
✔️ 본 포스팅은 HTTP 완벽 가이드 1장 내용입니다.
1장에서 다루는 내용
1.1 HTTP: 인터넷의 멀티미디어 배달부
HTTP는 전 세계의 웹 서버로부터 대량(수십억 개의 이미지, HTML 페이지, 텍스트 파일 등)의 정보를 빠르고, 간편하고, 정확하게 사람들의 PC에 설치된 웹브라우저로 옮겨준다.
HTTP는 신뢰성 있는 데이터 전송 프로토콜을 사용하기 때문에, 데이터가 전송 중 손상되거나 꼬이지 않음을 보장한다. 신뢰성 있는 전송 덕분에 사용자는 인터넷에서 얻은 정보가 손상된 게 아닌지 염려하지 않아도 되고, 개발자는 인터넷의 결함이나 약점에 대한 걱정 없이 애플리케이션 고유의 기능을 구현하는 데 집중할 수 있다.
1.2 웹 클라이언트와 서버
웹 콘텐츠는 웹 서버에 존재한다. 웹 서버는 HTTP 프로토콜로 의사소통하기 때문에 보통 HTTP 서버라 불린다.
이들 웹 서버는 인터넷의 데이터를 저장하고, HTTP 클라이언트가 요청한 데이터를 제공한다.

위 처럼 클라이언트는 서버에게 HTTP 요청을 보내고 서버는 요청된 데이터를 HTTP 응답으로 돌려준다. HTTP 클라이언트와 HTTP 서버는 월드 와이드 웹의 기본 요소다.
예를 들어 "http://www.oreilly.com/index.html" 페이지를 열어볼 때, 웹 브라우저는 HTTP 요청을 www.oreilly.com 서버로 보낸다. 서버는 요청을 받은 객체(이 경우 "/index.html")을 찾고, 성공했다면 그것의 타입, 길이 등의 정보와 함께 HTTP 응답에 실어서 클라이언트에게 보낸다.
1.3 리소스
웹 서버는 웹 리소스를 관리하고 제공한다. 웹 리소스는 웹 콘텐츠의 원천이다.
가장 단순한 웹 리소스는 웹 서버 파일 시스템의 정적 파일이다. 정적 파일은 텍스트 파일, HTML 파일, 마이크로소프트 워드 파일, JPEG 이미지 파일, 그 외 모든 종류의 파일을 포함한다.
그러나 리소스는 반드시 정적 파일이어야 할 필요는 없다. 리소스는 요청에 따라 콘텐츠를 생산하는 프로그램이 될 수도 있다. 이들 동적 콘텐츠 리소스는 사용자가 누구인지, 어떤 정보를 요청했는지, 몇 시인지에 따라 다른 콘텐츠를 생성한다.
1.3.1 미디어 타입
인터넷은 수천 가지 데이터 타입을 다루기 때문에, HTTP는 웹에서 전송되는 객체 각각에 신중하게 MIME 타입이라는 데이터 포맷 라벨을 붙인다. MIME(Multipurpose Internet Mail Extensions, 다목적 인터넷 메일 확장)은 원래 각기 다른 전자메일 시스템 사이에서 메시지가 오갈 때 겪는 문제점을 해결하기 위해 설계되었다.
웹 서버는 모든 HTTP 객체 데이터에 MIME 타입을 붙인다.웹 브라우저는 서버로부터 객체를 돌려받을 때, 다룰 수 있는 객체인지 MIME 타입을 통해 확인한다. 대부분의 웹 브라우저는 잘 알려진 객체 타입 수백 가지를 다룰 수 있다. 이미지 파일을 보여주고, HTML 파일을 분석하거나 포맷팅하고, 오디오 파일을 컴퓨터의 스피커를 통해 재생하고, 특별한 포맷의 파일을 다루기 위해 외부 플러그인 소프트웨어를 실행한다.

MIME 타입은 사선(/)으로 구분된 주 타입(primary object type)과 부 타입(specific subtype)으로 이루어진 문자열 라벨이다.
예를 들면,
- HTML로 작성된 텍스트 문서는 text/html 라벨이 붙는다.
- Plain ASCII 텍스트 문서는 text/plain 라벨이 붙는다.
- JPEG 이미지는 image/jpeg가 붙는다.
- GIF 이미지는 image/gif가 된다.
수백 가지의 잘 알려진 MIME 타입과, 그보다 더 많은 실험용 혹은 특정 용도의 MIME 타입이 존재한다.
1.3.2 URI
웹 서버 리소스는 각자 이름을 갖고 있기 때문에, 클라이언트는 관심 있는 리소스를 지목할 수 있다.
서버 리소스 이름은 통합 자원 식별자(uniform resource identifier), 혹은 URI로 불린다. URI는 인터넷의 우편물 주소 같은 것으로, 정보 리소스를 고유하게 식별하고 위치를 지정할 수 있다.
'죠의 컴퓨터 가게'의 웹 서버에 있는 이미지 리소스에 대한 URI라면 이런 식이다.
http://www.joes-hardware.com/specials/saw-blade.gif
{kind=link}
아래는 죠의 컴퓨터 가게 서버에 있는 GIF 형식의 톱날 그림 리소스에 대한 URI가 HTTP 프로토콜에서 어떻게 해석되는지 보여준다. HTTP는 주어진 URI로 객체를 찾아온다. URI에는 두 가지가 있는데, URL과 URN이라는 것이다.

