😥 MSA 구조에서 복잡한 Join 문제
MSA 구조를 가진 시스템을 설계하고 프로젝트를 수행하다 보니, 각 서비스 별로 독립적인 데이터베이스를 가지게 되어서 생기는 문제가 있습니다.
그 문제는 보통 단일 DB를 조회할때는 문제가 생기지 않습니다. 복잡한 Join을 풀어내야 할 때 보통 문제가 되는데요.
예를 들어보겠습니다.
특정 회원이 결제한 주문건과 주문 상품을 조회해야 하는 API가 있다고 가정해보겠습니다.
이 데이터를 만들기 위해서는 회원 -> 결제, 결제 -> 주문 총 2번의 API 통신을 통해 애플리케이션에서 데이터를 조합해야 합니다.
이 문제를 어떻게 유연하게 해결할 수 있을까요?
😏 Read-Model 구축으로 해결해보자!
이 문제를 해결하기 위해서는 각 서비스 별로 DB가 물리적으로 분리되어 있다는 문제를 먼저 해결해야 합니다.
Join을 통해서 간단히 데이터를 조회하기 위해서는 각 서비스의 데이터가 한 군데 모여 있어야 한다는 것입니다.
그렇다면 MSA로 분산된 환경에서 DB를 하나로 합쳐서 단일 장애 지점을 만들 생각은 절대 아니겠죠??

그렇다면 어떻게 해결할 수 있을까요?
저는 Read-Model 구축을 통해 데이터 조회 최적화를 수행하기로 결정했습니다.
Read-Model 이란 A, B, C 서비스가 있을때 서비스 별로 분리된 데이터베이스를 사용하고 있다면,
A, B, C 서비스의 모든 데이터를 Read-Model의 데이터베이스에 전부 모아두고 조회시 사용하는 것을 말합니다.
즉, CQRS 적용을 통해 데이터를 쓰는 책임과 조회하는 책임을 분리하겠다는 뜻이죠.
그렇다면 Read-Model을 어떻게 구축하고 각 서비스와 데이터를 동기화 할건지 계획을 세워보겠습니다.
🙂 Read-Service 설계하기
여러 서비스 중 User-Service에 대해서 Read-Model과 데이터를 동기화하는 작업을 한다고 가정해보겠습니다.
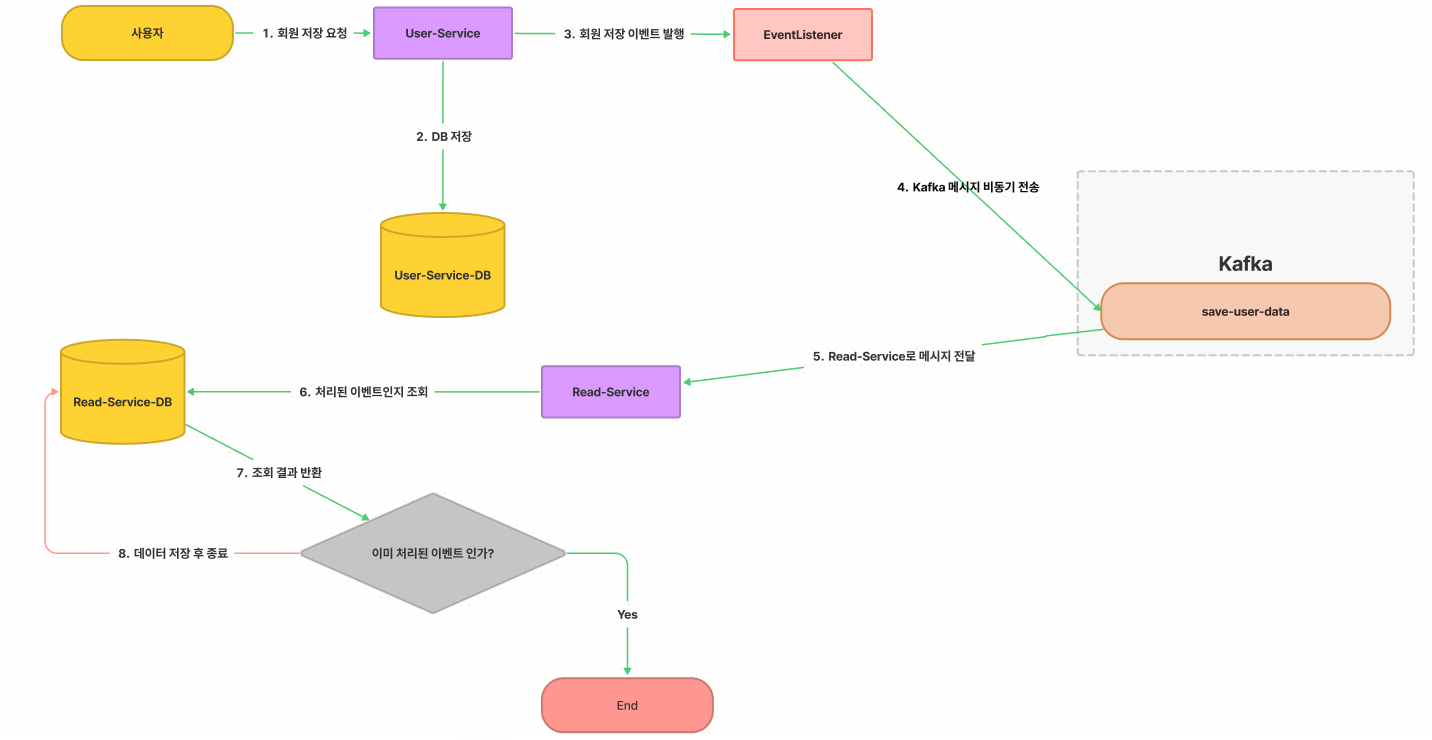
먼저 어떻게 데이터가 동기화 되는지 Flow-Chart를 통해 알아보겠습니다.
- 사용자가
회원 저장 요청을 하면, User-Service DB에 데이터를 저장합니다. - 데이터 저장에 성공하면
회원 저장 이벤트를 발행합니다. - EventListener는
