배웠던 핵심 내용을 떠올리기 위한 기록으로 글을 작성합니다.
Data Integrity
FK는 다른 테이블의 PK를 가져오는 것이다.
관계를 형성할 때 사용한다.
각 테이블에서의 컬럼 이름이 달라도 상관이 없다.
FK는 중복이 될 수 있다. ( 1:N 관계 )
참조 무결성 제약조건
- 외래 키는 다른 테이블의 기본 키(PK)이다.
NULL VALUE
- ‘알려지지 않음’, ‘적용할 수 없음’
- NULL은 어떤 연산을 해도 NULL ( ≠
**BLANK**,**BLANK**는 ASCII 코드 값이 부여되어 있음 )
Oracle Type Casting
- to_date
- to_char
- to_number
ORDER BY가 가능한 자료형에 대해서는 부등호 연산이 항상 가능하다.
ALIAS를 통해 정렬할 수 있다.
SELECT SAL * 12 as ANNUAL_SALARY
FROM emp
ORDER BY ANNUAL_SALARY asc;
WHERE 절에서 원본 컬럼에 변형을 가하지 말자!
WHERE 절에서 LIKE를 가능한 쓰지 말자! ( = 19g 부터는 ‘A%’ 라면, A까지는 인덱스를 탄다, 하지만 그 이후에 자료들은 인덱스를 타지 않는다. Full-Scan )
- 인덱스를 타지 않는다.
- Full-Scan을 탐. ( Traffic, 데이터 량 많음. 엄청 오래 걸림 )
JOIN
- 여러 개의 테이블로부터 원하는 데이터들을 뽑아오는 문법
- FROM절에 테이블이 2개다.
- JOIN된 테이블은 2개 ~ 무한개가 될 수 있다.
Cartesian Product (합성곱)
-- ( 카티션 곱 ) : Cartesian Product / 합성곱, 모든 경우의 수
select e.ename, d.deptno
from emp e, dept d;
-- Cartesian Product + WHERE 절로 조건 ( = JOIN )
select e.ename, d.deptno
from emp e, dept d
where e.deptno = d.deptno;
Join의 종류 ( 오라클에서의 용어 )
- Equi Join
- Non-Equi Join
- Outer Join
- Self Join
동등 조인과 Outer Join의 차이 ( 왜 Outer Join이 필요한가 )
- 게시글 테이블, 댓글 테이블이 있고 두 테이블을 연관지어 정보를 보여줘야할 때
- Equi Join은 게시글에 댓글이 없으면, 해당 게시글이 쿼리 결과에 포함되지 않는다.- 게시글을 썼는데, 댓글이 없어서 내가 쓴 게시글이 안나오는 상황을 생각해볼 수 있다.
- Outer Join은 게시글에 댓글이 없으면, 댓글 부분을 NULL로 처리해서라도 보여줄 수 있다.
Oracle 전용 Outer Join 문법 vs ANSI SQL Join 문법
- Oracle은 ANSI의 표준을 지원하면서도, 자신만의 Outer Join 문법을 가진다.
- 즉, ANSI SQL을 통해 모든 DBMS에 질의를 날릴 수 있지만, 특별히 Oracle 에서만 가능한 SQL 문법이 있는 것이다.
- Oracle은 ANSI의 인터페이스를 따르면서, 좀 더 확장된 기능을 제공해주는 그런 관계라 생각하면 되겠다.
Oracle 전용 SQL
SELECT e.ename, d.deptno
FROM emp e, dept d
where e.deptno(+) = d.deptno;
SELECT d.deptno, e.ename
FROM emp e, dept d
where d.deptno = e.deptno(+);
-- Outer Join (+) 연산자. 부족한 쪽에 (+) 로 채워줌.
-- 주의주의 :: e.deptno --> null 출력, d.deptno (정답)
SELECT e.ename, e.deptno, d.deptno
FROM emp e, dept d
where e.deptno(+) = d.deptno;ANSI 표준 SQL
-- ANSI 표준 SQL OUTER JOIN
-- LEFT/RIGHT OUTER JOIN
SELECT
e.ename,
d.deptno
FROM dept d
LEFT OUTER JOIN emp e ON d.deptno = e.deptno;SELF JOIN을 왜 사용하는가?