1.3.3 URL
통합 자원 지시자(uniform resource locator, URL)는 리소스 식별자의 가장 흔한 형태다. URL은 특정 서버의 한 리소스에 대한 구체적인 위치를 서술한다. URL은 리소스가 정확히 어디에 있고 어떻게 접근할 수 있는지 분명히 알려준다. 다음 표는 URL의 몇 가지 예다.
| URL | 설명 |
|---|---|
| http://www.oreilly.com/index.html | 오라일리 출판사 홈페이지의 URL |
| http://www.yahoo.com/images/logo.gif | 야후 웹 사이트 로고의 URL |
{kind=link}
대부분의 URL은 세 부분으로 이루어진 표준 포맷을 따른다.
- URL의 첫 번째 부분은 스킴(scheme)이라고 불리는데, 리소스에 접근하기 위해 사용되는 프로토콜을 서술한다. 보통 HTTP 프로토콜(http://)이다.
- 두 번째 부분은 서버의 인터넷 주소를 제공한다. (예: www.joes-hardware.com)
- 마지막은 웹 서버의 리소스를 가리킨다. (예: /specials/saw-blade.gif)
오늘날 대부분의 URI는 URL이다.
1.3.4 URN
URI의 두 번째 종류는 유니폼 리소스 이름(uniform resource name, URN)이다. URN은 콘텐츠를 이루는 한 리소스에 대해, 그 리소스의 위치에 영향 받지 않는 유일무이한 이름 역할을 한다. 이 위치 독립적인 URN은 리소스를 여기저기로 옮기더라도 문제없이 동작한다. 리소스가 그 이름을 변하지 않게 유지하는 한, 여러 종류의 네트워크 접속 프로토콜로 접근해도 문제없다.
URN은 여전히 실험 중인 상태고 아직 널리 채택되지 않았다. 효율적인 동작을 위해 URN은 리소스 위치를 분석하기 위한 인프라 지원이 필요한데, 그러한 인프라가 부재하기에 URN 채택이 더 늦춰지고 있다.
1.4 트랜잭션
HTTP 트랜잭션은 요청 명령(클라이언트에서 서버로 보내는)과 응답 결과(서버가 클라이언트에게 돌려주는)로 구성되어 있다. 이 상호작용은 아래 그림과 같이 HTTP 메시지라고 불리는 정형화된 데이터 덩어리를 이용해 이루어진다.
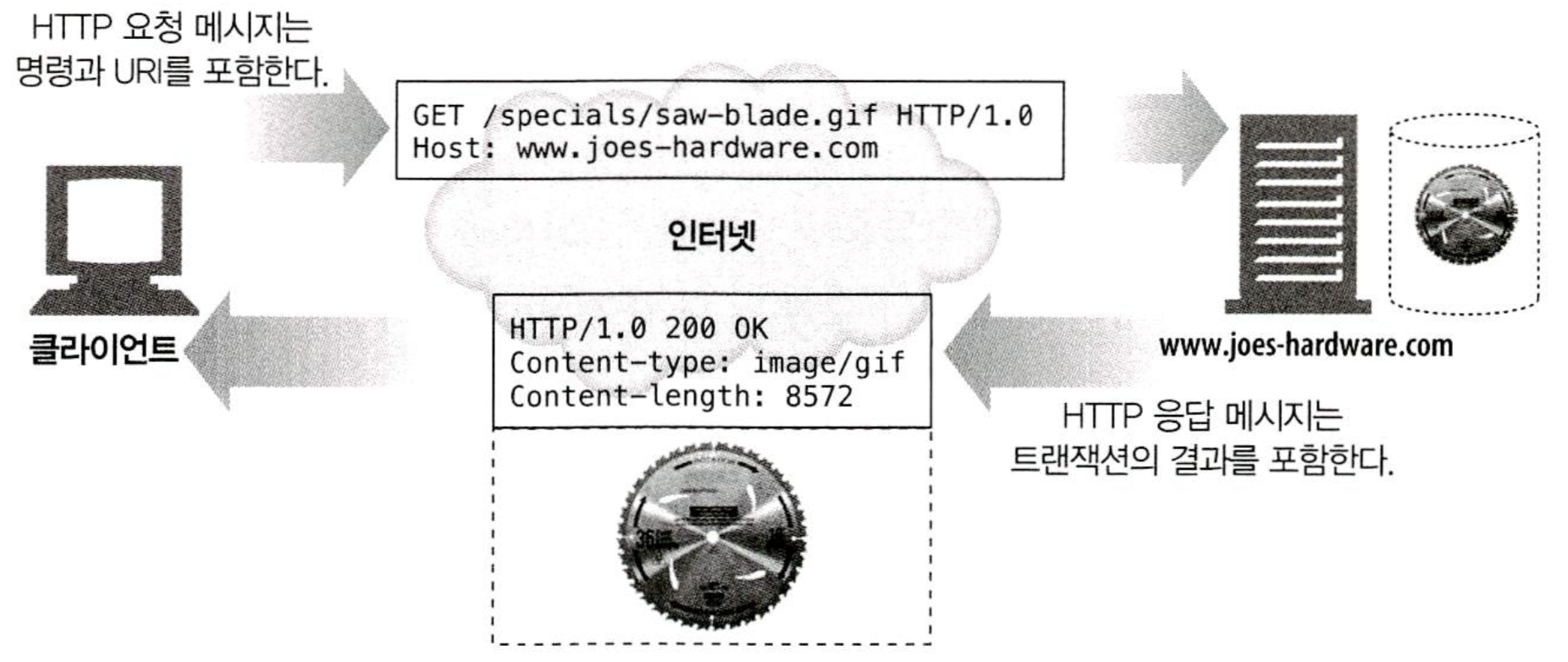
1.4.1 메서드
HTTP는 HTTP 메서드라고 불리는 여러 가지 종류의 요청 명령을 지원한다. 모든 HTTP 요청 메시지는 한 개의 메서드를 갖는다. 메서드는 서버에게 어떤 동작이 취해져야 하는지 말해준다(웹 페이지 가져오기, 게이트웨이 프로그램 실행하기, 파일 삭제하기 등)
아래는 가장 많이 사용되는 HTTP 메서드이다.
