파일 시스템 vs DBMS
-
파일 = 순차적인 레코드들로 이루어져 있음.
-
레코드 = 연관된 필드들의 모임 ( class ? )
-
파일을 접근하는 방식이 응용 프로그램 내에 상세하게 표현
=> 데이터에 대한 응용 프로그램의 의존도가 높다.어플리케이션 코드 내에서
파일을 사용하려면?1) 파일 객체
2) readline()으로 가져옴.
3) 레코드 별로 split
4) 거기서 내가 원하는 자료를 찾아야 함.=> 파일이 변경 시, 응용 프로그램 또한 변경이 되어야 함.
=> 응용 프로그램에서 클래스의 설계가 바뀌면, 파일의 내용이 바뀌어야 함.
응용프로그램과 파일의 의존성, 결합도가 높다. ( 단점 1 )
내 정보 ( 회사원 레코드 )가 여러 곳에서 참조하고 있다면,
내가 승진을 해서 '직급' 값이 바뀌게 되면
나를 참조하는 모든 파일의 정보가 바뀌어야 함.
만약 바뀌지 않으면, 데이터의 불일치 발생. 데이터의 무결성이 깨진다.
물론 파일이 여러개이기에, 데이터 불일치도 발생함.
<단점 3>
-
다수 사용자들을 위한 동시성 제어가 제공되지 않음 ( 파일이 열려있을 때, 접근하려 하면 이미 열려있는 파일이라 이야기 나옴 )
-
검색하려는 데이털르 쉽게 명시하는 질의어가 제공되지 않는다.
-
보안 x
-
회복 기능 x
-
프로그램-데이터의 독립성이 없고, 의존적이니 유지보수 비용이 많이 소요된다.
-
파일을 검색하거나 갱신하는 절차가 상대적으로 복잡함. -> 프로그래머의 생산성이 낮음.
-
데이터 공유와 융통성이 부족

DBMS 종류
- RDB : Oracle, mariaDB, MSSQL, MySQL, PostgreSQL
- NoSQL : MongoDB, HBase
DBMS 선정 시 고려 사항
- 기술적 요인
- DBMS에 사용되고 있는 데이터 모델, DBMS가 지원하는 사용자 I/F, 프로그래밍 언어, 응용 개발 도구, 저장 구조, 성능, 접근 방법
- 경제적 요인
- 소프트웨어와 하드웨어 구입 비용, 유지보수 이용, 직원 교육 비용
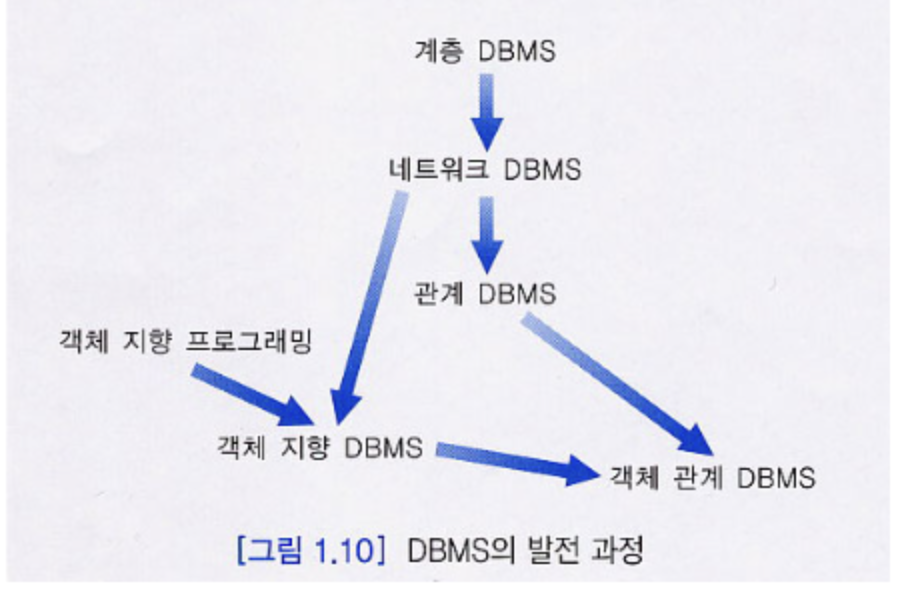
DBMS 발전 과정
- 데이터 모델
=> 데이터 구조를 기술하는데 사용되는 개념들의 집합인 구조( Data Type + 관계 )
& 이 구조 위에서 동작하는 연산자들, 무결성 제약조건들의 합.
=> 사용자에게 내부 저장 방식의 세세한 사항은 숨기면서,
데이터에 대한 직관적인 뷰를 제공하는 동시에, 이들 간의 사상을 제공한다.
데이터 모델의 분류
- 고수준 또는 개념적 데이터 모델 ( conceptual data model )
- 사람이 인식하는 것과 유사하게 데이터베이스의 전체적인 논리적 구조 명시- 엔티티-관계(ER) 데이터 모델, 객체지향 데이터 모델
- 표현(구현) 데이터 모델(representation(implementation) data model)
- 최종 사용자가 이해하는 개념이면서, 컴퓨터 내에서 데이터가 조직죄든 방식과 멀리 떨어져 있지는 않음.-
계층 데이터 모델(hierarchical data model), 네트워크 데이터 모델(network data model )
-
계층형 DBMS의 문제
-> OneToMany는 잘 표현, But, ManyToMany는 표현 불가능 ( 중복이 발생함 )
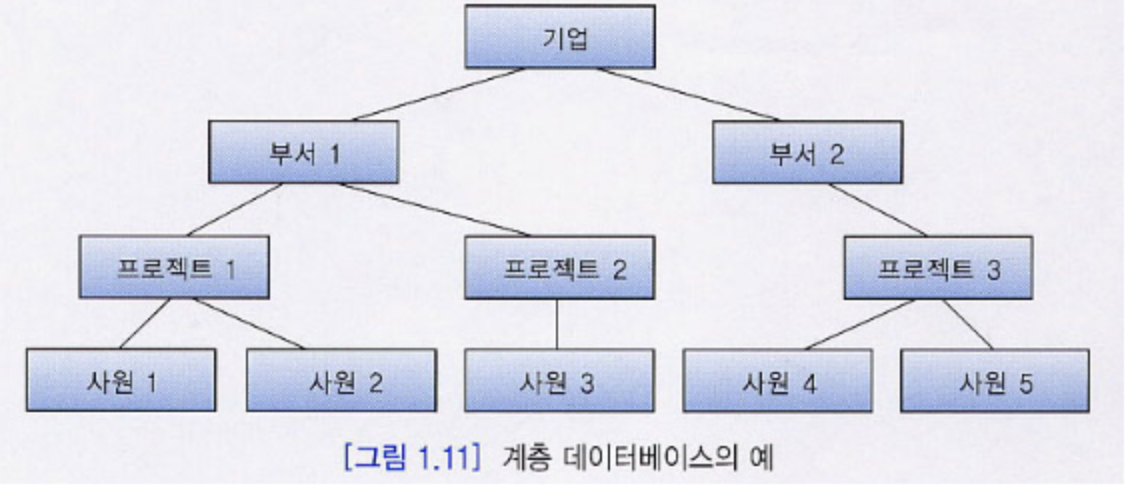
ex. 한 사원이 여러개의 프로젝트를 한다면?
Tree vs Graph
- Graph 는 Cycle 이 존재한다.
네트워크 DBMS
- 하나의 직원이 여러개의 프로젝트 참여, . . .
ManyToMany 를 구현해서 보여줄 수 있게 되었다.
관계 DBMS
- 사용자는 자신이 원하는 것(what)만 명시하고, 데이터가 어디에 있는지, 어떻게 접근해야하는지에 대한 기능은 DBMS가 결정 ( = 추상화, 책임의 분리 )
ex. 오라클, MS SQL Server, Sybase, DB2, Informix
@객체 관계 DBMS
- 관계 DBMS에 객체 지향 개념을 통합한 객체 관계 데이터 모델
- 우리가 지금 사용하는 RDB 가 객체-관계 DBMS 라고 할 수 있다.