Kakfa에 추가된 데이터를 전송합니다. save-user-dataTopic을 구독하고 있는 Read-Service는 메시지를Consume합니다.- 메시지에 담겨있는 이벤트
UUID를 보고 이벤트 처리 여부를 DB에서 확인합니다. - 이벤트가 처리되지 않았다면,
User-Service에서 추가된 데이터를 DB에 반영합니다.
왜 UUID를 보고 이벤트가 처리되지 않았을때만 데이터를 저장하도록 했을까요?
뒤에서 더 살펴보겠지만 간단히 설명드리면, Kafka 메시지가 중복 발행되었을 때 중복을 걸러낼 필요가 있기 때문입니다.
중복된 메시지로 인한 문제는 두 가지 방법으로 문제를 풀어나갈 수 있는데,
멱등한 메시지를 설계하는 것과 이벤트를 기록하고 이미 처리된 이벤트는 재처리하지 않도록 하는 방식입니다.
지금부터는 코드로 작성해보겠습니다.
👀 Read-Service - Producer 만들기!
Read-Service는 아래와 같이 구성됩니다.
예제를 간단히 하기 위해서, 메시지를 보내는 서비스(Producer) -> 메시지를 받는 서비스(Consumer)라고 하겠습니다.
먼저 Producer-Service 를 먼저 작업해보겠습니다.
build.gradle & application.yml 작성
먼저 build.gradle에 kafka 관련 셋팅을 작성해줍니다.
implementation 'org.springframework.kafka:spring-kafka'
testImplementation 'org.springframework.kafka:spring-kafka-test'application.yml에도 kafka 관련 property 값을 셋팅해줍니다.
spring:
kafka:
producer:
bootstrap-servers: 211.205.161.133:9092 # 현재 Kafka가 떠있는 서버
consumer:
bootstrap-servers: 211.205.161.133:9092 # 현재 Kafka가 떠있는 서버MSA 서비스 특성상 모든 서비스는 대부분의 경우에 Producer 이면서 Consumer 일 수 있습니다.
이 부분은 보상 트랜잭션(SAGA)을 구현할 때 서비스 간 어떻게 메시지를 주고 받는지에 따라 다를 수 있고, 이 부분은 다음에 다뤄보겠습니다.