| HTTP 메서드 | 설명 |
|---|---|
| GET | 서버에서 클라이언트로 지정한 리소스를 보내라 |
| PUT | 클라이언트에서 서버로 보낸 데이터를 지정한 이름의 리소스로 저장하라 |
| DELETE | 지정한 리소스를 서버에서 삭제하라 |
| POST | 클라이언트 데이터를 서버 게이트웨이 애플리케이션으로 보내라 |
| HEAD | 지정한 리소스에 대한 응답에서, HTTP 헤더 부분만 보내라 |
1.4.2 상태 코드
모든 HTTP 응답 메시지는 상태 코드와 함께 반환된다. 상태 코드는 클라이언트에게 요청이 성공했는지 아니면 추가 조치가 필요한지 알려주는 세 자리 숫자다.
아래는 흔히 쓰이는 상태 코드이다.
| HTTP 상태 코드 | 설명 |
|---|---|
| 200 | 좋다. 문서가 바르게 반환되었다 |
| 302 | 다시 보내라. 다른 곳에 가서 리소스를 가져가라 |
| 404 | 없음. 리소스를 찾을 수 없다. |
HTTP는 각 숫자 상태 코드에 텍스트로 된 "사유 구절(reason phrase)"도 함께 보낸다. ex) 200 OK, 302 Found, 404 Not Found
HTTP 메서드, HTTP 상태 코드는 3장에서 자세히 설명한다.
1.4.3 웹페이지는 여러 객체로 이루어질 수 있다
