[알고리즘] 순차 탐색(Sequential Search)와 이진 탐색(Binary Search), 이진 탐색 트리

개념과 코드는 해당 책을 참고하였습니다.
이진 탐색 알고리즘은 리스트 내에서 데이터를 매우 빠르게 탐색하는 알고리즘입니다. 이진 탐색에 대해 알기 전, 순차 탐색에 대해 이해를 하고 넘어가면 개념을 이해하기에 더 좋습니다.
순차 탐색(Sequential Search)
순차 탐색의 원리는 데이터 N개가 있을 때, 그 데이터를 차례대로 확인하여 어떠한 처리를 해주는 경우 그 자체로 설명할 수 있습니다.
정리하자면,
순차 탐색(Sequential Search)이란 리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 차례대로 확인하는 방법입니다.
보통 정렬되지 않은 리스트에서 데이터를 찾아야 할 때 사용되며, 리스트 내에 많은 데이터가 있어도 시간만 충분하다면 항상 원하는 데이터를 찾아낼 수 있습니다.
순차 탐색을 파이썬 코드로 작성해 보겠습니다.
# 순차 탐색 소스코드 구현
def sequential_search(n, target, array):
# 각 원소를 하나씩 확인
for i in range(n):
# 현재의 원소가 찾고자 하는 원소와 동일한 경우
if array[i] == target:
return i + 1 # 현재의 위치 반환(인덱스는 0부터 시작하므로 1을 더한다.)
print('생성할 원소 개수를 입력한 뒤, 한 칸 띄고 찾을 문자열을 입력하시오.')
input_data = input().split()
n = int(input_data[0]) # 원소의 개수
target = input_data[1] # 찾고자 하는 문자열
print('앞서 적은 원소 개수만큼 문자열을 입력하세요. 구분은 띄어쓰기 한 칸으로 합니다.')
array = input.split()
# 순차 탐색 수행 결과 출력
print(sequential_search(n, target, array))생성할 원소 개수를 입력한 뒤, 한 칸 띄고 찾을 문자열을 입력하시오.
5 chasuyeon
앞서 적은 원소 개수만큼 문자열을 입력하세요. 구분은 띄어쓰기 한 칸으로 합니다.
apple banana chasuyeon dog elephant
3소스코드를 실행하면 제가 입력한 문자열이 몇 번째 데이터인지 출력값을 통해 알 수 있습니다. 이처럼 순차탐색은 데이터 정렬 여부와 상관없이 가장 앞에 있는 원소부터 하나씩 확인한다는 점이 특징입니다.
따라서 데이터 개수가 N개라면? 최대 N번의 비교 연산이 필요합니다. 그러므로 순차 탐색의 최악의 경우 시간 복잡도는 O(N)이 됩니다.
이진 탐색(Binary Search)
이진 탐색(Binary Search)은 배열 내부의 데이터가 정렬되어 있어야만 사용할 수 있는 알고리즘입니다.
데이터가 무작위일 때는 사용할 수 없지만, 이미 정렬되어 있다면 매우 빠르게 데이터를 찾을 수 있다는 탁징이 있습니다.
이진 탐색은 탐색 범위를 반으로 좁혀가며 데이터를 탐색합니다.
이진 탐색을 설명하기 위해 3가지 변수가 필요합니다.
시작점, 끝점, 중간점
찾으려는 데이터와 중간점(Middle) 위치에 있는 데이터를 반복적으로 비교하여 원하는 데이터를 찾는 것이 이진 탐색 과정입니다.
