Paper link: arxiv.org/abs/2307.11978
Code link: github.com/CEWu/PTNL
이 논문은 실험으로 결과를 입증하고 설득하는 형식이라서 table을 통해 설명을 이어갈 것 같습니다.
이걸 일주일 동안 붙잡으며 읽은 결과, 복잡한 architecture 그림과 복잡한 수식의 method가 없어서 겉으로 보기엔 쉬워 보이나 의외로 쉬운 논문은 아니고 vision-language 쪽을 한 번 싹 정리하며 unsupervised 까지 맛보고 싶다면 좋은 논문인 것 같아 필요하다고 판단된다면 추천 드리는 논문입니다.
Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels?
Abstract
CLIP과 같은 vision-language model은 규모가 큰 학습 데이터로 일반적인 text-image 임베딩을 학습합니다. 많은 데이터를 확보하여 더 일반적인 임베딩을 구성할 수 있었다고 볼 수 있습니다. 이제 vl model을 few-shot prompt tuning을 통해 새 분류 작업에 적응 시켜야 하는데, 저자들은 프롬프트 튜닝이 noise label에 robust 하다는 것을 발견했다고 합니다. 이것이 이 논문의 주제에 대해 직관적인 질문을 던지는 주제가 됩니다.
따라서 프롬프트 튜닝의 패러다임의 robustness에 대한 요인이 무엇인지를 찾기 위해 다양한 실험을 진행하였고, 주요 요인으로 찾은 것은 1) 고정된 classname token은 noisy sample에 대한 gradient를 줄이면서 모델의 최적화에 강한 정규화 효과를 준다, 2) web data로부터 다양하고 일반적으로 사전 지식을 학습하여 효과적인 image-text 임베딩은 이미지 분류에 있어 좋은 사전 지식을 준다는 것입니다. 또한, CLIP의 노이즈가 없는 제로샷 예측을 사용하여 자체 프롬프트를 조정함으로써 비지도 환경에서 예측 정확도를 크게 향상시킬 수 있음을 입증했습니다.
여기서 드는 의문은 own prompt란 무엇인가? 에 대한 의문이었는데, learnable context 가 튜닝되는 prompt tuning 세팅에서 가장 noise label에 robust 했다는 것을 보면, "a photo of" 등으로 handcrafted prompt 설계에도 어느 정도 도움을 줄 수 있다는 말을 하는 것 같긴 합니다.
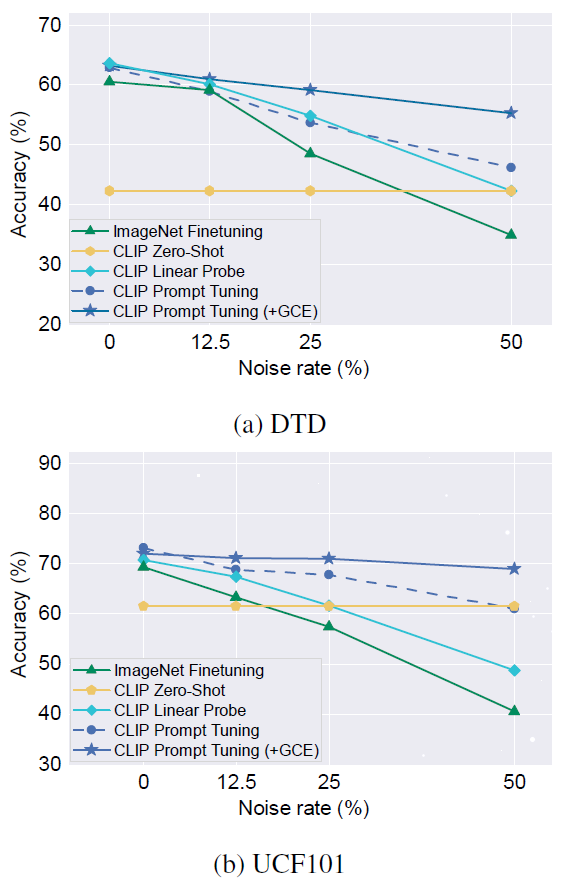
fig. 1
figure 1을 보면 noisy label에 대한 비율을 조절하며 transfer learning한 두 데이터셋의 비교 결과를 보여줍니다. ImageNet Finetuning은 이미지넷에 사전 학습된 모델을 tuning한 결과입니다. CLIP의 사전학습 모델은 Linear probe 방법 보다 더 robust하다는 것을 보여주고 있으며, GCE(generalized cross-entropy)를 사용했을 때, 더 성능 유지가 잘 되는 것을 보여줍니다. 여기서 모든 image encoder로는 ResNet-50을 동일하게 사용하였습니다.
논문을 이해하기 위해 background가 많이 필요하다고 생각합니다.
1) Vision-language model에 대한 이해 (CLIP, CoOp model 등)
2) Generalized cross entropy (robustness를 enhance하기 위해 사용한 loss fucntion)
3) unsupervised learning에 대한 개념
이 세 가지가 결국 contribution과 직결합니다.