애플리케이션은 보통 하나의 작업을 수행하기 위해 여러 HTTP 트랜잭션을 수행한다. 예를 들어, 웹 브라우저는 시각적으로 풍부한 웹페이지를 가져올 때 대량의 HTTP 트랜잭션을 수행한다. 페이지 레이아웃을 서술하는 HTML '뼈대'를 한 번의 트랜잭션으로 가져온 뒤, 첨부된 이미지, 그래픽 조각, 자바 애플릿 등을 가져오기 위해 추가로 HTTP 트랜잭션들을 수행한다. 이 리소스들은 아래 그림과 같이 다른 서버에 위치할 수도 있다. 이와 같이 '웹페이지'는 보통 하나의 리소스가 아닌 리소스의 모음이다.
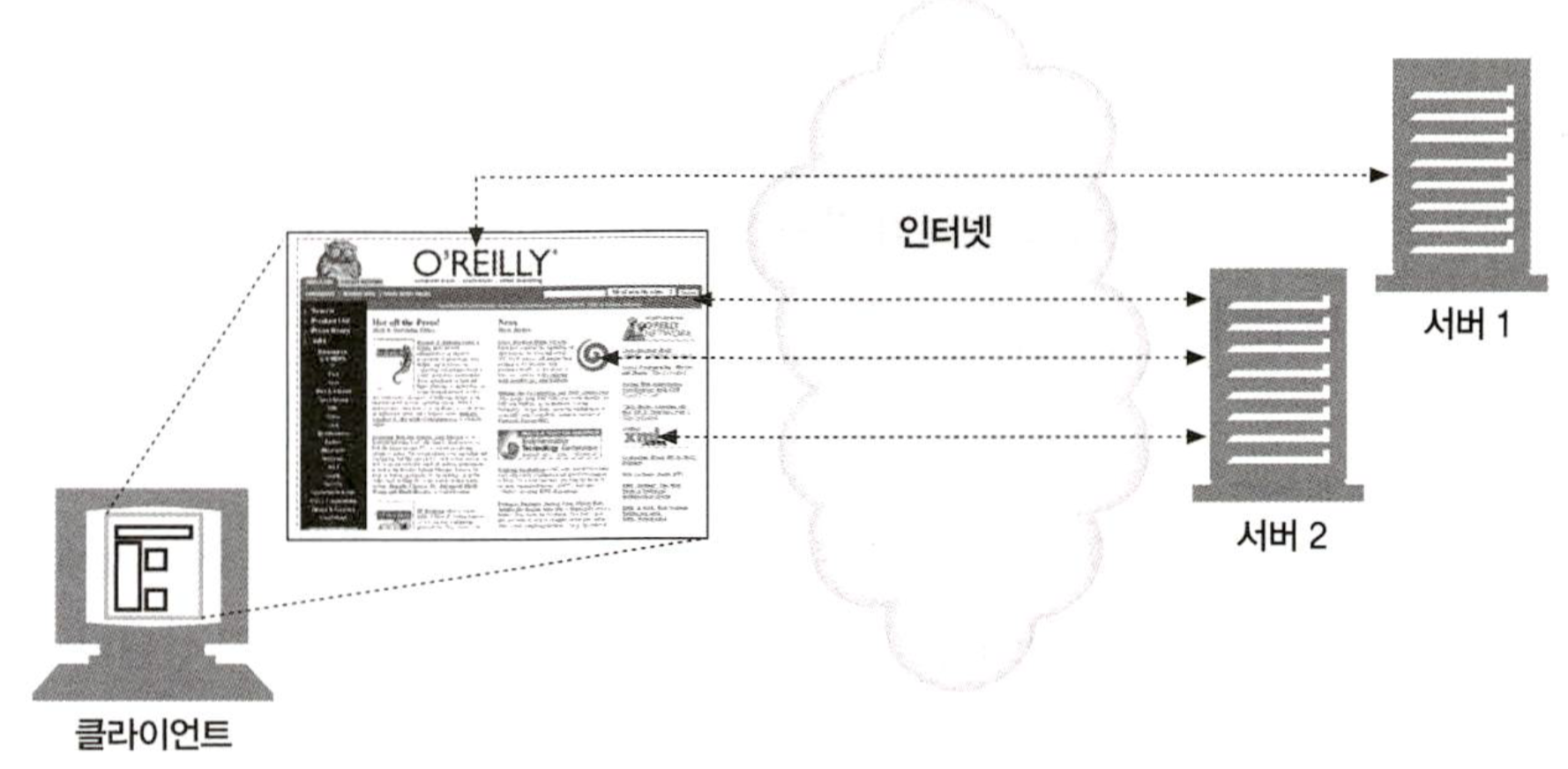
1.5 메시지
HTTP 메시지는 단순한 줄 단위의 문자열이다. 이진 형식이 아닌 일반 텍스트이기 때문에 사람이 읽고 쓰기 쉽다.
아래 그림은 간단한 트랜잭션에 대한 HTTP 메시지를 보여주고 있다.
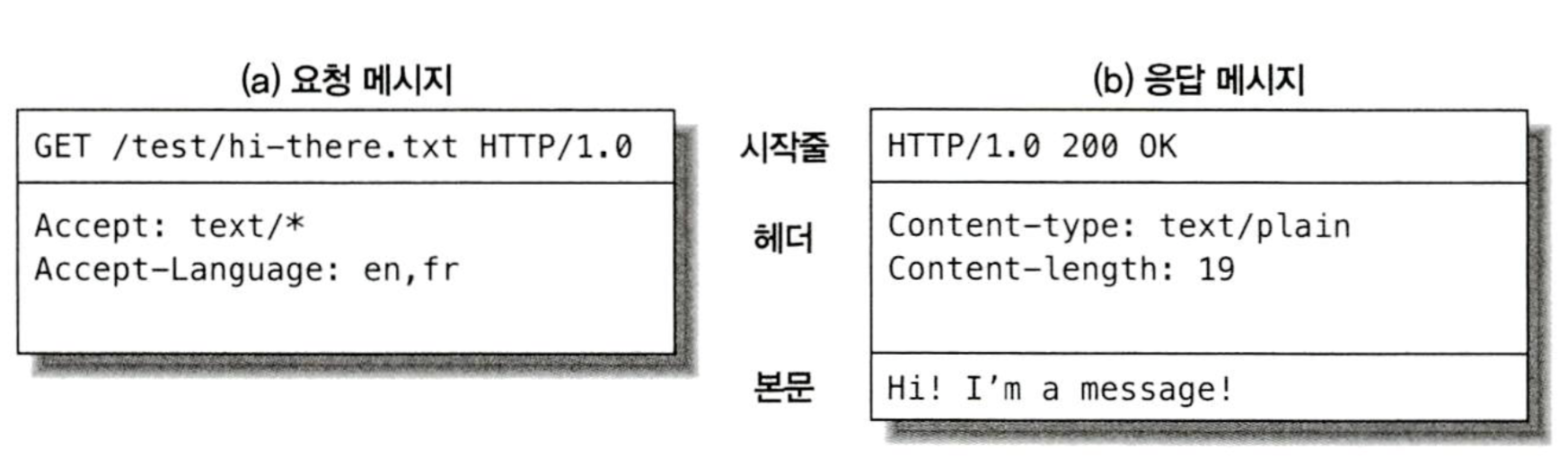
웹 클라이언트에서 웹 서버로 보낸 HTTP 메시지를 요청 메시지라 부른다. 서버에서 클라이언트로 가는 메시지는 응답 메시지라고 부른다. 그 외에 다른 종류의 HTTP 메시지는 없으며, HTTP 요청과 응답 메시지의 형식은 굉장히 비슷하다.