1단계
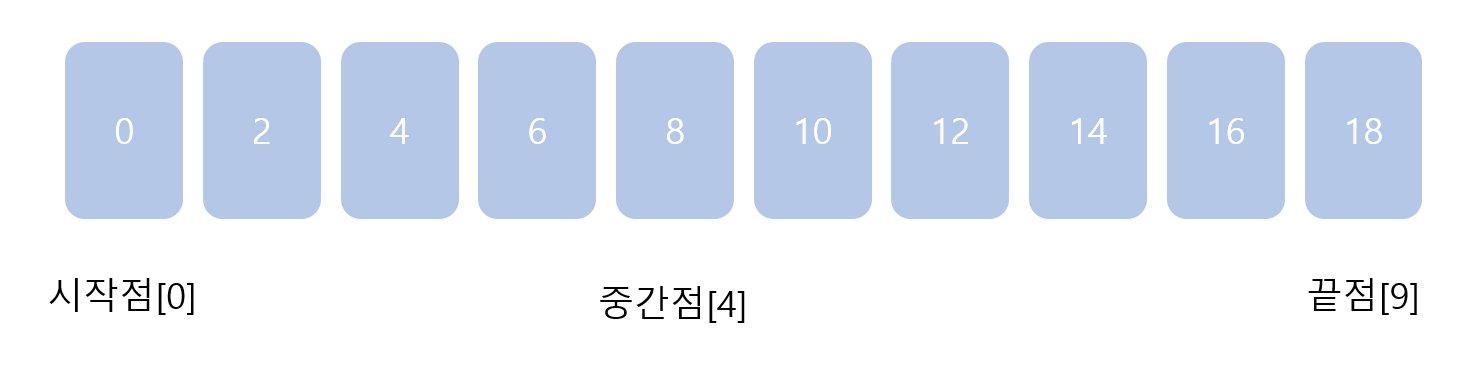
0부터 18까지 짝수로만 이루어진 10개의 정렬 데이터가 있습니다. 그리고 여기서 찾으려는 값은 4인 원소입니다.
0이 시작점, 8이 중간점, 18이 끝점이 됩니다. 중간점은 끝점 인덱스 9에서 2를 나누고 소수점을 버린 값입니다.
하지만 중간점은 8이어서 찾는 원소의 값보다 큽니다. 중간점보다 큰값은 이제 탐색이 필요없어집니다.
따라서 끝점을 [4]에서 [3]으로 옮깁니다.
2단계
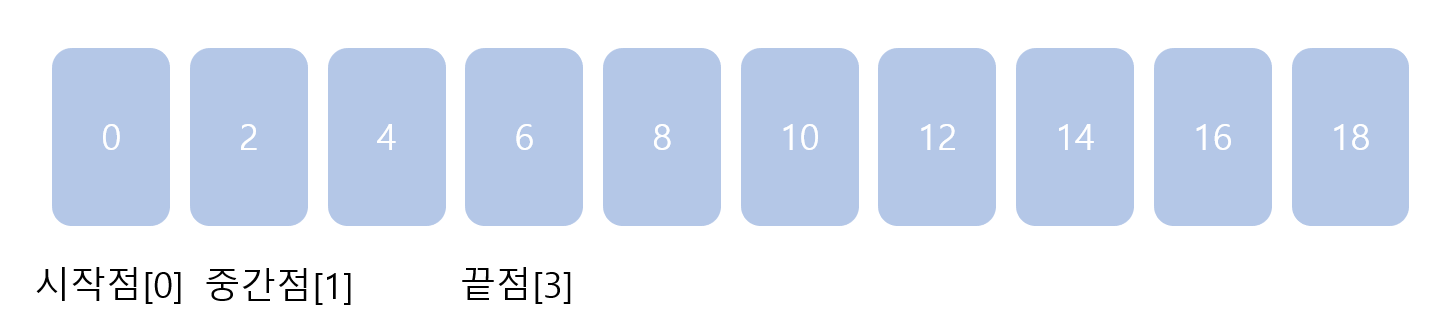
이제 끝점이 3으로 이동해서 값이 6으로 변경되었고, 중간점은 2가 되었습니다.
찾으려는 원소 4는 중간점 2보다 더 큽니다. 그러면 이제 2 이하인 값의 탐색은 필요 없어집니다.
따라서 시작점을 [2]로 변경합니다.
3단계
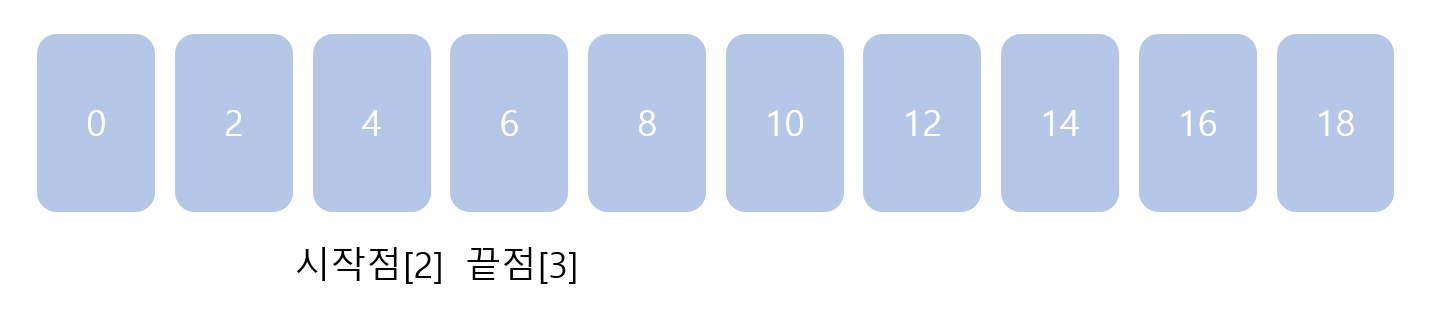
이제 중간점에 위치한 데이터 4는 찾으려는 데이터 4와 동일하므로 탐색이 종료됩니다.