Kafka-Producer 설정 클래스 작성
@EnableKafka // Kafka를 사용하기 위한 애너테이션
@Configuration
@RequiredArgsConstructor
public class KafkaSaveUserProducerConfig {
private final Environment environment;
/*
* Bean의 이름을 설정하는 이유 -> 메시지를 보낼때 데이터 저장, 수정 삭제 등 다양한 이유로 보낼 수 있기 때문에 타입으로 찾으면 겹칠 수 있음
*
* SaveUserKafkaDto 클래스 -> 메시지를 보낼때 데이터를 담을 객체를 제네릭 타입으로 넣어주면 됩니다.
* ㄴ> DefaultKafkaProducerFactory<String, 메시지를 보낼때 사용할 객체의 타입>
*/
@Bean(name = "saveUserDataProducerFactory")
DefaultKafkaProducerFactory<String, SaveUserKafkaDto> saveUserDataProducerFactory() {
return new DefaultKafkaProducerFactory<>(saveUserDataProducerConfig());
}
/*
* DefaultKafkaProducerFactory를 구성하기 위한 설정 정보를 담는 Map을 등록해주어야 합니다.
* -> 서버의 주소는 예제라서 간단하게 Environment 인터페이스에서 가져오는 방법을 선택했는데 ConfigurationProperty를 사용하는 것도 좋을 거 같습니다.
*/
@Bean(name = "saveUserDataProducerConfig")
Map<String, Object> saveUserDataProducerConfig() {
return Map.of(
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, environment.getProperty("spring.kafka.producer.bootstrap-servers"),
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class,
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class
);
}
/*
* Kafka로 메시지를 보낼 때 사용하는 KafkaTemplate 설정입니다.
* -> 메시지를 보낼 때 사용할 객체를 KafkaTemplate<String, 메시지를 보낼 때 사용할 타입>으로 선언해주면 됩니다.
*/
@Bean(name = "saveUserKafkaTemplate")
KafkaTemplate<String, SaveUserKafkaDto> saveUserKafkaTemplate() {
return new KafkaTemplate<>(saveUserDataProducerFactory());
}
}Event 발행 클래스 작성
Event 처리는 Spring에서 제공하는 ApplicationEventPublisher 인터페이스를 사용합니다.
Request 처리에 지장을 주지 않도록 이벤트에 대한 처리는 비동기 처리하도록 설정해주겠습니다.
@EnableAsync // 비동기 처리를 활성화 하기 위한 애너테이션
@SpringBootApplication
public class ExampleApplication {
public static void main(String[] args) {
SpringApplication.run(ExampleApplication.class, args);
}
}ApplicationEventPublisher가 하는 일은 이벤트를 발행하는 작업만 수행합니다.
따라서 모든 서비스 클래스가 ApplicationEventPublisher에 의존하는 것은 좋지 않으므로 Util 클래스로 분리했습니다.
public class EventProducer {
private static ApplicationEventPublisher eventPublisher;
public static void publishEvent(Object eventObject) {
eventPublisher.publishEvent(eventObject);
}
// ApplicationEventPublisher를 초기화해주는 메서드를 외부에서 호출해야 합니다.
public static void setEventPublisher(ApplicationEventPublisher applicationEventPublisher) {
eventPublisher = applicationEventPublisher;
}
}ApplicationEventPublisher를 초기화하는 setEventPublisher 메서드를 호출해야 EventProducer 사용이 가능합니다.
따라서 설정 클래스를 작성해서 ApplicationEventPublisher를 초기화 해주도록 하겠습니다.
@Configuration
public class ApplicationEventConfig {
/*
* ApplicationContext 인터페이스를 생성자로 주입받아서, EventProducer에 주입합니다.
* 설정 클래스 안에서 주입이 가능하기 때문에 InitializingBean 인터페이스를 등록하는 코드를 이용해
* EventProducer.setEventPublisher() 메서드를 호출했습니다.
*/
@Bean
InitializingBean initializingBean(ApplicationContext applicationContext) {
return () -> EventProducer.setEventPublisher(applicationContext);
}
}메시지 발행에 사용할 DTO 정의
먼저 DTO 정의 이전에 DB에 회원의 데이터를 저장할 때 필요한 User 엔티티와 BaseTimeEntity 엔티티를 작성하겠습니다.