HTTP 메시지는 다음의 세 부분으로 이루어진다.
-
시작줄
메시지의 첫 줄은 시작줄로, 요청이라면 무엇을 해야하는지 응답이라면 무슨 일이 일어났는지 나타낸다.
-
헤더
시작줄 다음에는 0개 이상의 헤더 필드가 이어진다. 각 헤더 필드는 쉬운 구문분석을 위해 쌍점(:)으로 구분되어 있는 하나의 이름과 하나의 값으로 구성된다. 헤더 필드를 추가하려면 그저 한 줄을 더하기만 하면 된다. 헤더는 빈 줄로 끝난다.
-
본문
빈 줄 다음에는 어떤 종류의 데이터든 들어갈 수 있는 메시지 본문이 필요에 따라 올 수 있다. 요청의 본문은 웹 서버로 데이터를 실어 보내며, 응답의 본문은 클라이언트로 데이터를 반환한다.
HTTP 메시지도 3장에서 자세히...
1.6 TCP 커넥션
어떻게 메시지가 TCP(Transmission Control Protocol, 전송 제어 프로토콜) 커넥션을 통해 한 곳에서 다른 곳으로 옮겨가는지 이야기 해보자.
1.6.1 TCP/IP
HTTP는 애플리케이션 계층 프로토콜이다. HTTP는 네트워크 통신의 핵심적인 세부사항에 대해서 신경쓰지 않고, 대신 대중적이고 신뢰성 있는 인터넷 전송 프로토콜인 TCP/IP에게 맡긴다.
TCP는 다음을 제공한다.
- 오류 없는 데이터 전송
- 순서에 맞는 전달 (데이터는 언제나 보낸 순서대로 도착한다)
- 조각나지 않는 데이터 스트림 (언제든 어떤 크기로든 보낼 수 있다)
인터넷 자체가 전 세계의 컴퓨터와 네트워크 장치들 사이에서 대중적으로 사용되는 TCP/IP에 기초하고 있다. TCP/IP는 TCP와 IP가 이루는, 패킷 교환 네트워크 프로토콜의 집합이다. TCP/IP는 각 네트워크와 하드웨어의 특성을 숨기고, 어떤 종류의 컴퓨터나 네트워크든 서로 신뢰성 있는 의사소통을 하게 해 준다.
일단 TCP 커넥션이 맺어지면, 클라이언트와 서버 컴퓨터 간에 교환되는 메시지가 없어지거나, 손상되거나, 순서가 뒤바뀌어 수신되는 일은 결코 없다.
네트워크 개념상, HTTP 프로토콜은 TCP 위의 계층이다. HTTP는 자신의 메시지 데이터를 전송하기 위해 TCP를 사용한다. 이와 유사하게 TCP는 IP 위의 계층이다.

1.6.2 접속, IP 주소 그리고 포트번호
HTTP 클라이언트가 서버에 메시지를 전송할 수 있게 되기 전에, 인터넷 프로토콜(Internet Protocol, IP) 주소와 포트번호를 사용해 클라이언트와 서버 사이에 TCP/IP 커넥션을 맺어야 한다.
TCP 커넥션을 맺는 것은 다른 회사 사무실에 있는 누군가에게 전화를 거는 것과 다소 비슷하다. 먼저 회사의 전화번호를 누른다. 이렇게 하면 그 회사로 연결된다. 그 다음엔 전화를 걸고자 하는 상대방이 쓰는 번호를 누른다.
TCP에서는 서버 컴퓨터에 대한 IP 주소와 그 서버에서 실행 중인 프로그램이 사용 중인 포트번호가 필요하다.
HTTP 서버의 IP 주소와 포트번호는 어떻게 알아낼 수 있을까?
URL을 사용하면 된다. URL이란 리소스에 대한 주소이고, URL은 그 리소스를 가지고 있는 장비에 대한 IP 주소를 알려줄 수 있다. 몇 가지 URL을 살펴보자.
- http://207.200.83.29:80/index.html
- http://www.netscape.com:80/index.html
- http://www.netscape.com/index.html
첫 번째 URL은 IP 주소 '207.200.83.29'와 포트번호 '80'을 갖고 있다.
두 번째 URL에는 숫자로 된 IP 주소가 없다. 대신 글자로 된 도메인 이름 혹은 호스트 명을 갖고 있다. 호스트 명은 IP 주소에 대한 이해하기 쉬운 형태의 별명이다. 호스트 명은 도메인 이름 서비스(Domain Name Service, DNS)라 불리는 장치를 통해 쉽게 IP로 변환될 수 있으므로 모든 준비는 끝난 것이다.
마지막 URL은 포트번호가 없다. HTTP URL에 포트번호가 빠진 경우에는 기본값 80이라고 가정하면 된다.
IP주소와 포트번호를 이용해 클라이언트는 TCP/IP로 쉽게 통신할 수 있다. 다음 그림은 웹 브라우저가 어떻게 HTTP를 이용해서 멀리 떨어진 곳에 있는 서버의 단순한 HTML 리소스를 사용자에게 보여주는지 묘사하고 있다.