파일 시스템에서는,
파일 내용을 저장해준다는 것 빼고는 아무것도 없었다.
DBMS가 발전해오면서,
개발자가 직접 프로그래밍 해야하는 분량이 내려가고,
DBMS가 처리해주는 분량이 늘었다.
ex. 나이 column 에 90000을 넣으면, DBMS 자체가 제약조건을 생각해서 cut해버림.

중앙 집중식 DBMS vs 분산 DBMS
DBMS 언어
1) 데이터 정의어 ( DDL : Data Definition Language )
-
사용자는 데이터 정의어를 사용하여 데이터베이스 스키마를 정의
-
데이터 정의어로 명시된 문장이 입력되면, DBMS는 사용자가 정의한 스키마에 대한 명세를 시스템 카탈로그 또는 데이터 사전에 저장.
-
데이터 모델에서 지원하는 데이터 구조를 생성
( SQL - CREATE TABLE ) -
데이터 구조의 변경
( SQL - ALTER TABLE ) -
데이터 구조의 삭제
( SQL - DROP TABLE )
2) 데이터 조작어 ( DML : Data Management Language)
-
사용자는 데이터 조작어를 사용해서, 데이터베이스 내의 원하는 데이터를 검색하고, 수정하고, 삽입하고 삭제
-
절차적 언어( Procedural Language )와 비절차적 언어( Non-Procedural Language )
-
관계 DBMS에서 사용되는 SQL은 대표적인 비절차적 언어
-
비절차적 언어 ( 내가 뭘 찾을지 표현만 한다. )
절차적 언어? = 내가 DBMS 가 돌아가는 로직을 알아야 한다.
데이터베이스 스키마 = 저장되는 데이터 구조를 설명한다.
데이터 제어어(DCL : Data Control Language)
- 데이터 제어어를 사용해서, 데이터베이스 트랜잭션을 명시하고, 권한을 부여하거나 취소