// User.java
@Entity
@Getter @Builder
@AllArgsConstructor
@Table(name = "USERS")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class User extends BaseTimeEntity {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "USER_ID")
private Long id;
@Column(name = "USER_EMAIL")
private String userEmail;
@Column(name = "USER_NICKNAME")
private String userNickName;
}
// BaseTimeEntity.java
@Getter
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
abstract class BaseTimeEntity {
@CreatedDate
@Column(name = "REG_DATE")
private LocalDateTime regDate;
@LastModifiedDate
@Column(name = "MOD_DATE")
private LocalDateTime modDate;
}Kafka에 메시지를 전송할때는 두 개의 DTO를 합성한 DTO가 필요합니다.
예를 들어, User-Service에 새로운 회원이 저장되어서 회원이 저장되었다는 이벤트를 Read-Service에 전달해야 하는 경우를 예시로 들어보겠습니다.
먼저 회원의 정보를 담는 DTO와 이벤트를 발행하는 쪽에서 만든 이벤트의 정보를 담는 DTO가 필요합니다.
// 저장된 회원의 정보를 담는 DTO -> Read-Service의 User Entity와 Mapping 된다.
public record UserInfo(
Long userId,
String userEmail,
String userNickName,
LocalDateTime regDate,
LocalDateTime modDate
) {
}
// 발행된 이벤트 정보를 담는 DTO -> Read-Service의 UserEvent Entity와 Mapping 된다.
public record UserEventDto(
String eventUUID,
Long userId
) {
}UserInfo와 UserEvent를 포함하는 DTO를 만들어서 Kafka에 메시지를 보낼때 하나의 객체에 담아 보내야 합니다.
public record SaveUserKafkaDto(
UserInfo userInfo,
UserEventDto userEvent
) {
}그러면 이벤트는 이제 어떻게 발행하면 될까요?
이벤트 발행하기
일단 회원 한명을 저장하는 간단한 서비스 클래스를 작성해보겠습니다.
@Service
@Transactional
@RequiredArgsConstructor
public class SaveUserService implements SaveUserUseCase {
private final UserRepository userRepository;
@Override
public void saveUser() {
User user = User.builder()
.userEmail("mj.seo@uahannam.io")
.userNickName("Dev Rex Seo")
.build();
// 회원을 DB에 저장
userRepository.save(user);
// 이벤트 발행 -> Kafka 메시지 전달을 위해 Spring Event 발행
EventProducer.publishEvent(createKafkaDto(user));
}
/*
* 저장한 회원의 정보를 담는 DTO를 만듭니다.
* -> Read-Service에서도 같은 데이터를 받아야 데이터 정합성 유지가 가능하기 때문
*/
private SaveUserKafkaDto createKafkaDto(User user) {
UserInfo userInfo = new UserInfo(
user.getId(),
user.getUserEmail(),
user.getUserNickName(),
user.getRegDate(),
user.getModDate()
);
/*
* 이벤트를 발행하는 쪽에서 UUID를 이용해 이벤트 정보를 담는 DTO를 생성
*/
UserEventDto userEventDto = new UserEventDto(
UUID.randomUUID().toString(),
user.getId()
);
return new SaveUserKafkaDto(userInfo, userEventDto);
}
}이벤트를 발행하는 쪽에서 이벤트의 중복을 걸러주는 UUID를 담은 DTO 객체를 만들어야 하는 이유는 뭘까요?
이벤트를 발행하는 쪽에서 UUID를 생성하지 않고, Read-Service에서 UUID를 생성하면 매번 다른 UUID가 나올 것이므로 중복 이벤트 처리가 될 확률이 매우 높습니다.
Event를 발행하면 이 Event를 처리해주는 Listener가 필요합니다. 이제 클래스를 작성하겠습니다.
@TransactionalEventListener를 사용한 이유는 트랜잭션 실패와 이벤트 실패에 대하여 전부 재처리 비즈니스 로직을 작성하지 않도록, 트랜잭션 실패시 이벤트를 처리하지 않기 위함입니다.
@Component
@RequiredArgsConstructor
public class SaveUserDataEventListener {
// Bean으로 등록한 KafkaTemplate를 생성자 주입으로 받아줍니다.
private final KafkaTemplate<String, SaveUserKafkaDto> saveUserKafkaTemplate;
@Async // 이벤트를 비동기 처리하기 위한 애너테이션
@TransactionalEventListener(SaveUserKafkaDto.class) // 이벤트를 발행할때 사용한 Object의 타입을 적어줍니다.
public void handleSaveEvent(SaveUserKafkaDto saveUserKafkaDto) {
// Kafka-Topic의 이름과 메시지 전송에 이용할 객체를 넣어줍니다.
saveUserKafkaTemplate.send("save-user-data", saveUserKafkaDto);
}
}이 과정까지 마치면 Producer의 설정과 구현은 모두 완료되었습니다.