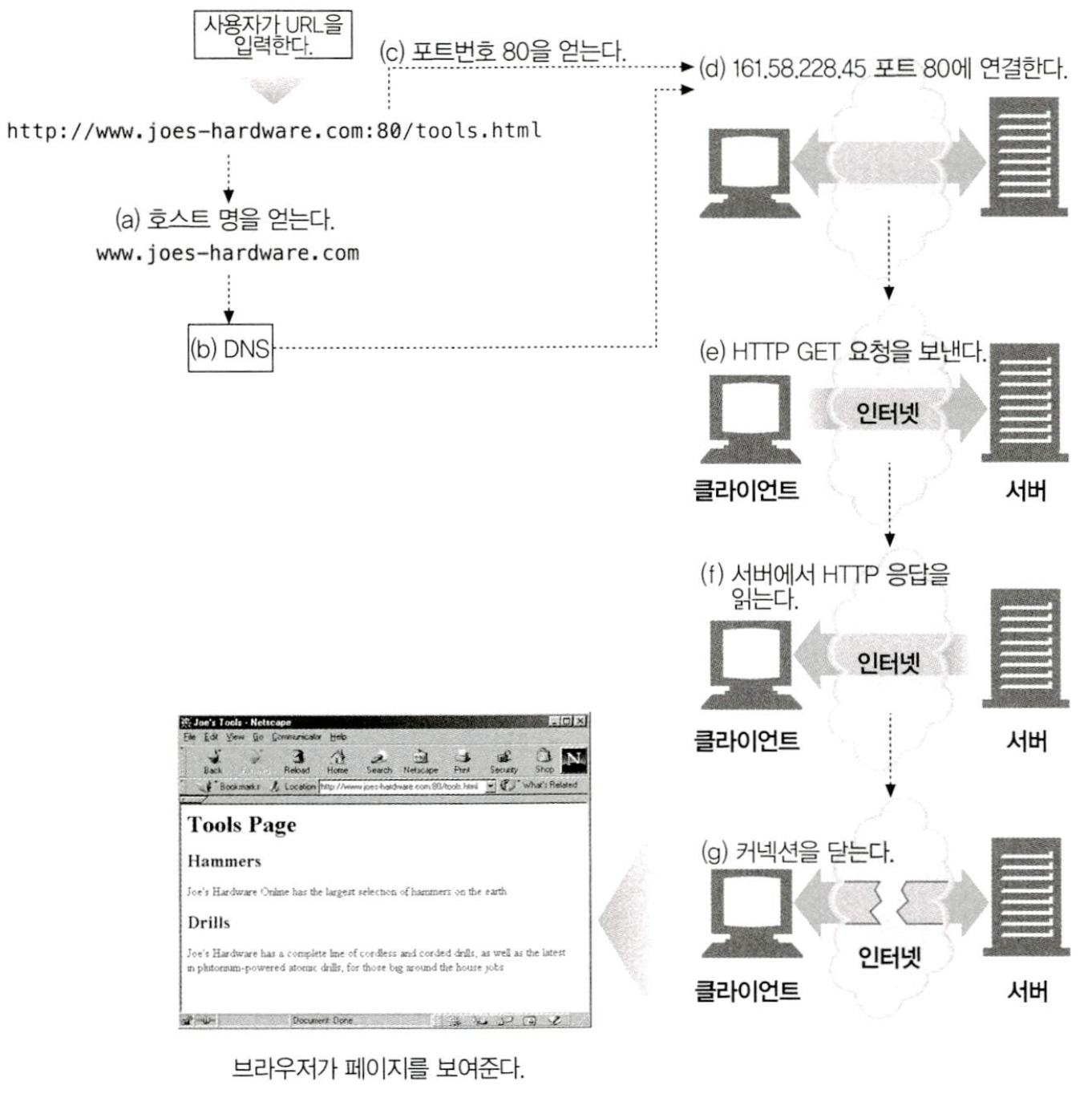
순서는 다음과 같다.
(a) 웹 브라우저는 서버의 URL에서 호스트 명을 추출한다.
(b) 웹 브라우저는 서버의 호스트 명을 IP로 변환한다.
(c) 웹 브라우저는 URL에서 포트번호(있다면)를 추출한다.
(d) 웹 브라우저는 웹 서버와 TCP 커넥션을 맺는다.
(e) 웹 브라우저는 서버에 HTTP 요청을 보낸다.
(f) 서버는 웹 브라우저에 HTTP 응답을 돌려준다.
(g) 커넥션이 닫히면, 웹 브라우저는 문서를 보여준다.
1.7 프로토콜 버전
-
HTTP/0.9
1991년의 HTTP 프로토타입은 HTTP/0.9로 알려져 있다. 이 프로토콜은 심각한 디자인 결함이 다수 있고 구식 클라이언트하고만 같이 사용할 수 있다. HTTP/0.9는 오직 GET 메서드만 지원하고, 멀티미디어 콘텐츠에 대한 MIME 타입이나, HTTP 헤더, 버전 번호는 지원하지 않는다. HTTP/0.9는 원래 간단한 HTML 객체를 받아오기 위해 만들어진 것이다.