시작점[2]가 중간점[2]와 같아지는 지점입니다.
전체 데이터의 수가 10개였지만, 3번의 탐색 과정으로 원하던 원소를 찾을 수 있었습니다.
이진 탐색과 퀵 정렬
이진 탐색은 한 번 탐색할 때마다 탐색해야 할 원소의 개수가 절반씩 줄어든다는 장점이 있습니다. 그래서 시간 복잡도가 O(logN)입니다.
절반씩 데이터를 줄어들도록 만든다는 점에서 퀵 정렬과 공통점이 있습니다. (이 부분은 추후에 공부를 해야할 것 같습니다!)
책에 나오는 부가 설명에 따르면, 데이터의 개수가 32개일 때 1단계만 거치면 이상적인 경우 16개 가량의 데이터가 남게 됩니다. 2단계를 거치면 8개, 3단계를 거치면 4개...
즉, 단계마다 2를 나누는 것과 동일하므로 연산 횟수는 에 비례하며, 빅오 표기법에 따라 O(logN)이라고 작성합니다.
이진 탐색 구현 방법
이진 탐색을 구현하는 방법에는 두 가지 방법이 있습니다.
- 재귀 함수를 이용하는 방법
- 단순한 반복문을 이용하는 방법
코드로 알아보겠습니다.
1. 재귀 함수로 구현한 이진 탐색 소스코드
# 이진 탐색 소스코드 구현(재귀 함수)
def binary_search(array, target, start, end):
if start > end:
return None
mid = (start + end) // 2
# 찾은 경우 중간점 인덱스 반환
if array[mid] == target:
return mid
# 중간점의 값보다 찾고자 하는 값이 작은 경우 왼쪽 확인
elif array[mid] > target:
return binary_search(array, target, start, mid -1)
else:
return binary_search(array, target, mid+1, end)
# n과 target을 입력 받기 (n: 원소의 개수, target: 찾고자 하는 문자열)
n, target = list(map(int, input().split()))
# 전체 원소 입력 받기
array = list(map(int, input()))
# 이진 탐색 수행 결과 출력
result = binary_search(array, target, 0, n-1)
if result == None:
print('원소가 존재하지 않습니다.')
else:
print(result+1)10 7
1 3 5 7 9 11 13 15 17 19
410 7
1 3 5 6 9 11 13 15 17 19
원소가 존재하지 않습니다.mid = (start + end) // 2는 중간점을 의미합니다.
아래는 단순하게 반복문을 사용한 코드입니다. 실행 결과는 재귀 함수와 같으므로 생략하겠습니다.
2. 반복문으로 구현한 이진 탐색 소스코드
# 이진 탐색 소스코드 구현(반복문)
def binary_search(array, target, start, end):
while start <= end:
mid = (start+end) // 2
# 찾은 경우 중간점 인덱스 반환
if array[mid] == target:
return mid
# 중간점의 값보다 찾고자 하는 값이 작은 경우 왼쪽 확인
elif array[mid] > target:
end = mid - 1
# 중간점의 값보다 찾고자 하는 값이 큰 경우 오른쪽 확인
else:
start = mid + 1
return None
# n과 target을 입력 받기 (n: 원소의 개수, target: 찾고자 하는 문자열)
n, target = list(map(int, input().split()))
# 전체 원소 입력 받기
array = list(map(int, input()))
# 이진 탐색 수행 결과 출력
result = binary_search(array, target, 0, n-1)
if result == None:
print('원소가 존재하지 않습니다.')
else:
print(result+1) 트리 자료구조
이진 탐색은 전제 조건이 데이터 정렬입니다. 동작하는 프로그램에서 데이터를 정렬해두는 경우가 많으므로 이진 탐색을 효과적으로 사용할 수 있습니다.
