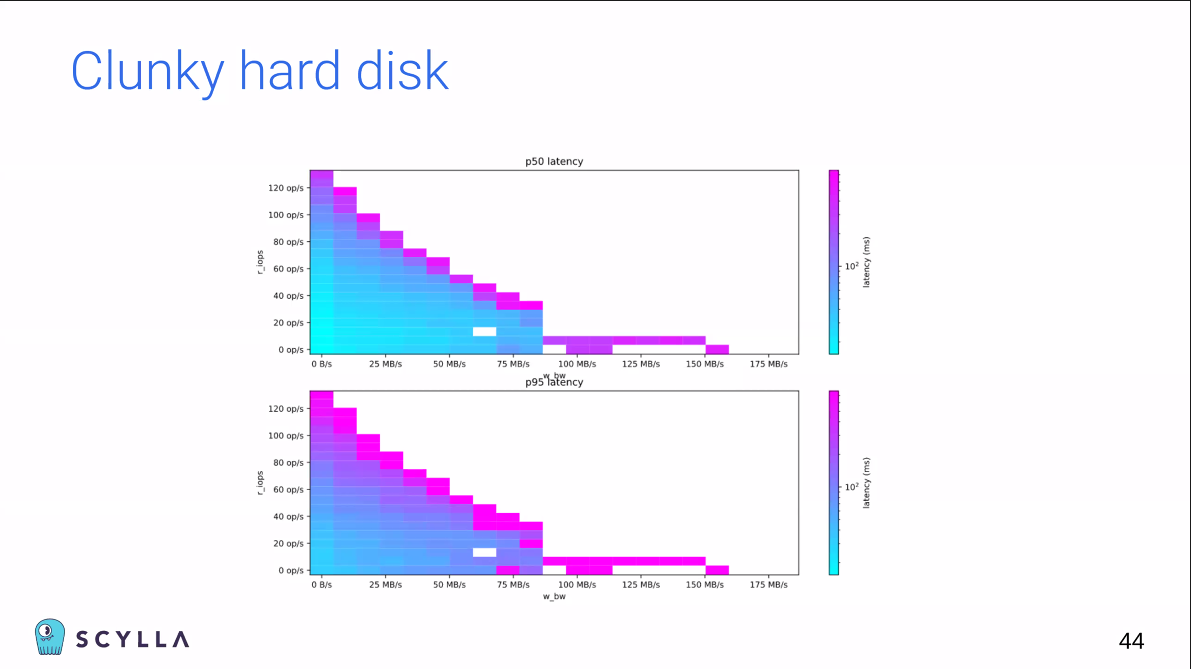
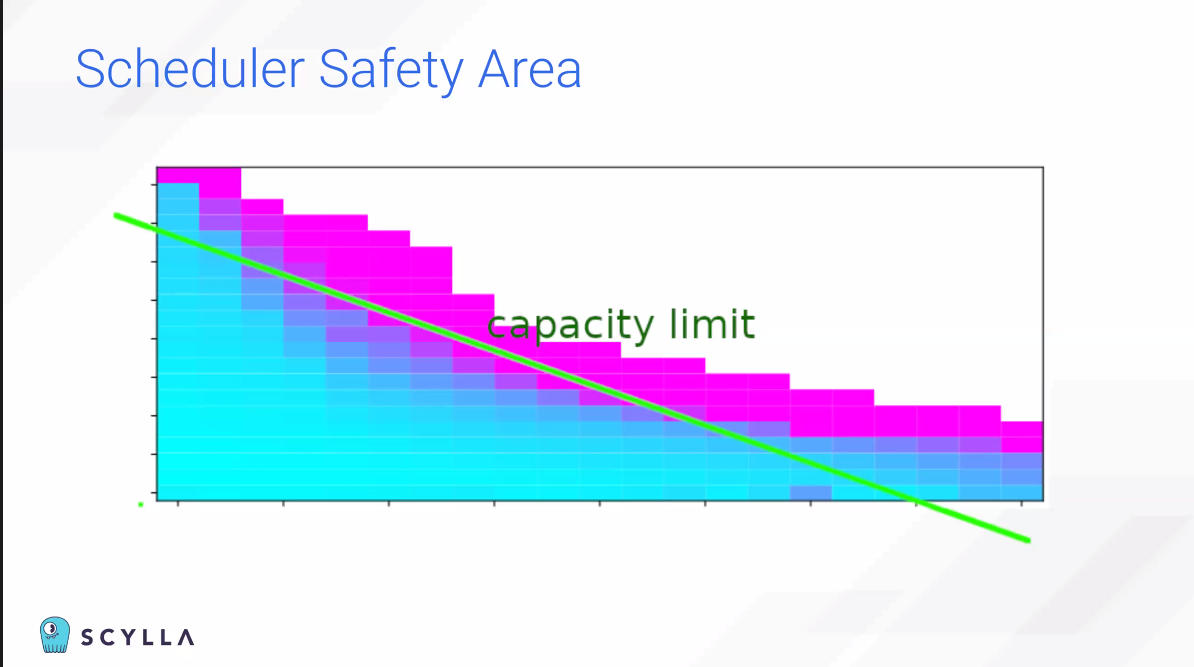
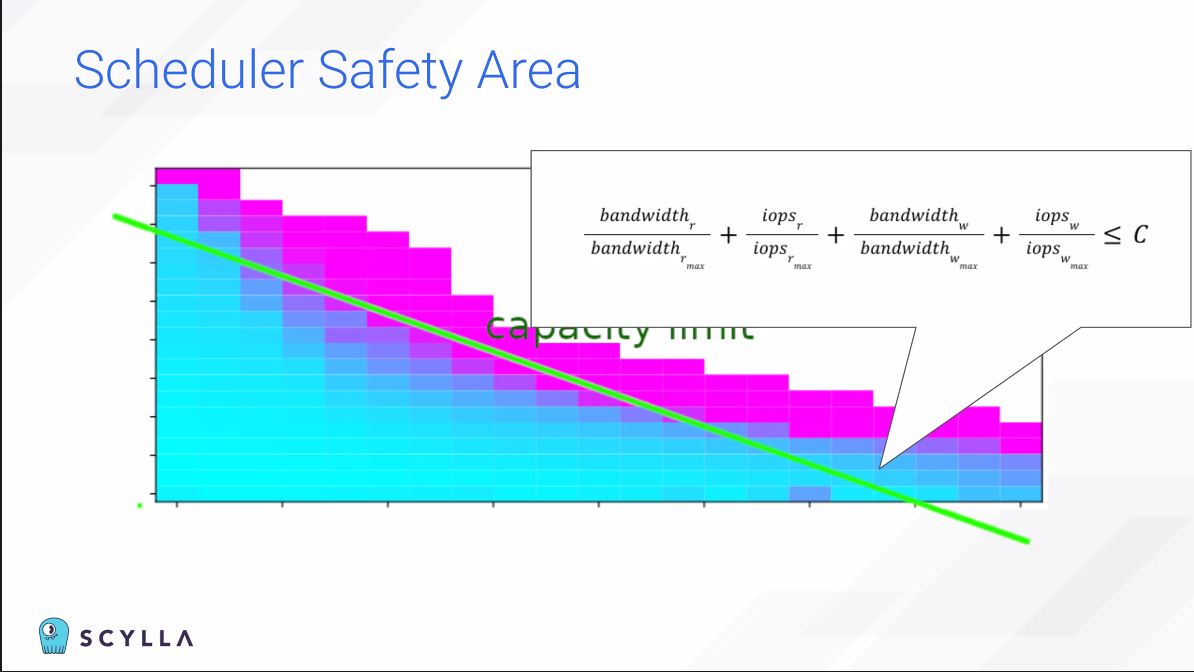