-
HTTP/1.0
1.0은 처음으로 널리 쓰이기 시작한 HTTP 버전이다. HTTP/1.0은 버전 번호, HTTP 헤더, 추가 메서드, 멀티미디어 객체 처리를 추가했따. HTTP/1.0은 시각적으로 매력적인 웹페이지와 상호작용하는 폼을 실현했고 이는 월드 와이드 웹을 대세로 만들었다. HTTP/1.0은 결코 잘 정의된 명세가 아니다. HTTP가 상업적, 학술적으로 급성장하던 시기에 만들어진, 잘 동작하는 용례들의 모음에 가깝다.
-
HTTP/1.0+
1990년대 중반, 월드 와이드 웹이 급격히 팽창하고 상업적으로도 성공하면서 여러 유명 웹 클라이언트와 서버 들은 그에 따른 요구를 만족시키기 위해 발 빠르게 HTTP에 기능을 추가해갔다. 오래 지속되는 "keep-alive" 커넥션, 가상 호스팅 지원, 프락시 연결 지원을 포함해 많은 기능이 공식적이진 않지만 사실상의 표준으로 HTTP에 추가되었다.
-
HTTP/1.1
HTTP/1.1은 HTTP 설계의 구조적 결함 교정, 두드러진 성능 최적화, 잘못된 기능 제거에 집중했다. 뿐만 아니라 HTTP/1.1은 더 복잡해진 웹 애플리케이션과 배포를 지원한다. HTTP/1.1은 현재의 HTTP 버전이다.
-
HTTP/2.0
HTTP/2.0은 HTTP/1.1 성능 문제를 개선하기 위해 구글의 SPDY 프로토콜을 기반으로 설계가 진행 중인 프로토콜이다. 더 자세한 것은 10장에서..
1.8 웹의 구성요소
-
프락시
클라이언트와 서버 사이에 위치한 HTTP 중개자
-
캐시
많이 찾는 웹페이지를 클라이언트 가까이에 보관하는 HTTP 창고
-
게이트웨이
다른 애플리케이션과 연결된 특별한 웹 서버
-
터널
단순히 HTTP 통신을 전달하기만 하는 특별한 프락시
-
에이전트
자동화된 HTTP 요청을 만드는 준지능적(semi-intelligent) 웹클라이언트
1.8.1 프락시
웹 보안, 애플리케이션 통합, 성능 최적화를 위한 중요한 구성요소인 HTTP 프락시 서버에 대해 살펴보자.
아래 그림에서 보다시피, 프락시는 클라이언트와 서버 사이에 위치하여, 클라이언트의 모든 HTTP 요청을 받아 서버에 전달한다. 이 애플리케이션은 사용자를 위한 프락시로 동작하며 사용자를 대신해서 서버에 접근한다.
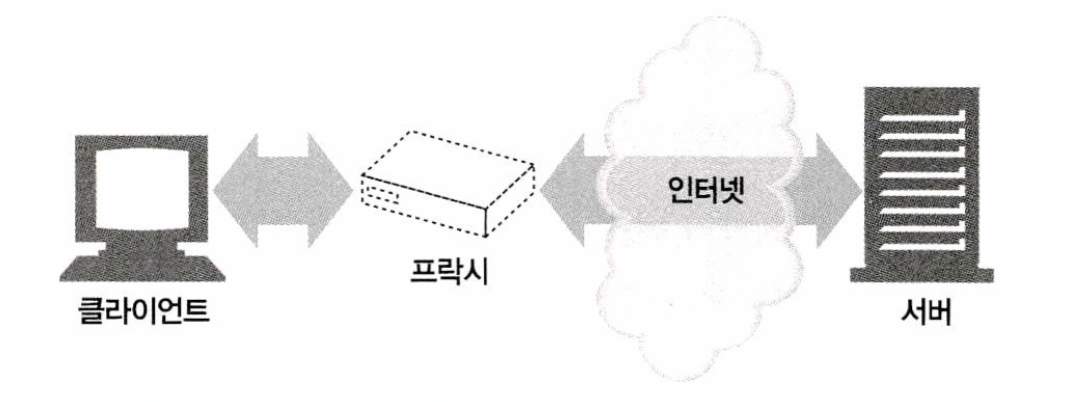
프락시는 주로 보안을 위해 사용된다. 즉, 모든 웹 트래픽 흐름 속에서 신뢰할 만한 중개자 역할을 한다. 또는 프락시는 요청과 응답을 필터링한다. 예를 들어, 회사에서 무엇인가를 다운 받을 때 애플리케이션 바이러스를 검출하거나 초등학교 학생들에게서 성인 콘텐츠를 차단한다. 프락시는 6장에서 자세히...
