Data augmentation란? 데이터 증강 방법과 예시
Data augmentation이란?
Data augmentation는 갖고 있는 데이터셋을 여러 가지 방법으로 augment하여 실질적인 학습 데이터셋의 규모를 키울 수 있는 방법입니다.
Andrew Ng의 Data augmentation 소개 영상을 통해 이 개념을 잘 이해해봅시다!
CV 작업은 더 많은 데이터를 사용할 수 있습니다. 여기서 Data augmentation은 컴퓨터 비전의 성능을 향상시키는 기술의 일종입니다. CV model을 train할 때 Data augmentation는 많은 도움이 됩니다!
Data augmentation의 방법
Common augmentation method
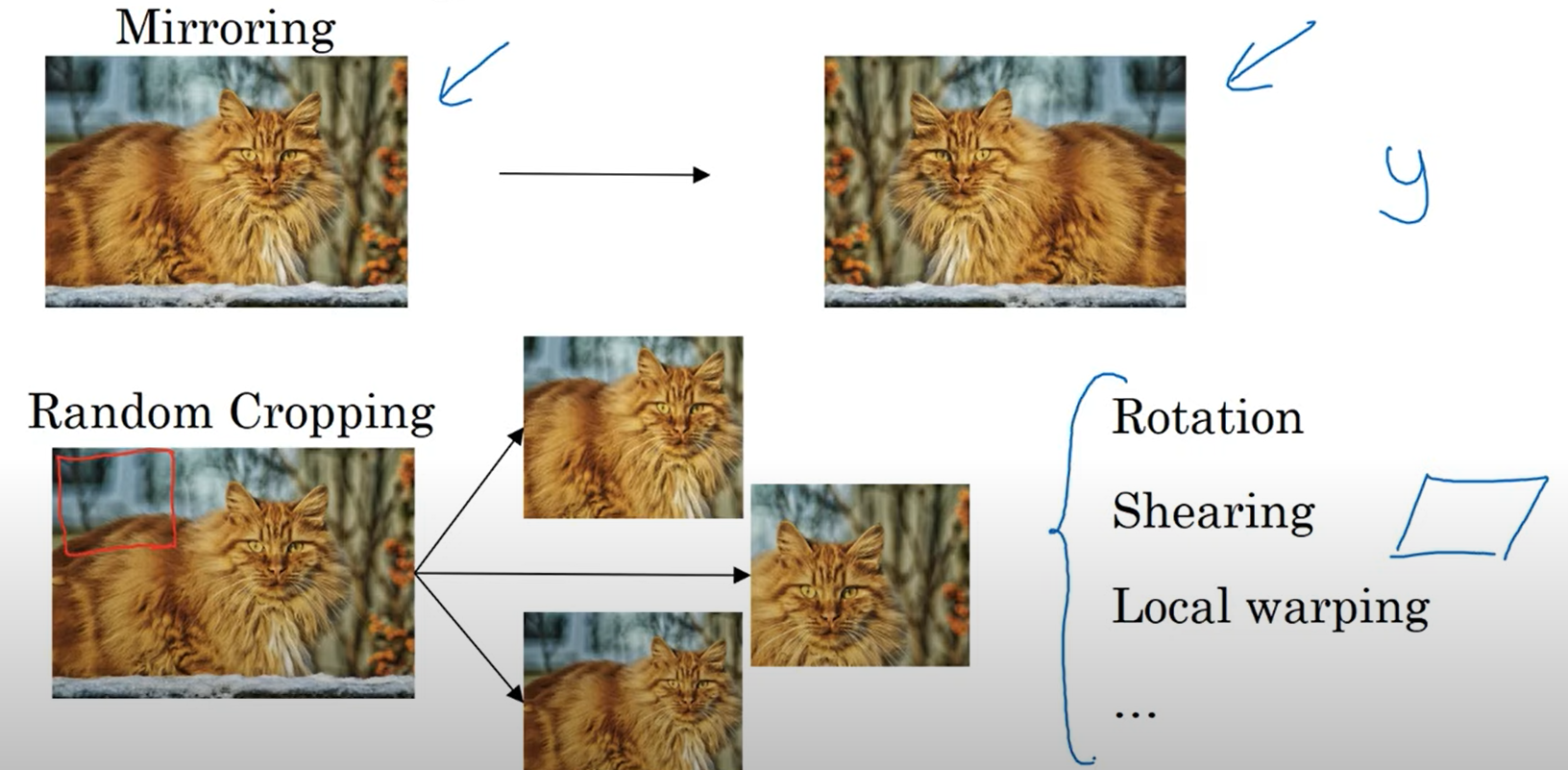
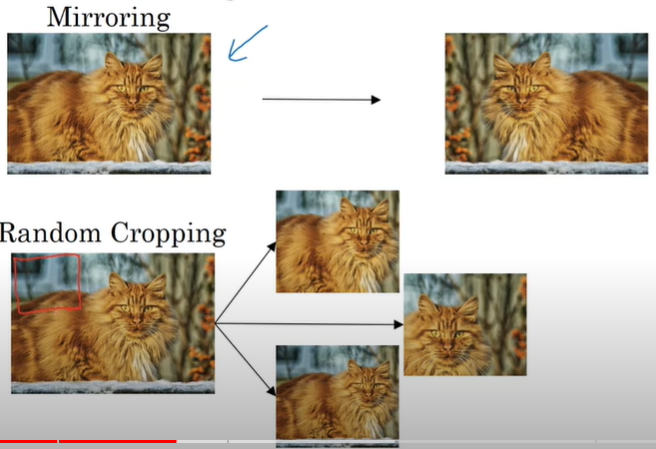
- Mirroring (대칭)
- Random Cropping
- Roatation
- Shearing
- Local wraping
- ...
등이 있습니다.