이제 Consumer만 간단히 작성하면 Read-Service 구축이 전부 끝납니다!

😁 Read-Service - Consumer 만들기!
build.gradle & application.yml 파일 작성
implementation 'org.springframework.kafka:spring-kafka'
testImplementation 'org.springframework.kafka:spring-kafka-test'spring:
kafka:
consumer:
bootstrap-servers: 211.205.161.133:9092
producer:
bootstrap-servers: 211.205.161.133:9092Kakfa-Consumer 설정 클래스 작성
Kafka-Consumer 역할을 하기 위한 Consumer-Service의 설정 클래스를 작성하겠습니다.
@EnableKafka // Kafka 활성화를 위해 필요한 애너테이션
@Configuration
@RequiredArgsConstructor
public class KafkaSaveUserListenerConfig {
private final Environment environment;
/*
* Bean 이름을 등록하는 이유는, 여러 개의 Consumer 설정이 필요할 때 타입으로 구분하면 충돌이 일어날 수 있기 때문입니다.
* -> ConcurrentKafkaListenerContainerFactory<String, 메시지를 받을 타입(보낸 타입과 내용이 일치해야 한다)>로 선언합니다.
*/
@Bean(name = "saveUserDataKafkaListenerContainerFactory")
ConcurrentKafkaListenerContainerFactory<String, SaveUserKafkaDto> saveUserDataKafkaListenerContainerFactory() {
// Producer-Service에서 사용한 SaveUserKafkaDto를 선언해서 같이 사용합니다 -> 필드와 구성요소가 같아야 역직렬화시 문제가 생기지 않는다.
ConcurrentKafkaListenerContainerFactory<String, SaveUserKafkaDto> concurrentKafkaFactory =
new ConcurrentKafkaListenerContainerFactory<>();
concurrentKafkaFactory.setConsumerFactory(saveUserDataKafkaListenerConsumerFactory());
return concurrentKafkaFactory;
}
@Bean(name = "saveUserDataKafkaListenerConsumerFactory")
ConsumerFactory<String, SaveUserKafkaDto> saveUserDataKafkaListenerConsumerFactory() {
// JsonDeserializer 생성시 Kafka Header를 사용하지 않도록 설정했습니다 -> 헤더 사용시 Package 정보를 가져와서 클래스를 찾지 못한다는 에러를 발생시킵니다.
JsonDeserializer<SaveUserKafkaDto> deserializer = new JsonDeserializer<>(SaveUserKafkaDto.class, false);
Map<String, Object> saveUserDataConsumerConfig = Map.of(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, environment.getProperty("spring.kafka.producer.bootstrap-servers"), // Kafka 서버의 주소를 받아옵니다.
ConsumerConfig.GROUP_ID_CONFIG, "save-user-data", // kafka group-id를 설정합니다.
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class,
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, deserializer,
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest"
);
return new DefaultKafkaConsumerFactory<>(saveUserDataConsumerConfig, new StringDeserializer(), deserializer);
}
}Consumer-Service 엔티티 정의하기
Consumer-Service에서 사용할 세 개의 엔티티를 정의하겠습니다.