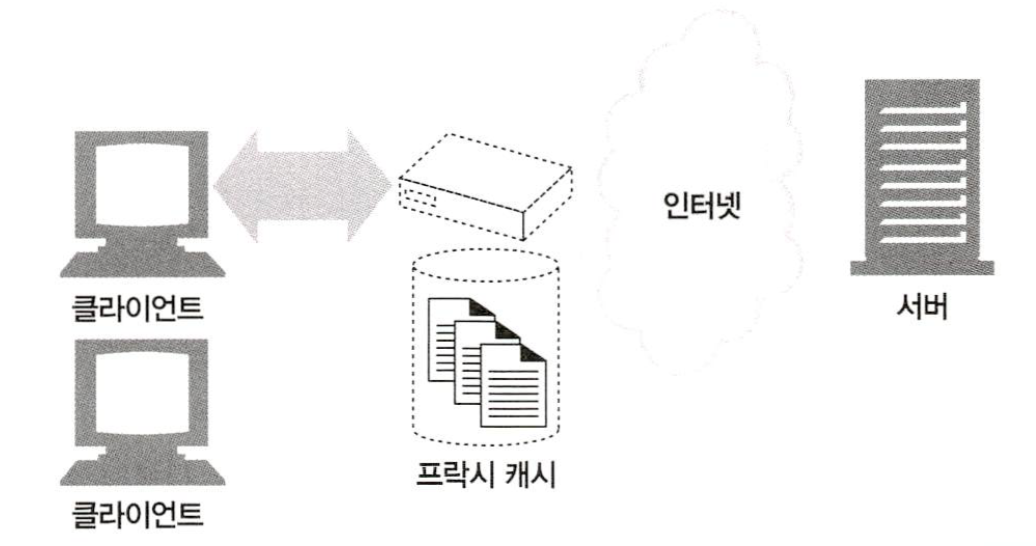
1.8.2 캐시
웹 캐시와 캐시 프락시는 자신을 거쳐 가는 문서들 중 자주 찾는 것의 사본을 저장해 두는, 특별한 종류의 HTTP 프락시 서버다. 다음번에 클라이언트가 같은 문서를 요청하면 그 캐시가 갖고 있는 사본을 받을 수 있다.
클라이언트는 멀리 떨어진 웹 서버보다 근처의 캐시에서 훨씬 더 빨리 문서를 다운 받을 수 있다. HTTP는, 캐시를 효율적으로 동작하게 하고 캐시된 콘텐츠를 최신 버전으로 유지하면서 동시에 프라이버시도 보호하기 위한 많은 기능을 정의한다. 7장에서 캐싱 기술에 대해...
1.8.3 게이트웨이
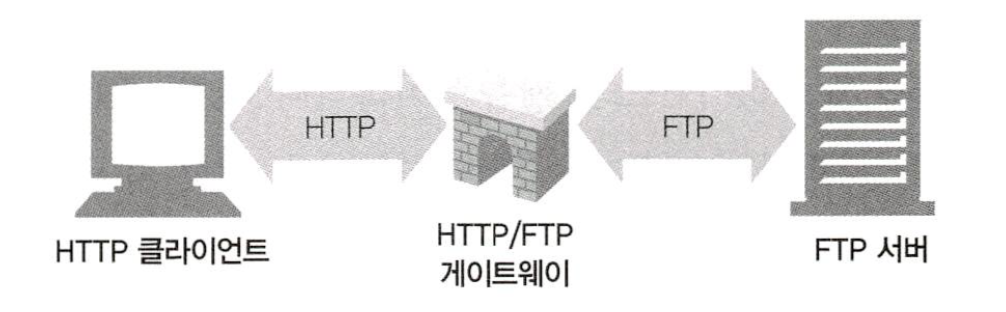
게이트웨이는 다른 서버들의 중개자로 동작하는 특별한 서버다. 게이트웨이는 주로 HTTP 트래픽을 다른 프로토콜로 변환하기 위해 사용된다. 게이트웨이는 언제나 스스로가 리소스를 갖고 있는 진짜 서버인 것처럼 요청을 다룬다. 클라이언트는 자신이 게이트웨이와 통신하고 있음을 알아채지 못할 것이다.
HTTP/FTP 게이트웨이는 FTP URI에 대한 HTTP 요청을 받아들인 뒤, FTP 프로토콜을 이용해 문서를 가져온다. 받아온 문서는 HTTP 메시지에 담겨 클라이언트에게 보낸다.
1.8.4 터널
터널은 두 커넥션 사이에서 날(raw) 데이터를 열어보지 않고 그대로 전달해주는 HTTP 애플리케이션이다. HTTP 터널은 주로 비 HTTP 데이터를 하나 이상의 HTTP 연결을 통해 그대로 전송해주기 위해 사용된다.
HTTP 터널을 활용하는 대표적인 예로, 암호화된 SSL 트래픽을 HTTP 커넥션으로 전송함으로써 웹 트래픽만 허용하는 사내 방화벽을 통과시키는 것이 있다.
1.8.5 에이전트
사용자 에이전트는 사용자를 위해 HTTP 요청을 만들어주는 클라이언트 프로그램이다. 웹 요청을 만드는 애플리케이션은 뭐든 HTTP 에이전트다. 지금까지 우리는 한 가지 종류의 HTTP 에이전트, 웹 브라우저에 대해서만 이야기했다. 그러나 사용자 에이전트에는 여러 가지 종류가 더 있다.
예를 들어, 사람의 통제 없이 스스로 웹을 돌아다니며 HTTP 트랜잭션을 일으키고 콘텐츠를 받아오는 자동화된 사용자 에이전트가 있다. 이들 자동화된 에이전트는 보통 '스파이더'나 '웹로봇'과 같이 다채로운 이름을 가지고 있다.