Color shifting
RGB를 이용한 색변환 방법이 있습니다.
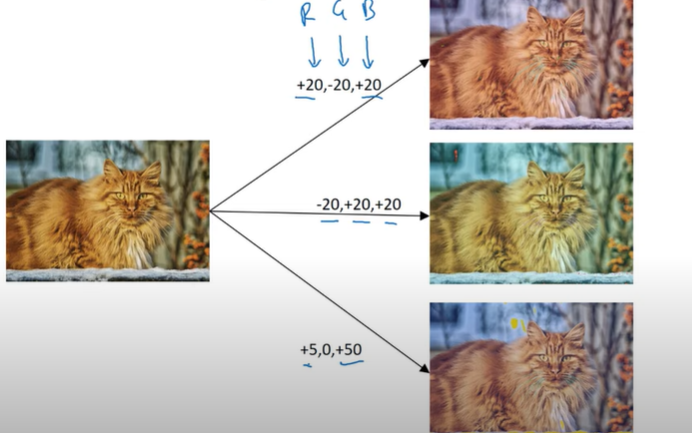
실제로 RGB 값이 특정 확률 분포에 따라 정해집니다. 왼쪽의 고양이는 y로 변하지 않습니다. 색변형을 통해 학습 알고리즘이 색의 변화에 더 잘 반응할 수 있게 해줍니다.
색 변형하는 방법 중 하나로 PCA(주성분 분석) 방법이 있습니다. (AlexNet의 논문에도 언급되어 있습니다.)
Implementing distorions during training
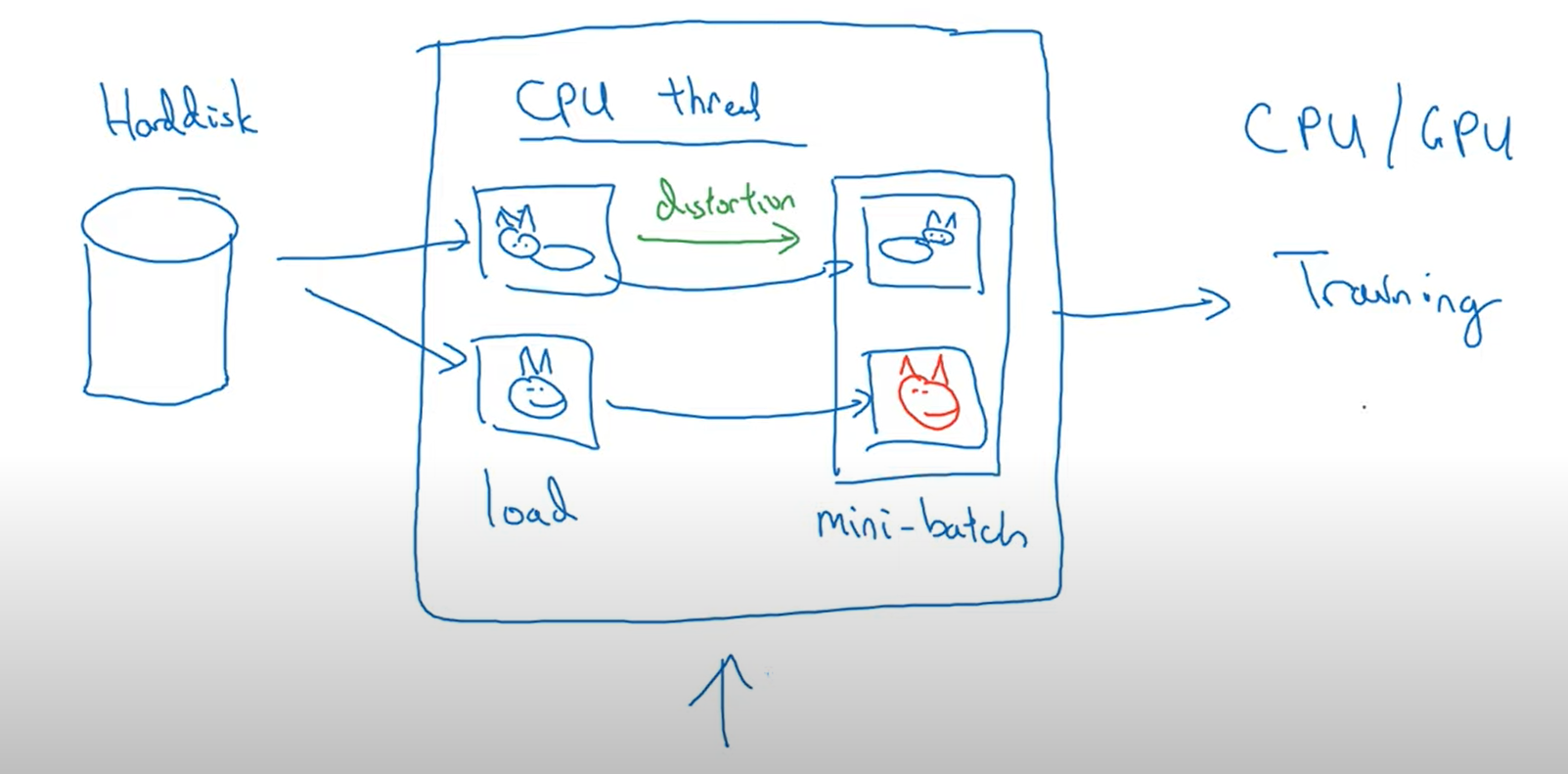
데이터 확대를 구현하는 일반적인 방법은 이런 하나의 thread나 혹은 multi-thread로 데이터를 불러오고 변형을 구현해주고 그것을 다른 thread나 process에 전달해준 뒤 학습을 실행할 수 있습니다.
정리
데이터가 많아진다는 것은 overfitting을 줄일 수 있다는 것을 의미합니다. 갖고 있는 데이터셋이 실제 상황에서의 입력값과 다를 경우, augmentation을 통해 실제 입력값과 비슷한 데이터 분포를 만들 수 있습니다.
예를 들어, 학습한 데이터는 노이즈가 많이 없는 사진이지만 테스트 이미지는 다양한 노이즈가 있는 경우 테스트에서 좋은 성능을 내기 위해서는 노이즈의 분포를 예측하고 학습 데이터에 노이즈를 삽입하여 모델이 노이즈에 잘 대응할 수 있도록 해야 합니다.
Data augmentation는 데이터를 늘릴 뿐 아니라 모델이 실제로 환경에서 잘 동작할 수 있도록 도와줍니다.
Image Data augmentation
Image Data의 augmentation은 포토샵, SNS 사진 필터, 카메라 앱의 기능과 비슷합니다. 인스타 사진을 업로드 할 때 사용하는 필터도 동일합니다.
또 사진 편집 기능에서 좌우 대칭이나 상하 반전 등의 공간적 배치 조작도 가능합니다.

4개의 댓글

모델 overfitting을 막기 위해 Data Augmentation을 검색하다가 들어오니 수연님 블로그네요! 덕분에 또 한 번 좋은 자료 읽었습니다. 감사합니다 :)
또또또? 모르는거 검색만하면 여기로 오네요! 블로그에 좋은글들 항상 감사합니다~