- 한 테이블에서 스스로의 테이블 정보를 참조해서 정보를 추출해야할 때
- 말이 어려우니 예시로 기억하자,
사원 테이블인 EMP(id, mgr_id, employee_name) 로 이루어져있을 때,
'특정 사원의 매니저의 이름을 알고싶은 경우' EMP 테이블의 mgr_id와 또다시 EMP 테이블의 id를 참조해야한다. - 이러한 경우에 셀프 조인을 사용한다.
-- SELF JOIN
SELECT
e.empno as EMPLOYEE_NO,
e.ename as EMPLOYEE_NAME,
m.empno as MANAGER_NO,
m.ename as MANAGER_NAME
FROM
EMP e,
EMP m
WHERE
e.mgr = m.empno;
-- 매니저가 없는 경우도 출력하기 ( 없는 경우 )
SELECT
e.empno as EMPLOYEE_NO,
e.ename as EMPLOYEE_NAME,
COALESCE(m.empno, -1) as MANAGER_NO,
COALESCE(m.ename, 'NOT EXIST') as MANAGER_NAME
FROM
EMP e
LEFT OUTER JOIN
EMP m
ON
e.mgr = m.empno;3개 이상의 테이블에서도 조인이 가능하다.
-- JOIN WITH MORE THAN 2 TABLES
SELECT
c.name as cname,
c.custid as cid,
o.ordid as oid,
i.itemid as iid
FROM
CUSTOMER c
INNER JOIN
ORD o
ON
c.custid = o.custid
INNER JOIN
ITEM i
ON
c.ordId = i.ordid;
-- FROM 에 3개 테이블
SELECT
c.name as cname,
c.custid as cid,
o.ordid as oid,
i.itemid as iid
FROM
CUSTOMER c, ORD o, ITEM i
WHERE
c.custid = o.custid
AND
o.ordid = i.ordid;비동등조인 (Non-Equi Join)
- 부등호 연산을 통해 Join절을 조건을 줄 수 있다.
- 고객 등급 계산 등의 SQL에서 사용할 수 있다.
-- Non-Equi Join ( where 절에 < , >, <=, >= 를 활용한 JOIN )
-- Cartesian Product 이후, WHERE 절로 자르기
SELECT
e.empno as empno,
e.ename as ename,
e.sal as salary,
sg.grade as grade,
sg.losal as lowsal,
sg.hisal as hisal
FROM
EMP e, SALGRADE sg
WHERE
e.sal >= sg.losal
AND
e.sal <= sg.hisal;Group Function
- 총 7개 존재하지만, 그룹에 대한 분산/표준편차를 구하는 VARIANCE, STDDVE 는 잘 사용하지 않는다.
- SUM(컬럼) : 총합
- AVG(컬럼) : 평균
- MIN(컬럼) : 최소값
- MAX(컬럼) : 최대값
- COUNT(컬럼), COUNT(*), COUNT(1) : 개수
- 단, 이 세가지는 결과가 다르다.
-- AVG, MAX, MIN, SUM
-- 10번 부서 사람들의 평균, 최대, 최소, 총합 급여
SELECT
ROUND(AVG(SAL),1) as avgSal,
MAX(SAL) as maxSal,
MIN(SAL) as minSal,
SUM(SAL) as sumSal
FROM
EMP
WHERE
DEPTNO = 10;
-- GROUP BY DEPTNO
SELECT
DEPTNO,
ROUND(AVG(SAL),1) as avgSal,
MAX(SAL) as maxSal,
MIN(SAL) as minSal,
SUM(SAL) as sumSal
FROM
EMP
GROUP BY
DEPTNO
ORDER BY
DEPTNO ASC;
SELECT SUM(SAL) as s_sal
FROM EMP;
SELECT
deptno,
SUM(sal) as s_sal
FROM
emp
GROUP BY
deptno
ORDER BY
s_sal DESC;GROUP BY
- 특정 컬럼을 기준으로 그룹화한다.
- 중복 제거 용도로도 쓸 수 있다.