데이터베이스는 내부적으로 대용량 데이터 처리에 적합한 트리 자료구조를 이용하여 항상 데이터가 정렬되어 있습니다.
따라서 데이터베이스에서의 탐색은 이진 탐색과 조금 다르지만, 이진 탐색과 유사한 방법을 사용하여 탐색을 빠르게 수행하도록 설계되어 있습니다. 그래서 데이터가 많아도 탐색하는 속도가 빠릅니다.
트리 자료구조는 아래 그림을 통해 보겠습니다.
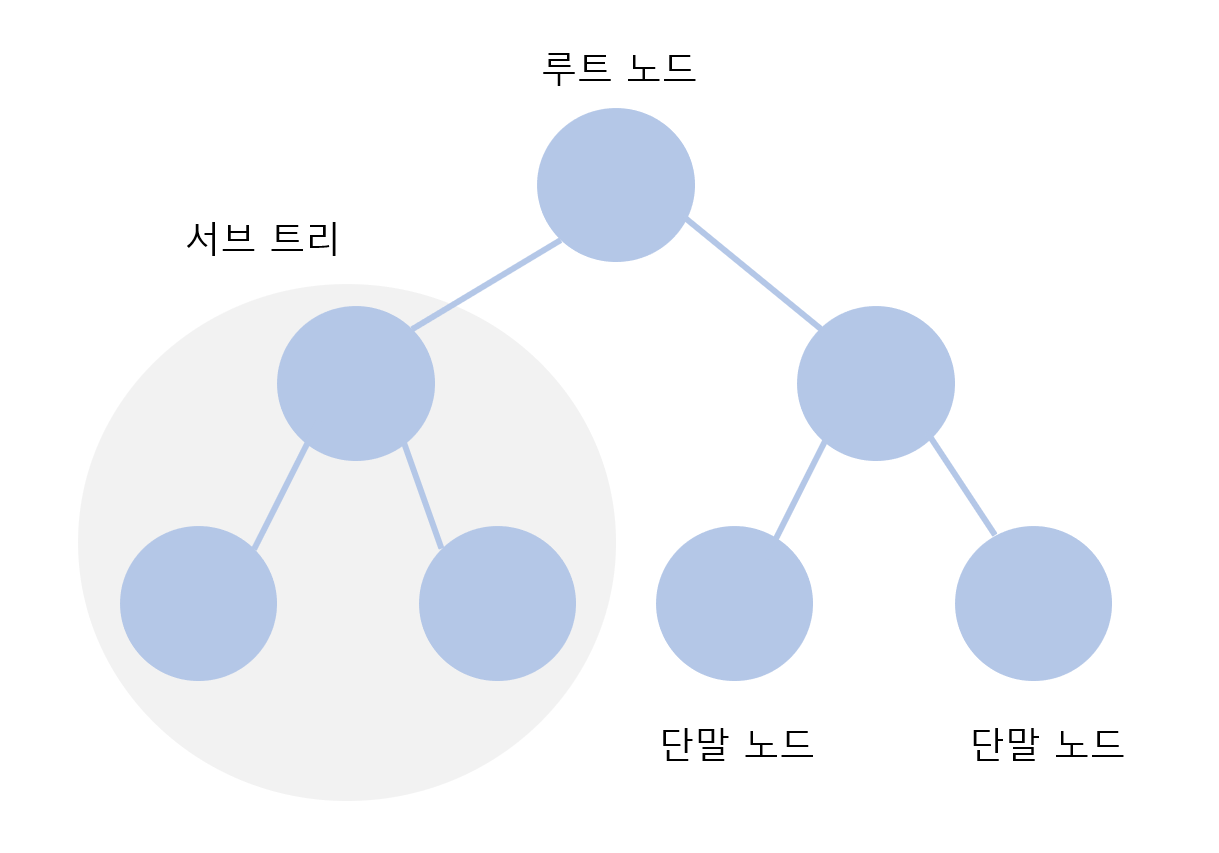
트리 자료구조는 노드와 노드의 연결로 표현할 수 있습니다. 또한, 노드는 정보의 단위로서 어떠한 정보를 가지고 있는 개체로 이해하면 됩니다.