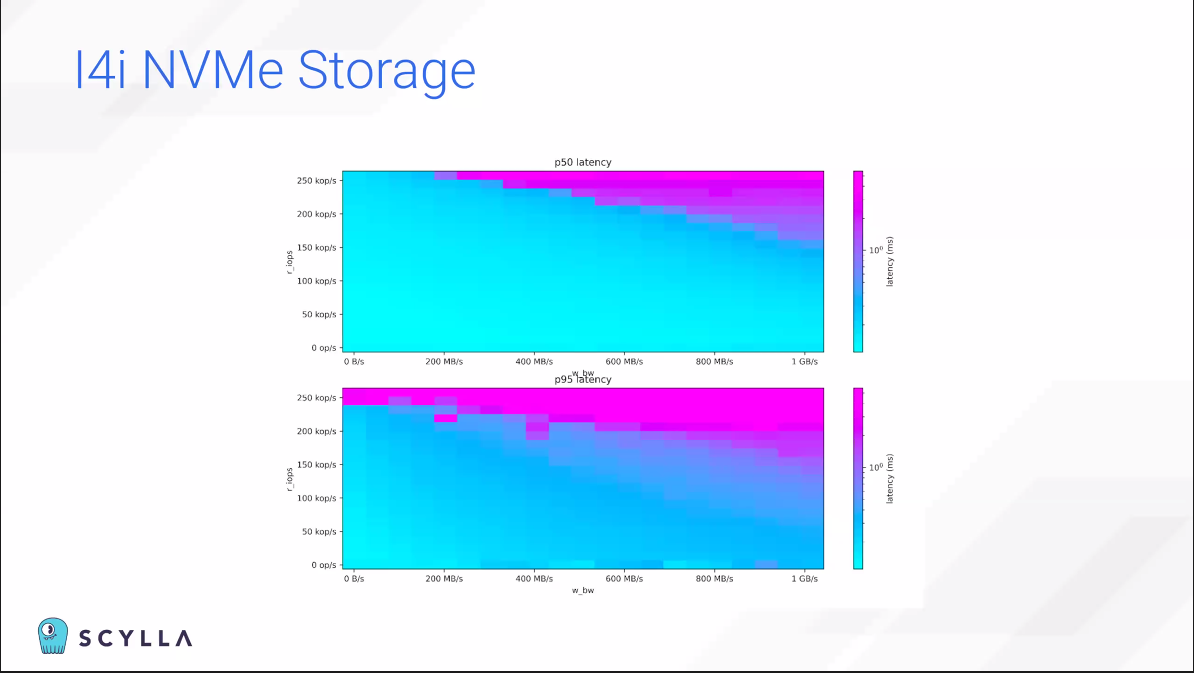
AWS는 이 인스턴스를 특별히 Scylla가 쓸 수 있게끔 배려해줬다.