보통 UNIQUE하게 뽑는 방법은 일반적으로 이렇게 나눌 수 있다.
( DISTINCT도 여러 컬럼에 대한 유니크한 튜플을 뽑을 수 있다.
일반적으로 GROUP BY를 사용하는 것 )
- 단일 컬럼에 대해 UNIQUE하게 뽑는다 → DISTINCT 사용!
여러 컬럼에 대한 UNIQUE하게 뽑는다 → GROUP BY를 사용!
SELECT
DISTINCT deptno
FROM
emp;
-- DISTINCT 와 같은 문법
SELECT
deptno
FROM
emp
GROUP BY
deptno;그룹 함수 사용 시 가장 중요한 개념 두가지
- SELECT 에서 사용한 일반 컬럼을 GROUP BY에 넣지 않으면 에러가 난다.
- Oracle에서는 ORA-00937 : Not a single-group group function 이라는 에러가 나온다.
- SELECT 에서 사용한 일반 컬럼을 GROUP BY에 넣지 않으면 에러가 난다.
- 그룹 함수는 WHERE에 오지 못한다. 그룹에 대한 조건은 HAVING으로 적용해야만 한다.
- 2-1. HAVING에는 그룹함수가 올 수도 있고, 안올 수도 있다.
-- ORA-00937 : Not a single-group group function
-- SELECT에서 사용한 일반 컬럼을 GROUP BY에 넣지 않으면 937에러가 난다.
SELECT
DEPTNO,
ROUND(AVG(SAL),1) as avgSal,
MAX(SAL) as maxSal,
MIN(SAL) as minSal,
SUM(SAL) as sumSal
FROM
EMP
--GROUP BY
-- DEPTNO
ORDER BY
DEPTNO ASC;
-- 평균 급여가 2000 이상인 부서만 출력 (★)
-- ORA-00934 : GROUP FUNCTION is not allowed here.
-- 2. 그룹 함수는 WHERE자리에 오지 못한다.
-- 그룹에 대한 조건은 HAVING 으로 적용한다!
SELECT
DEPTNO,
AVG(SAL)
FROM
EMP e
GROUP BY
DEPTNO
HAVING
AVG(SAL) >= 2000;
-- HAVING에 그룹함수가 아닌 조건을 넣어도 될까? -> OK
SELECT
~~
FROM
MEM
GROUP BY
지역
HAVING
지역 IN ('서울', '경기')COUNT(칼럼), COUNT(*), COUNT(1)
- COUNT(칼럼)
NULL을 없는 취급해서 센다.- COUNT를 포함한 모든 그룹 함수는
NULL을 취급하지 않는다.
SELECT
COUNT(COMM),
COUNT(1),
COUNT(*)
FROM
EMP;- COUNT(1), COUNT(*)
- COUNT(1)
- 주요 레코드를 가지고 센다. ( PK였다면, COUNT(PK) 로 하면 되었을 것 )
- ROW_ID 또는 ROWNUM을 가지고 센다.
- 레코드의 고유 카운팅을 해달라.
- COUNT(1)
SELECT
ROWID,
ROWNUM,
EMPNO,
ENAME
FROM
EMP;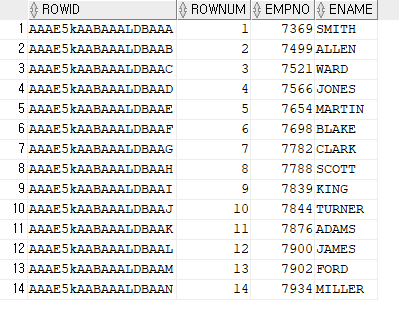
- ROWID, ROWNUM 이 둘 다 오라클이 내부적으로 관리하는 컬럼이다.
- 이 컬럼의 내용을 통해 해당 테이블에 튜플이 어떤 순서로 들어왔는지 추적 가능하다.
- 튜플마다 고유한 값이기에, 이 값을 통해 NULL 값을 포함한 칼럼의 개수를 셀 수 있다.