트리 자료구조는 그래프 자료구조의 일종으로 데이터베이스 시스템이나 파일 시스템 같은 곳에서 많은 양의 데이터를 관리하기 위한 목적으로 사용합니다.
- 트리는
부모 노드와자식 노드의 관계로 표현한다. - 트리는 최상단 노드를
루트 노드라 한다. - 트리는 최하단 노드를
단말 노드라 한다. - 트리에서 일부를 떼어내도 트리 구조이며 이를
서브 트리라 한다. - 트리는 파일 시스템과 같이 계층적이고 정렬된 데이터를 다루기에 적합하다.
대용량 데이터를 처리하는 SW는 대부분 데이터를 트리 자료구조로 저장해서 이진 탐색과 같은 탐색 기법을 이용해 빠르게 탐색이 가능합니다.
이진 탐색 트리
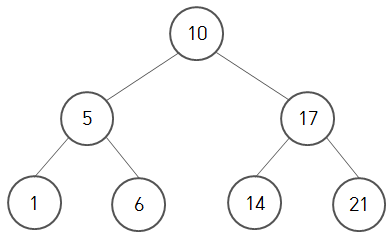
https://blog.hexabrain.net/248
위 그림은 이진 탐색 트리입니다. 하지만 위의 구조를 가졌다고 모든 트리가 다 이진 트리는 아닙니다.
이진 탐색 트리는 아래와 같은 특징을 가집니다.
- 부모 노드보다 왼쪽 자식 노드가 작다.
- 부모 노드보다 오른쪽 자식 노드가 크다.
부모노드가 10, 자식 노드 5는 부모노드 보다 작아서 왼쪽, 17은 커서 오른쪽에 위치합니다.
조금 더 간단히 정리하면
왼쪽 자식 노드 < 부모 노드 < 오른쪽 자식 노드
가 성립됩니다.
이진 탐핵 트리가 미리 구현되어 있다고 가정하고 데이터를 조회하는 과정만 살펴보겠습니다.
다시 위의 그림을 데려와 원소가 14일 때 찾는 방법을 살펴보겠습니다.
step 1
루트 노드 10부터 방문합니다. 찾는 원소는 14입니다. 공식에 따라 왼쪽에 있는 노드는 확인할 필요가 없어지겠죠? 따라서 오른쪽 노드를 방문합니다.
step 2
오른쪽 자식 노드는 17입니다. 이번에는 찾는 원소값(14)보다 큽니다. 그렇다면 공식에 따라 부모 노드(17)에서 오른쪽 노드는 17보다 크므로 확인할 필요가 없어집니다.
따라서 왼쪽 노드를 방문합니다.
step 3
현재 방문한 노드의 값은 찾는 원소값 14와 동일합니다. 따라서 탐색을 마칩니다.
이진 탐색에서 데이터 조회하는 방법은 루트 노드부터 탐색을 시작해서 왼쪽 자식과 오른쪽 자식 노드로 이동하며 반복적으로 방문합니다.
자식 노드가 없을 때까지 원소를 찾지 못했다면, 이진 탐색 트리에 원소가 없는 것입니다.
이진 트리가 아무리 깊어도 탐색 과정은 위와 동일합니다.
빠르게 입력 받는 법
코딩 테스트 문제에서 이진 탐색 문제의 입력 데이터를 빠르게 입력 받는 방법입니다. 만약 1,000만 개를 넘어가거나 탐색 범위의 크기가 1,000억 이상이면 이진 탐색 알고리즘을 의심해봐야 합니다.
입력 데이터의 수가 많은 경우 input()을 그대로 사용하면 동작 속도가 느려 시간이 초과하게 됩니다.
그러므로 sys 라이브러리의 readline() 함수를 이용하면 시간 초과를 피할 수 있습니다!
한 줄 입력받아 출력하는 소스코드
import sys
# 하나의 문자열 데이터 입력받기
input_data = sys.stdin.readline().rstrip()
# 입력받은 문자열 그대로 출력
print(input_data)Hello, Coding Test!
Hello, Coding Test!sys 라이브러리 사용시, 한 줄 입력받고 나서 rstrip() 함수를 꼭 호출해야 readline() 사용할 때 생기는 줄바꿈 기호를 제거해줍니다.
여기까지 이진 탐색 트리를 살펴보기 위해 순차 탐색, 이진 탐색의 개념까지 살펴보았습니다.👏 수고하셨습니다.
