멋쟁이사자처럼 AI스쿨
머신러닝 수업_1
머신러닝과 딥러닝에서 추상화된 도구 (Scikit-learn, TensorFlow, PyTorch, Transformer, FastAI 등) 를 사용했을 때의 장점과 단점
장점:
개발 시간 단축: 추상화된 도구는 다양한 라이브러리와 함수를 제공하여 개발시간을 단축한다.
단점:
이해하기가 어렵다. 수많은 알고리즘이 집대성되어 있기 때문에
지도학습과 비지도 학습의 차이
지도학습(Supervised learning)과 비지도학습(Unsupervised learning)은 기계학습의 두 가지 주요 분야이다.
지도학습
지도학습은 입력 데이터와 그에 상응하는 레이블(label)을 사용하여 모델을 학습시키는 것입니다. 즉, 입력 데이터와 그에 대한 출력 값을 알고 있는 상태에서 모델을 학습시키며, 모델은 레이블 값을 예측하는 것이 목표입니다. 예를 들어, 스팸 메일 필터링을 위한 분류 모델을 만든다고 가정하면, 이메일의 텍스트 데이터와 레이블(스팸 또는 스팸이 아님)을 사용하여 모델을 학습시킵니다. 그리고 모델은 새로운 이메일을 입력으로 받아 스팸 여부를 예측합니다.
비지도학습
비지도학습은 입력 데이터에 대한 레이블이 없는 상태에서 모델을 학습시키는 것입니다. 즉, 입력 데이터 간의 패턴이나 구조를 파악하여 데이터를 분류하거나 클러스터링하는 것이 목표입니다. 예를 들어, 고객들의 구매 이력을 분석하여 비슷한 소비 패턴을 가진 고객들을 클러스터링하는 경우, 레이블(즉, 구매 패턴이 유사한 그룹의 이름)을 미리 알지 못합니다. 이 경우 모델은 입력 데이터 간의 유사성을 파악하여 그룹을 만들어 냅니다.
=> 정리: 지도학습은 입력 데이터와 레이블을 함께 학습하여 모델을 만드는 것이며, 비지도학습은 입력 데이터만을 사용하여 데이터 간의 패턴이나 구조를 파악하는 것입니다.
=> 지도학습: 정답(Label)이 있는 데이터를 학습
예시) 분류: 범주현 데이터를 각 class별로 나누는 것(범주형 변수)
회귀: 하나의 가설에 미치는 다양한 수치형 변수들과의 인과성 분석(수치형 변수)
=> 비지도학습: 정답(Label)없는 데이터를 학습
예시) 군집화: 유사도가 높은 범주끼리 모아주는 것, 분류와는 다르게 정답이 업삳.(범주형 변수)
차원축소: 고차원 데이터를 차원을 축소해서 분석할 특성을 줄이고 한눈에 볼 수 있게 해준다.(수치형 변수)
강화학습: 당근과 채찍을 번갈아 사용하면서 모델이 스스로 정답을 찾아다고록 하는 알고리즘
특정 알고리즘(특히 회귀, 군집화) 한쪽에 치우친 데이터의 경우 잘 학습하지 못함
-> cut을 사용하여 데이터를 구간화
-> 혹은 log를 사용하여 정규분포로 만들어줌
로그함수
음수에 로그를 적용할 수 없는 경우, 일반적으로 다음과 같은 방법들이 사용됩니다.
Min-max scaling:
데이터 최소값을 0으로, 최대값을 1로 변환합니다. 그 후, 변환된 값을 다시 로그를 적용합니다.
Box-Cox 변환:
Box-Cox 변환은 양수 데이터에 대해 사용되는 데이터 변환 방법 중 하나입니다. 음수 값을 변환하기 위해서는 먼저 상수를 더해서 모든 값이 양수가 되도록 만들어줍니다. 그 후에 Box-Cox 변환을 적용하고, 변환된 값을 다시 원래 상수를 빼서 원래 음수 값을 얻어낼 수 있습니다.
Yeo-Johnson 변환:
Yeo-Johnson 변환은 Box-Cox 변환과 비슷한 방법으로 음수 값을 처리합니다. Box-Cox 변환에서는 음수 값을 처리하지 못하는데 비해 Yeo-Johnson 변환은 모든 값을 처리할 수 있습니다.
=> 위의 방법들은 모두 데이터 분포를 변환하여 좀 더 대칭적이고 정규성을 가진 분포로 변환하여 분석할 수 있도록 도와줍니다.
실루엣 분석
https://scikit-learn.org/stable/auto_examples/cluster/plot_kmeans_silhouette_analysis.html
실루엣 분석은 결과 클러스터 간의 분리 거리를 연구하는 데 사용할 수 있습니다. 실루엣 플롯은 한 클러스터의 각 포인트가 인접한 클러스터의 포인트에 얼마나 가까운지 측정값을 표시하므로 클러스터 수와 같은 매개 변수를 시각적으로 평가할 수 있는 방법을 제공합니다. 이 측정값의 범위는 [-1, 1]입니다.
실루엣 계수가 +1에 가까울수록 샘플이 인접한 클러스터에서 멀리 떨어져 있음을 나타냅니다. 값이 0이면 샘플이 인접한 두 클러스터 사이의 결정 경계에 있거나 매우 가깝다는 것을 나타내며, 음수 값은 해당 샘플이 잘못된 클러스터에 할당되었을 수 있음을 나타냅니다.