-- NULL인 컬럼이 있는지 없는지 확인할 수 있는 쿼리
SELECT
COUNT(COMM),
COUNT(1)
FROM
EMP;
-- 이것도 가능
SELECT
*
FROM
EMP
WHERE
COMM IS NULL;NVL
- NULL 값이 나왔을 때, 대체값으로 표시해줄 수 있다.
- 비슷한 문법으로 COALESCE가 있다.
-- AVG -> 그룹함수로, NULL값을 무시함.
SELECT
COMM,
AVG(COMM)
FROM
EMP;
-- NVL을 통해 NULL을 0으로 대체 후 AVG 계산
SELECT
AVG(NVL(COMM,0))
FROM
EMP;ORDER BY에 그룹함수가 올 수 있다.
- ORDER BY는 일단 테이블 다 뽑고 나서,
해당 테이블을 컬럼 이름 중 하나로 정렬하는 것.
ORDER BY를 쓸 때는, WHERE 절로 거를만큼 거르자
-- 2. 그룹에 대한 조건을 준다. ( HAVING -> GROUP BY에 대한 조건을 주는 것 )
SELECT
JOB,
AVG(SAL) as avgsal
FROM
EMP
GROUP BY
JOB
HAVING
JOB IN ('CLERK', 'SALESMAN');
-- 3. 2와 결과는 동일, 근데 더 효율적 ( 트래픽을 덜 잡아먹는다 )
SELECT
JOB,
AVG(SAL) as avgsal
FROM
EMP
WHERE
JOB IN ('CLERK', 'SALESMAN')
GROUP BY
JOB;그룹함수를 중첩할 수 있다.
-- 각 부서별 평균급여 중 최대평균급여 출력
SELECT
MAX(AVG(SAL))
FROM
EMP
GROUP BY
DEPTNO;서브쿼리의 필요성
-- 각 부서별 평균급여 중 최대평균급여 출력
-- 에러 937 에러
SELECT
DEPTNO,
MAX(AVG(SAL))
FROM
EMP
GROUP BY
DEPTNO;
-- 각 부서별 평균 급여 중, 최대 평균 급여인 부서
SELECT
DEPTNO
FROM
EMP
GROUP BY
DEPTNO
HAVING
AVG(SAL) = (
SELECT
MAX(AVG(SAL))
FROM
EMP
GROUP BY
DEPTNO
);
937 에러는 각 행이 다른 테이블을 한번에 보여주려할 때 나타나는 에러이다.- 이것때문에 필요한 것이 서브쿼리
-- 1. DALLAS에서 근무하는 사원의 이름, 직업, 부서번호, 부서이름을 출력.
SELECT
e.ename,
e.job,
e.deptno,
d.dname
FROM
EMP e
JOIN
DEPT d
ON
e.deptno = d.deptno
WHERE
d.loc = 'DALLAS';
-- 2. 직업이 'SALESMAN'인 사원들의 직업과 그 사원이름, 부서 이름을 출력하라.
SELECT
e.JOB,
e.ENAME,
d.DNAME
FROM
EMP e
JOIN
DEPT d
ON
e.deptno = d.deptno
WHERE
e.JOB = 'SALESMAN';
-- 부서번호가 10, 20번인 사원들의
-- 부서번호, 부서이름, 사원이름, 급여를 출력
-- 부서번호가 낮은 순, 급여가 높은 순으로 출력
SELECT
d.deptno,
d.dname,
e.ename,
e.sal
FROM
DEPT d
JOIN
EMP e
ON
d.deptno = e.deptno
WHERE
d.deptno in (10,20)
ORDER BY
d.deptno ASC, e.sal DESC;
-- EMP 테이블의 모든 사원번호, 사원명, 매니저번호, 매니저명을 출력하라.
SELECT
e.empno,
e.ename,
e.mgr as mgr_no,
m.ename as mgr_name
FROM
EMP e
JOIN
EMP m
ON
e.mgr = m.empno;
-- EMP 테이블에서 부서 인원이 4명보다 많은 부서의 부서번호, 인원수, 급여의 합을 출력하시오.
SELECT
deptno,
count(empno) as pcount,
sum(sal) as whole_sal
FROM
EMP
GROUP BY
deptno
HAVING
count(empno) > 4;