· Lock
요즘 대부분의 프로세서가 멀티코어를 지원하면서, 상용 프로그램들은 멀티쓰레드를 기본적으로 활용하게 되었다. 이때 발생하는 문제는 동기화가 매우 중요해진다는 것이다. 멀티쓰레드는 이론적으로 보았을 때 매우 놀라운 기술이지만, 잘 다뤄야 강력한 기술이다. 멀티쓰레드 프로그래밍을 하면 오히려 원인을 알 수 없는 Fatal, 예상치 못한 결과, 심지어 더 느린 성능을 더 자주 마주하게 된다. 멀티쓰레드 프로그래밍에서 중요한 사항은 다섯 가지가 있다.
- Data race가 발생하지 않게 조치한다. 즉, Lock을 사용한다.
- Lock을 사용하면 오히려 싱글쓰레드 버전보다 느리다. 즉, Lock을 사용하면 안 된다.
- Lock을 없애면 컴파일러가 읽으라고 한 값을 읽지 않고 무시한다. Volatile, Atomic 키워드 등을 활용한다.
- 컴파일러, CPU가 컴파일 과정에서 최적화를 한답시고 코드의 순서를 바꿔 결과가 엉터리로 나온다. Volatile을 활용한다.
- Int 변수에 -1을 썼는데, 65535와 같은 값이 써진다. 캐시에 저장된 포인터 주소를 읽을 때 메모리버스가 캐시 라인에 걸쳐 있다면 반을 일고 나머지 반을 읽는 두 단계로 나뉜다. 이 사이에 다른 쓰레드가 끼어들어 업데이트하는 등에 의해 손상될 수 있는데, 포인터 연산에서 이를 주의해야 한다.
앞서 말한 것처럼 Lock이라는 개념은 필요하지만, 이는 프로그램에 좋은 영향을 주지 않는다. 이를 위한 것이 Lock-free 알고리즘이고, 멀티쓰레드 환경에서 쓰레드 간의 자료구조, 쓰레드 데이터 교환 등은 모두 Lock-free 자료구조에서 수행된다.
· Lock-free
Lock-free란, '여러 개의 쓰레드에서 동시에 호출했을 때에도 정해진 단위 시간마다 적어도 한 개의 호출이 완료되는 알고리즘'이라고 정의할 수 있다. 즉, 멀티쓰레드 환경에서 다른 쓰레드가 플래그를 세팅해 주고, Lock을 풀어 주는 등 다른 쓰레드가 끝나고 자기 순서가 오기를 기다리지 않는 Non-blocking이 보장되어야 Lock-free가 될 수 있다.
특정 작업을 동시에 여러 쓰레드가 호출했을 때 적어도 하나는 완료해서 반환해야 Lock-free 알고리즘인 것이다. 알고리즘 내에 Lock이 있으면 당연히 Lock-free가 아니고, Lock이 없다고 해도 무조건 Lock-free인 것은 아니다.
Lock-free 알고리즘을 활용하지 않으면 Lock이 걸릴 부분이 실행되는 동안 다른 쓰레드는 실행할 수 없어 사실상 싱글쓰레드와 다를 바가 없이 동작하며, Priority, Inversion, Convoying 등에 의해 렉이 걸리고 버퍼에 데이터가 쌓여 버퍼 오버플로 등을 유발한다.
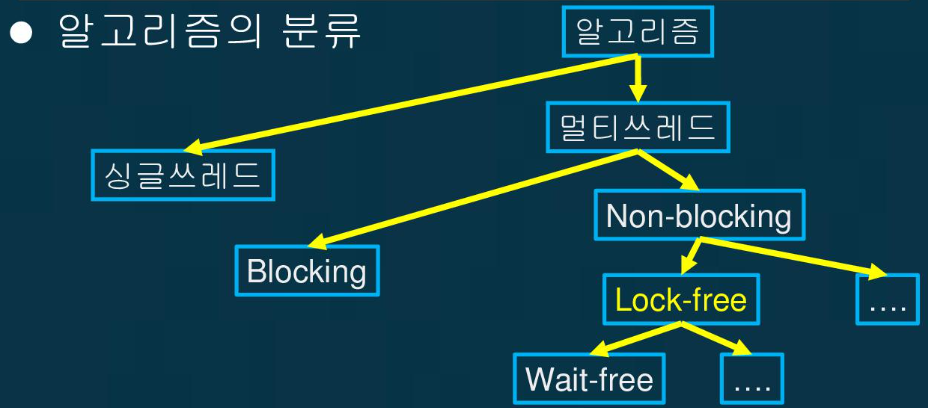
알고리즘은 위와 같이 분류할 수 있다. 이때 Lock을 사용하면 무조건 Blocking 알고리즘이고, Lock을 사용하지 않아도 Blocking, 그리고 일부 조건을 만족해야 Non-blocking으로 분류된다. 성능적으로 Non-blocking이 더 좋은 알고리즘인데, 이 안에서도 Lock-free보다 Wait-free 알고리즘이 더 좋은 알고리즘이다. Wait-free는 여러 쓰레드가 하나의 작업을 동시에 호출했을 때 지연 없이 모든 쓰레드가 동시에 작업을 완료할 수 있는 알고리즘을 말한다.
