[Pet-Hub] 분양글 API 조회 성능 개선하기(Feat. 성능이 28815배나 증가 한다고?)

✍ 분양글 API 개선을 하게 된 이유
Pet-Hub 서비스는 현재 이용자가 많이 없고, 게시글이 많아야 20개 ~ 30개 정도이기 때문에 조회 성능으로 인한 쿼리 튜닝이나 개선을 염두해야 될 정도로 성능 문제가 없는 서비스입니다.
초기에는 그렇지만 나중에 서비스가 확장되어 많은 유저들이 이용한다고 했을때 적절한 성능을 유지할 수 있는지에 대한 고민을 하게 되었습니다.
1000만개 ~ 1억개 정도의 데이터를 넣고 확인해 보고 싶었지만, 프로시저를 이용해 작업을 진행한다고 해도 시간이 걸리는 작업이기때문에 일단 2만개 정도의 데이터로 테스트를 해보았습니다.
개선하기 전의 쿼리
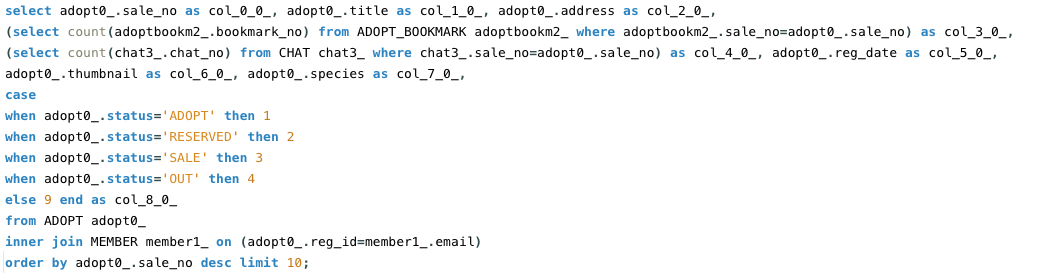
ADOPT(분양), ADOPT_BOOKMARK(관심 분양글), MEMBER(회원) 세개의 테이블을 조인하고 두개의 서브쿼리가 사용된 쿼리문입니다.
실행하는데 얼마나 시간이 걸리는지 확인해보겠습니다.

무려 219초(약 3분 40초)의 시간이 걸리는 충격적인 결과가 나오는 것을 볼 수 있었습니다.

😀 어떻게 개선해야 할까?
일단 어떤 부분에서 문제가 되는지 확인해보기 위해 실행계획을 확인해보았습니다.

현재 실행계획에서 눈여겨봐야 할 부분이 있는데 type과 rows 그리고 Extra 입니다.
type -> ALL
실행계획을 확인할때 인덱스를 적절히 활용하고 있는지 확인할 수 있는 중요한 지표입니다.
Table Full Scan(가장 최악의 방법) 방식으로 쿼리가 동작하는 경우 type에 ALL이 표시됩니다. 성능 면에서도 굉장히 좋지 않습니다.
rows
rows는 실행 비용을 계산하기 위해 몇개의 행을 확인했는지 대략적인 추정치를 보여주게 됩니다.
대부분 참고용으로 사용하고 있는데, 지금 보이는 실행계획에서는 테이블의 모든 데이터를 확인하고 있는 것을 볼 수 있어서 인덱스를 잘 타지 못하는 게 아닌가라는 의심을 해볼 수 있는 근거가 생겼습니다.
Extra
Extra를 보면 얻을 수 있는 정보들이 많은데, 여기서 눈 여겨 봐야 할 부분은 크게 세가지 입니다.
Using temporary(임시 테이블 사용), Using filesort(임시 테이블을 이용한 정렬), Using join buffer(조인 버퍼 사용)
Using temporary와 Using filesort가 같이 나타나는 경우에는, 정렬을 위해 임시 테이블을 사용하게 되는 것을 뜻합니다. 메모리내에서 임시 테이블을 만들고 작업하는 경우도 있지만 용량이 커서 감당하기 어려울 경우 디스크에서 이 작업을 수행하게 됩니다.
1억개의 데이터가 있다면 1억개의 데이터를 전부 임시 테이블에 저장시켜서 정렬을 수행하는 최악의 상황을 겪게 된다는 것을 의미하기도 하기에, 반드시 개선되야 하는 쿼리입니다.
개선 진행
실행계획을 보다보니 어디서부터 문제가 생긴것인지 확인하기가 어려운 부분이 있었습니다.
처음에 생각한 부분은 Member 테이블에서 적절한 인덱스가 없어, join buffer를 사용하고 있는 문제를 떠올렸습니다. 그렇다면 Member 테이블에 적절한 인덱스가 없어서 문제가 생기는 것인지 확인이 필요했습니다.
기존 쿼리에서 Member 테이블에 대한 조인 구문을 삭제하고 다시 실행 계획을 확인했습니다.