이 예에서는 실루엣 분석을 사용하여 n_clusters에 대한 최적의 값을 선택합니다. 실루엣 플롯은 실루엣 점수가 평균보다 낮은 클러스터가 존재하고 실루엣 플롯의 크기가 크게 변동하기 때문에 n_clusters 값 3, 5 및 6이 주어진 데이터에 대한 잘못된 선택임을 보여줍니다. 실루엣 분석은 2와 4 사이를 결정할 때 좀 더 양면성이 있습니다.
또한 실루엣 플롯의 두께를 통해 클러스터 크기를 시각화할 수 있습니다. n_clusters가 2일 때 클러스터 0의 실루엣 플롯은 3개의 하위 클러스터가 하나의 큰 클러스터로 그룹화되기 때문에 크기가 더 큽니다. 그러나 n_clusters가 4인 경우 모든 플롯의 두께가 어느 정도 비슷하므로 오른쪽의 레이블이 지정된 분산형 차트에서도 확인할 수 있듯이 크기가 비슷해집니다.
Within-Cluster Sum of Square
클러스터 내 제곱 합계는 각 클러스터 내 관측값의 변동성을 측정하는 척도입니다. 일반적으로 제곱합이 작은 클러스터는 제곱합이 큰 클러스터보다 더 콤팩트합니다.
⇒ 점과 점 사이의 거리를 구할 때, 제곱을 한 다음에 다 더했다. 거리를 측정할 때 절대값을 사용하거나 제곱을 사용해서 측정하는 방법이 있는데 여기서는 제곱을 한 다음에 더한 것을 의미함. 거리가 가까울수록 군집화가 잘되었다는 것을 의미한다.
⇒ 거리값이 작게 나올수록 군집이 잘 되었다.
군집화 평가 방법
군집화 평가 방법으로 실루엣 분석(Shilhouette Analysis)이 있습니다. 실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타냅니다. 효율적으로 잘 분리됐다는 것은 다른 군집과의 거리는 떨어져 있고 동일 군집끼리의 데이터는 서로 가깝게 잘 뭉쳐 있다는 의미입니다. 군집화가 잘 될수록 개별 군집은 비슷한 정도의 여유공간을 가지고 떨어져 있을 것입니다.
K-평균 군집분석 과정 요약
- 초기값 seed K를 정해 seed 값을 중심으로 초기 군집을 형성한다.
- n개의 중심점을 찍은 후에, 이 중심점에서 각 점 간 거리의 합이 가장 최소화가 되는 중심점 n의 위치를 찾는다.
- 각 샘플의 레이블을 중심점에서 가까운 클러스터 기준으로 묶는다. (label 할당)
- 각 클러스터에 속한 샘플들의 평균을 계산하여 적절한 중심점를 업데이트한다.
-> 모든 개체가 군집으로 할당될 때까지 3~4번을 반복한다.
qcut방식과 머신러닝 방식 비교
기존 상대평가(qcut) 방법으로 고객을 군집화 할 수도 있고 변수가 엄청 많다면 qcut 으로 군집화 할 때 전처리 등이 까다로울 수도 있습니다. 예를 들어 설문조사, 인구통계학적 정보 등의 다양한 변수를 사용하고자 할 때 군집화 기법을 사용하면 비교적 간단하게 고객을 군집화 할 수도 있습니다.
머신러닝과 딥러닝
머신 러닝은 알고리즘을 사용하여 데이터를 구문 분석하고 해당 데이터에서 학습하며, 학습한 내용에 따라 정보에 근거한 결정을 내립니다.
딥 러닝은 알고리즘을 계층으로 구성하여 자체적으로 배우고 지능적인 결정을 내릴 수 있는 “인공 신경망”을 만듭니다.
딥 러닝은 머신 러닝의 하위 개념입니다. 둘 다 광범위한 인공 지능의 카테고리에 속하지만 인간과 가장 유사한 인공 지능을 구동하는 것은 딥 러닝입니다.
(출처: https://www.zendesk.kr/blog/machine-learning-and-deep-learning/)
딥러닝은 원본 표현에서는 의미를 찾기 어려운 데이터에서 특징을 추출하는 데 뛰어납니다. 대표적인 사례는 이미지, 비디오, 대화, 오디오이다. 이런 분야에서는 신경망이 탁월합니다. 반면 아직까지는 고객 데이터처럼 여러 종류의 데이터가 섞여 있는 작은 데이터셋에서는 신경망이 잘 맞지 않는 부분이 있습니다.
scikit-learn 머신러닝 알고리즘
출처: 박조은 강사님 강의자료
Scikit-learn에서는 다양한 머신러닝 알고리즘을 제공합니다
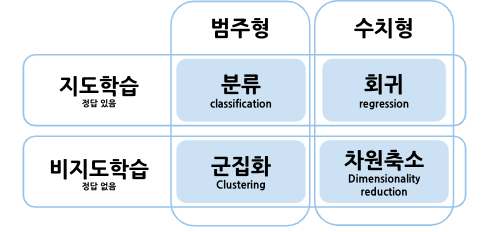
머신러닝 알고리즘은 정답 유무에 따라 지도학습, 비지도학습으로 나뉘며,
데이터 유형(범주형, 수치형)에 따라
분류, 회귀, 군집화, 차원축소 등의 방법을 이용하여 다양한 문제를 해결합니다.
데이터를 전처리는 분석 결과/인사이트와 모델 성능에 직접적인 영향을 미치기 때문에 매우 중요하게 다뤄집니다
결측치가 있다면 머신러닝 알고리즘 내부에서 연산을 할 수 없기 때문에 보통 오류가 발생하게 됩니다. 최근에는 결측치가 있어도 동작을 하는 알고리즘도 있습니다.(히스토그램 기반의 알고리즘이 결측치가 있어도 동작합니다.)