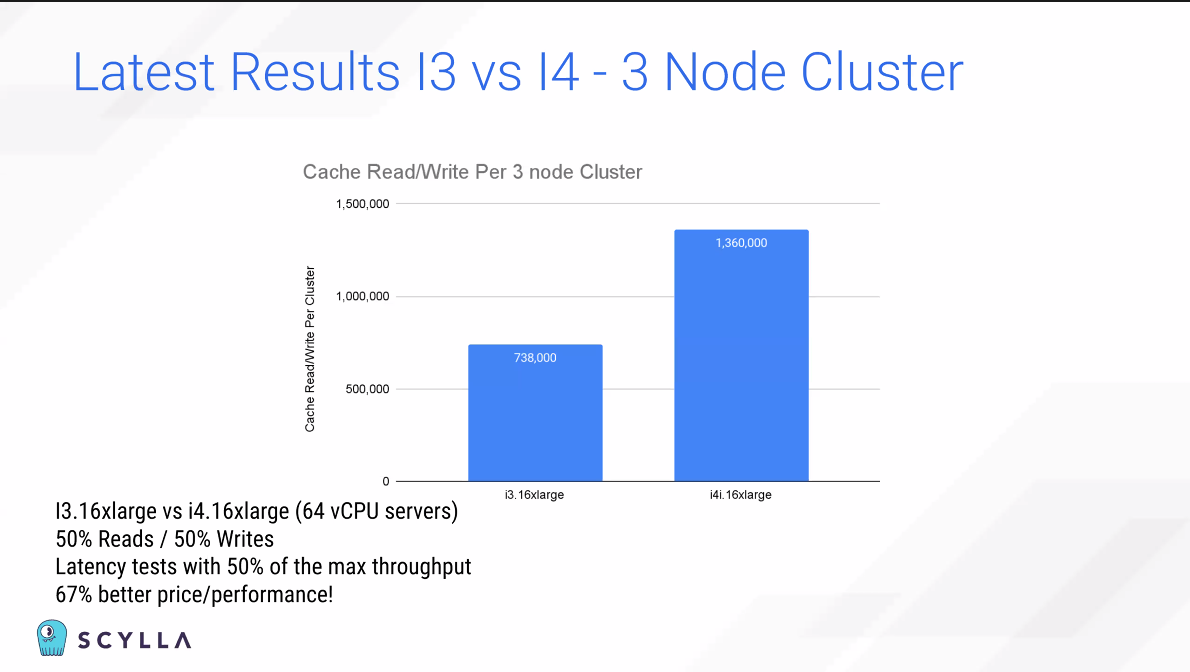


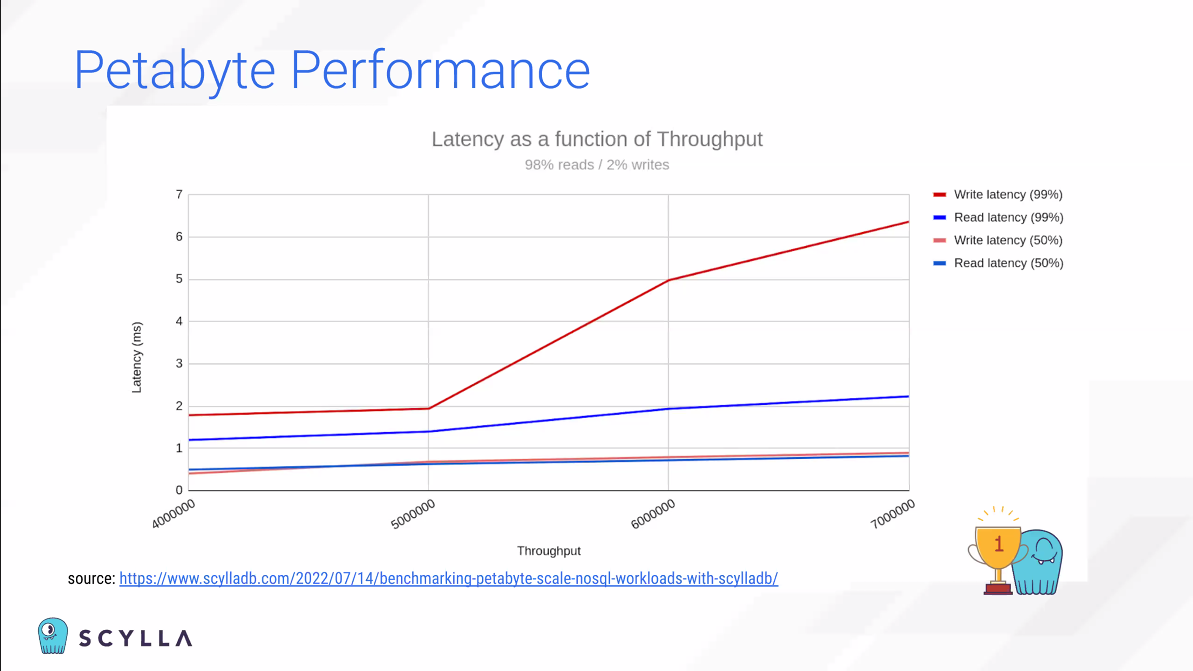
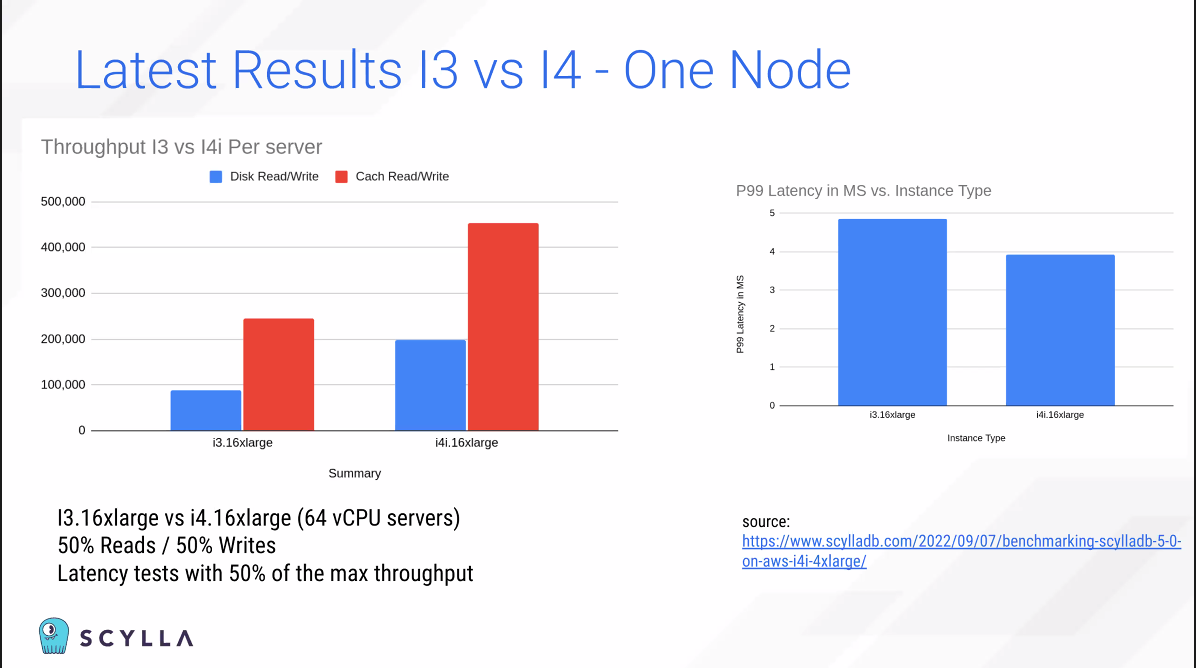