Using temporary와 Using filesort도 사라지고, Adopt 테이블도 index full scan을 사용하고 있는 것으로 실행계획이 변경되어 있었습니다.
따라서 성능 저하의 원인을, Member 테이블에 적절한 인덱스가 없어서 생긴 문제로 판단하고 쿼리를 수정해보았습니다.
Member 테이블과 Adopt 테이블이 조인할때 데이터를 필터링 하기 위해 사용하는 email 컬럼을 Member 테이블의 인덱스로 생성해주었습니다.
인덱스를 생성한 뒤 실행계획을 다시 확인해보겠습니다.

Adopt 테이블이 index full scan을 사용하고 있고, Member 테이블도 ref 조인 타입을 사용하고 있어서 상당히 개선되었다는 것을 확인할 수 있습니다.

기존 조회 시간인 219초보다 무려 3775배나 성능이 향상된 0.058초의 성능을 보여주고 있습니다.
이것만 해도 굉장히 성능이 좋아진거라고 볼 수 있지만, 서브쿼리를 걷어내고 조인 연산으로 쿼리를 풀어내면 성능을 조금 더 개선할 수 있다고 판단하여 추가 개선을 진행했습니다.
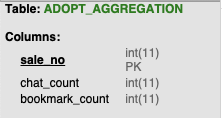
채팅방이 생성되거나, 분양글에 북마크를 등록하면 카운트가 증가하는 방식으로 통계테이블을 생성하고 이 테이블과 조인을 하도록 풀어내서 서브쿼리를 걷어내보았습니다.
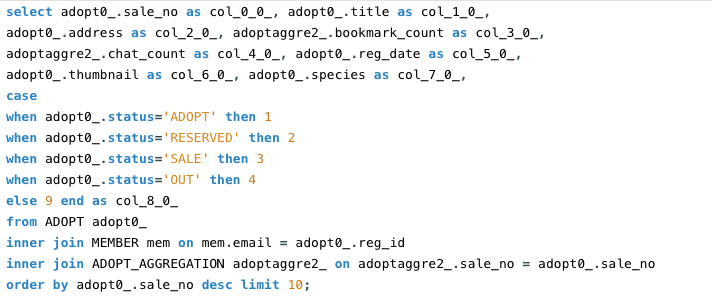
이 쿼리를 실행하면 어떤 결과가 나올까요?


기존 0.058초에서 0.0076초로 성능이 증가하였고 수치상으로 약 7.6배의 성능 향상을 이룰 수 있었습니다.
쿼리를 개선하기 전인 219초와 현재 성능을 비교하면 무려 28815배의 성능 향상을 이뤘습니다.
🤔 개선을 진행하며 느낀 점
쿼리 튜닝은 굉장히 어렵고 복잡하고 딥하게 들어가야 무언가 조금이라도 개선할 수 있다고 생각했습니다.
현재 쿼리도 물론 Index Full Scan 되고 있어서, 조금 더 개선할 수 있는 곳도 많고 아쉬운 부분이 있지만 오늘 느낀 점은 적절한 인덱스 생성으로 성능을 비약적으로 개선할 수 있다는 것이였습니다.
앞으로 데이터베이스의 내부 구조와 튜닝에 대해서 깊게 공부하고 싶다는 생각이 드는 좋은 경험이였던 것 같습니다.
오늘도 읽어주신 분들께 감사드립니다.


묻힌....
성능이 28815배나 증가 한다고??!!!
무쳤다..