Lock-free 알고리즘을 구현하기 위해선 CAS가 반드시 필요하다. CAS 없이 Lock-free를 구현하는 것은 불가능하다. CAS가 의미하는 것은, 참조하고자 하는 메모리를 다른 쓰레드가 먼저 변경했다면 즉시 현재 작업을 포기하고 다른 작업 혹은 해당 작업을 다시 시도하게 하는 것이다.
알고리즘이란 데이터 구조 즉, 자료구조에 접근하는 방법이다. 그러한 알고리즘 동작은 자료구조를 읽고 변경하는 것이다. 즉, Lock-free 알고리즘은 자료구조를 변경하면서 다른 쓰레드와의 충돌을 확인하는 과정이 추가된 것이라고 설명할 수 있다. 다른 쓰레드와 충돌이 있다면 정상적으로 작동했을지 예기치 못한 동작을 했을지 알 수 없다. 따라서 변경 시도 전으로 돌아가는 것이 기본 동작이다. 하지만 되돌린다는 것은 사실 불가능한 작업이므로, 현재 자료구조를 기준으로 성공적으로 변경한 후의 모습을 설계하고, Atomic하게 자료구조를 변경한 뒤 결과를 비교하는 방식으로 같은 효과를 낼 수 있다. 따라서 CAS가 사용되는 것이다.
Lock-free의 장단점
- 장점
- 성능이 좋다.
- 높은 부하에도 안정적이다.
- 단점
- 생산성 : 알고리즘이 복잡해진다.
- 신뢰성 : 알고리즘의 정확성을 증명하는 것이 어렵다.
- 확장성 : 새로운 메서드를 추가하는 것이 어렵다.
- 메모리 : 메모리 재사용이 어렵다. ABA 문제가 발생한다.
- 장점
이러한 이유들로 Lock-free를 위한 믿을 수 있는 Non-blocking container를 사용해야 한다. 예시로 Intel TBB, VS PPL 등이 있고, 출처가 의심스러운 알고리즘은 정확성을 증명한 후 사용해야 한다. 정확성이 증명된 논문에 있는 알고리즘 등은 활용성이 높을 것이다.
· Lock-free로 MMORPG 서버 만들기
Lock-free로 MMORPG 서버를 구현할 때 다음과 같은 방식으로 성능 향상을 도모할 수 있다.
- 서버의 스펙
- 1000×1000 World
- 60×60 Sector
- 시야 30
- 1000마리의 NPC, 플레이어 접근 시 자동 이동 및 공격
- 이동/공격/채팅 가능
- Windows에서 IOCP로 구현
- 성능 향상 방법
- 시야 처리 시 검색 성능을 위해 월드를 Sector로 분할하여 주위 Sector만 검색. 병렬 검색을 위한
tbb::concurrent_hash_map(Lock-free hash map) 사용 - 몬스터 AI 처리를 모든 쓰레드에서 균등하게 나누어 처리하기 위해 Timer와 Event 시스템 사용. Timer queue 병렬 등록을 위해
tbb::concurrent_priority_queue(Lock-free priority queue) 사용 - 객체 ID의 재사용을 막고 메모리 재사용 위해 객체 ID와 객체 배열의 인덱스를 쌍으로 관리. 데이터 쌍의 병렬 검색을 위해
tbb::concurrent_hash_map사용
성능 측정을 위해 서버에 부하를 걸 수 있는 여러 명의 Player 소켓을 연결하는 Emulator 프로그램 DummyClient를 구현하여 테스트할 수 있다.
· Transactional memory
높은 난이도로 인해 생산성이 저하되는 Lock-free 대신 Transaction memory를 쓰면 대단히 간단하게 같은 기능을 구현할 수 있다. 이는 자료구조를 변경할 때 충돌이 발생하면 모든 수행 내용을 버리고 다시 시작하는 Lock-free 메커니즘을 그대로 구현한 것으로, Lock-free로 올바른 값이 나오고 성능도 좋다.
STM(Software Transaction Memory)와 HTM(Hardware Transaction Memory)로 나뉘는데, STM은 모든 Transaction 구간을 read/write에 등록해야 하는 불편함과 롤백에 대한 속도 저하가 크고, HTM은 지원하는 하드웨어를 마련해야 한다는 단점이 있고, 쓰레드가 너무 많을 때 충돌이 자주 일어나 롤백이 빈번해질수록 성능 향상을 보기 힘들다는 한계가 있었다.
하지만 인텔이 HTM이 내장된 Haswell 아키텍처를 개발하면서 접근성이 좋아져 서버 구현에 생산성이 높아지고 있다.