// BaseTimeEntity.java
@Getter
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
abstract class BaseTimeEntity {
@CreatedDate
@Column(name = "READ_MODEL_REG_DATE")
private LocalDateTime readModelRegDate;
@LastModifiedDate
@Column(name = "READ_MODEL_MOD_DATE")
private LocalDateTime readModelModDate;
}
// User.java
@Entity
@Getter @Builder
@AllArgsConstructor
@Table(name = "USERS")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class User extends BaseTimeEntity
implements Persistable<Long> {
@Id
@Column(name = "USER_ID")
private Long id;
@Column(name = "USER_EMAIL")
private String userEmail;
@Column(name = "USER_NICKNAME")
private String userNickName;
@Column(name = "USER_REG_DATE")
private LocalDateTime userRegDate;
@Column(name = "USER_MOD_DATE")
private LocalDateTime userModDate;
@Override
public boolean isNew() {
return getReadModelRegDate() == null;
}
}
// UserEvent.java
@Entity
@Getter @Builder
@AllArgsConstructor
@Table(name = "USER_EVENT")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class UserEvent extends BaseTimeEntity {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "USER_EVENT_ID")
private Long userEventId;
@Column(name = "USER_EVENT_UUID")
private String eventUUID;
@Column(name = "USER_ID")
private Long userId;
}User에도 데이터 저장/수정 시간이 있고, 왜 BaseTimeEntity를 따로 두는지와 Persistable 인터페이스를 왜 구현했는지는
제 블로그에 정리된 글을 봐주시면 감사하겠습니다.
이제 서비스 클래스를 작성하겠습니다.
@Service
@Transactional
@RequiredArgsConstructor
public class SaveUserService implements SaveUserUseCase {
private final UserRepository userRepository;
private final UserEventRepository userEventRepository;
@Override
public void saveUserData(SaveUserKafkaDto saveUserKafkaDto) {
// 동일한 UUID를 가진 이벤트 데이터가 있는지 조회합니다.
Optional<UserEvent> findEvent = userEventRepository.findByEventUUID(saveUserKafkaDto.userEvent().eventUUID());
// 이벤트 중복 처리를 하지 않으려면, 메시지에 담긴 EventUUID는 처음 저장되는 것이어야 합니다.
if (findEvent.isEmpty()) {
userRepository.save(saveUserKafkaDto.mapToUserEntity());
userEventRepository.save(saveUserKafkaDto.mapToUserEventEntity());
}
}
}Producer-Service에서는 Kafka 메시지를 발송할 때, Event-UUID를 생성해서 보내옵니다.
Consumer-Service에서는 Event-UUID를 기준으로 이벤트 처리 여부를 판단하게 되는 것입니다.
이제 마지막으로 Consumer에서 Kafka 메시지를 소비하는 Listener 클래스를 작성하겠습니다.
Kafka-Listener 클래스 작성
@Component
@RequiredArgsConstructor
public class SaveUserDataListener {
private final SaveUserUseCase saveUserUseCase;
/*
* Kafka 메시지를 소비하는 메서드를 정의하려면 @KafkaListener 애너테이션을 이용해 정의할 수 있습니다.
* 애너테이션에는 메시지를 받을 토픽의 이름들과, group-id, 설정 클래스에서 작성한 containerFactory의 Bean 이름을 제공하면 됩니다.
*/
@KafkaListener(topics = "save-user-data", groupId = "save-user-data", containerFactory = "saveUserDataKafkaListenerContainerFactory")
void consumeUserData(@Payload SaveUserKafkaDto userKafkaDto) {
saveUserUseCase.saveUserData(userKafkaDto);
}
}🥷 다음으로..
중간 중간 글이 너무 길어질까봐 따로 언급하지 않은 부분도 많고,
코드가 몇 군데 빠져있거나 중요하다고 생각하지 않은 부분은 상세히 다루지 않았던 것 같습니다.
혹시 코드가 필요하시거나 이해가 어려우신 분들을 위해,
Producer와 Consumer Service Repository 링크를 남겨둡니다.
Producer-Service
https://github.com/ua-hannam/kafka-producer-exampleConsumer-Service
https://github.com/ua-hannam/kafka-consumer-example
MSA에서 서비스가 독립적인 데이터베이스를 사용하기 때문에, 복잡한 Join을 어떻게 풀어내야 할지 고민이 되었는데
CQRS를 적용해서 Read-Model을 사용하니 이런 문제가 해결되었습니다.
MSA를 사용하면 장애 전파가 되지 않고 독립적인 개발 & 배포 등의 장점도 많이 존재하지만
시스템 복잡도가 증가하고 데이터 정합성 관리와 비동기 메시징 기능 개발 등 추가적인 오버헤드도 많이 발생하는 것 같습니다.
이런 모든 것을 고려해서 현재 비즈니스 상황에 맞는 기술을 선택하는 것이 개발자로서 중요한 역량임을 느끼는 프로젝트였던 것 같습니다.
오늘도 읽어주셔서 감사합니다.

이 분이 글을 잘쓰시네...