Low latency가 인상깊다.


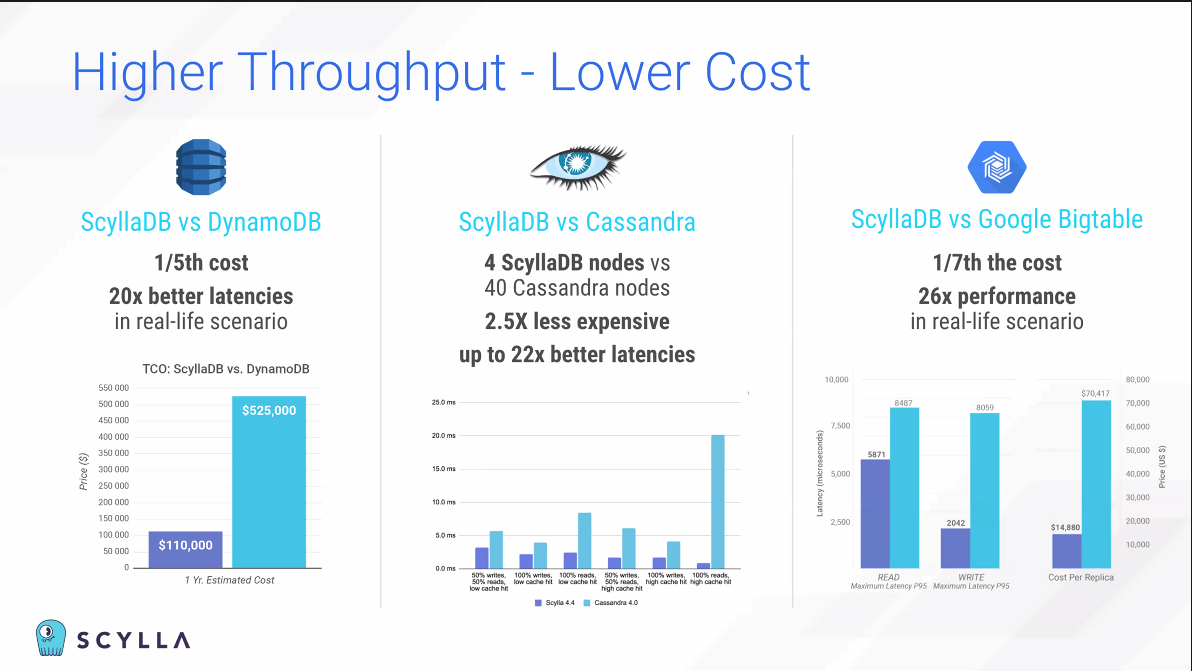
Latency는 단순히 돈으로 해결할 수 없는 일이기에 Scylla가 이 부문에 우수하다 볼 수 있다.
결론
클라우드에서 코어가 96개 등으로 많아지면서 shard-per-core 아키텍쳐를 쓰는 ScyllaDB가 기존의 multi-threaded DB보다 더 효율적일 수 있다.
