
대부분의 개발 분야에서 자료구조는 매우 중요한 역할을 한다. 어떤 자료구조를 사용하냐에 따라 시스템의 시간, 공간 복잡도가 매우 큰 영향을 받을 수 있기 때문에 만들고자 하는 시스템의 목적과 조건에 따라 알맞은 자료구조를 선택하는 것이 중요하다.
이번 포스팅에선 그 중 set/map 그리고 unordered_set/map을 비교해 볼 것이다.
이것을 보기 쉽게 그림으로 표현하면 관계가 명확하게 보인다.
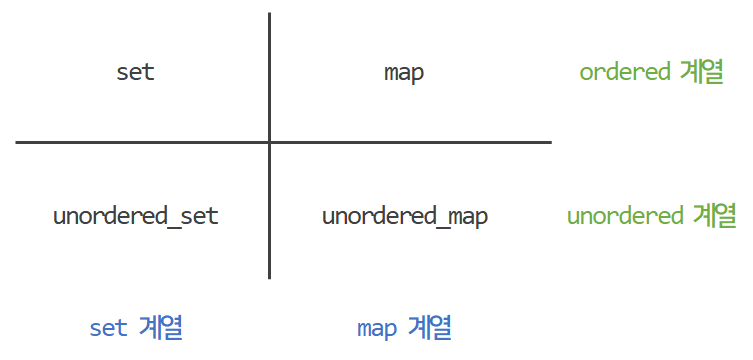
위와 같이 분류할 수 있는데, 각각에 대해 알아보자.
· set? map?
- set 계열 : 단일 저장 공간에 하나의 데이터만 저장하는 자료구조.
- map 계열 : 단일 저장 공간에 <key, value>의 데이터 쌍을 저장하는 자료구조.
약간의 설명을 보충하자면, set은 우리가 일반적으로 많이 사용하는 배열이나 리스트, 벡터 등과 같이 한 가지 타입의 변수를 여러개 관리하기 위한 자료구조이다.
반면에 map은 최대 두 가지 타입의 변수를 쌍을 지어 함께 관리하는 자료구조이다. 예를 들어 학생의 정보를 관리하는 자료구조가 필요하다고 하자. 대학의 학생들은 모두 고유의 학번을 가지고 있다. 이러한 학번을
{ 12000000, 12111111, 12222222, ... }
와 같이 저장할 수 있겠지만, 이러한 고유 번호는 형태가 비슷해 한눈에 특정인을 구분해내기 어렵다. 이럴 때 이름과 함께
{ {12000000, "홍길동"}, {12111111, "고길동"} }
이와 같은 형태로 저장한다면 이름으로 특정인을 구분하고 학번으로 재차 본인임을 확인하는 것이 더 효율적일 수 있다. 이때 각 데이터가 가지는 고유한 값을 key라고 하며 데이터셋의 앞에 위치하고, key가 가져야 하는 추가적인 데이터를 value라 하여 데이터셋의 뒤에 위치시킨다. 위 예시에서는 12000000이 key, 홍길동이 value가 된다.
set은 데이터 그 자체가 key가 된다고 생각해도 무방하다.
· ordered? unordered?
이름에서 확실하게 알 수 있는 것은 ordered 계열은 자료구조 안에 순서가(정렬이 되어) 있고, unordered 계열은 그렇지 않다는 것이다. 이러한 차이는 각 자료구조가 어떠한 형태에서 파생되었는지의 차이이다.
우선 ordered는 대부분 Red-black tree 형태를 가지고 있다. 레드블랙 트리는 데이터를 삽입 및 삭제할 때 자동으로 정렬되기 때문에 ordered의 특성이 생긴다. 또한 레드블랙 트리의 다음과 같은 특성도 함께 가지고 있다.
- 삽입, 삭제, 탐색은 의 시간복잡도를 가진다.
- 커스텀 구조체를 원소로 사용한다면 원소의 대소를 어떻게 구분할지에 대한 내용으로 < 연산자를 오버라이딩하여 사용해야 한다.
struct Student {
int student_id;
int grade;
bool operator < (const Student& other) const {
if(grade == other.grade){
return student_id < other.student_id;
}
return grade < other.grade;
}
};반대로 unordered는 Hash를 활용한다. 이러한 자료구조의 저장 순서는 해시 함수의 출력으로 어떠한 값이 나오는지에 따라 인덱스가 결정되므로 컨테이너 내의 모든 데이터를 출력할 때 삽입한 순서대로 출력되지 않는다. 또한 해쉬의 다음과 같은 특성도 함께 가지고 있다.
- 컨테이너의 자료가 늘어남에 따라 주기적으로 의 시간복잡도를 가지는 Rehashing 작업이 이루어진다.
- 커스텀 구조체를 key로 사용한다면 해시 충돌이 일어났을 때 해당 버킷에 있는 다른 원소들과 같은 key인지 비교하는 == 연산자를 오버라이딩하여 사용해야 한다. 기본적으로 set/map은 데이터 중복을 허용하지 않기 때문이다.
struct Student {
int student_id;
int dept_name;
bool operator == (const Student& other) const {
if(student_id == other.student_id && dept_name == other.dept_name){
return true;
}
return false;
}
};위에서 배운 네 가지 자료구조는 기본적으로 중복을 허용하지 않는다. 이들이 중복을 허용하도록 해주고 싶다면 이름 앞에 multi를 붙여주면 된다.