Introduction
CLIP과 같은 대규모 vision-language model은 visual representation을 어떻게 학습해야하는지를 변화시켰습니다. 이런 모델은 textual description과 natural image를 함께 align 시켜서 모델을 학습시켰고, 사전 학습된 text encoder를 사용하여서 "A photo of a "와 같은 표준적인 문장을 인코딩하여 클래스 임베딩을 얻었습니다. 그러나 이런 인간이 정의한 문장은 동일한 의미지만 다른 description에서는 상이한 결과를 내놓아서 불안정함을 보여주었습니다.
이런 한계점을 해결하기 위해 CoOp은 prompt tuning을 제안하였는데, 학습 가능한 프롬프트는 작은 타겟 데이터셋만으로 튜닝되었습니다. 결과적으로 프롬프트 튜닝은 여러 downstream task에 vl model을 적용 시키며 큰 인기를 얻었습니다.
저자는 이 두 플로우에서 제외되었던 한 관점에 집중합니다. 바로 모두 perfect 한 label을 가진 dataset으로만 학습 시킨 supervised learning 방식이었단 점입니다. noise label은 real-world setting과 맞닿아 있고, 비지도 학습의 확장과 이어지기 때문에 robustness를 가능하게 하는 메커니즘을 조사하기 시작합니다.
가설: vl model의 text와 image의 임베딩이 분류 공간의 구조를 제공한다. 예를 들면, 어떤 클래스가 가장 유사하고 가장 다른지 임베딩 공간에서 충분히 표현되는가)
모델 정보 기반의 구조는 noise label이 존재해도 데이터에 존재하는 구조의 성능 감소를 막을 것이다.
검증: noisy labeled data로 prompt tuning task를 광범위하게 실험을 수행한다.
구조화된 label sapce에 의해 부여된 robustness 외에도, 이상값의 영향을 완화하는 견고한 손실함수를 사용하여서 학습 가능한 프롬프트를 훈련할 때, 이러한 robustness를 더 향상 시킬 수 있었음을 보여줍니다.
발견한 점
-
prompt tuning이 fine-tuning과 linear probing보다 분류 성능이 더 좋았다.
-
각 클래스 별로 learning prompt를 제공하는 것은 적응을 위해 필요한데, class name을 프롬프트에 고정시키면 클래스 임베딩이 더 강하게 정규화되어 noisy label에 대한 과적합을 방지하였다.
-
CLIP zero-shot prediction은 자체 프롬프트에 사용될 수 있고, 예측 결과를 더 높였다.
Contribution
사전 학습된 vl model을 위한 prompt tuning은 전통적인 transfer learning 접근 보다 noisy label에 더 강건합니다. 이는 GCD 같은 nosie에 강한 목적 함수를 사용했을 때, 더 강화할 수 있었습니다. 또한, 어떠한 요인에서 강건성을 부여하는지를 비교 실험하여 알 수 있었고 이를 통해 unsupervised prompt tuning에서 더 효과적인 성능을 달성할 수 있음을 보여주었습니다.
실험 결과가 아래의 6개 구조로 이름이 붙여져 비교하고 있으니 설명을 통해 무엇이 다른지 확인해보세요.
Red - trained / Gray - Frozen
Claasifier-R (a)
CLIP의 사전 학습된 visual encoder의 output에 linear probe 학습한 것
lassifier-C (b)
Claasifier-R과 비슷한데, 분류기 가중치는 handcrafted prompt에 CLIP의 사전 학습된 텍스트 인코더로부터 얻은 텍스트 임베딩 를 사용하여 초기화한다.
TEnc-FT (c)
코사인 유사도를 계산하여 이미지 임베딩 을 클립의 올바른 텍스트 임베딩 에 연결하여, CLIP classifier를 학습 시킨다.
Prompt Tuning (d)
classname token은 고정 시킨 상태로 learnable context만 학습 시키는 방법
Full-Prompt-Tuining (e)
original learnable tokens과 classname을 결합하여 전부 학습 시키는 방법
CLS-Tuning (f)
"A photo of a " 의 고정된 템플릿 프롬프트를 적용하고, 오로지 classname token만 최적화 시키는 방법
CLIP은 downstream task를 위해 text 입력값을 디자인하는 prompt engineering을 통해 zero-shot transfer를 진행하였습니다. 특히 이미지 분류의 경우, 을 포함하는 정규화된 이미지는 CLIP의 시각 인코더에 이미지 를 전달하고, "A photo of a " 형식 템플릿 프롬프트를 텍스트 인코더에 입력하면 일련의 정규화된 클래스 임베딩 로 정규화된 클레스 임베딩 세트를 얻습니다.
추정식은 이와 같습니다.
는 temperature factor이며, sim은 코사인 유사도를 의미합니다.
Prompt Tuning
zero-shot transfer에 능한 CLIP은 text prompt 디자인에 대해 예민했습니다. "a"의 유무에 따라 5%까지 성능 차이가 발생했습니다. 이러한 hand-crafted prompts을 필요로하지 않으면서, 전이 학습 성능을 올리기 위해 CoOp이 text prompt를 타겟 데이터셋에 최적화 할 수 있는 continuous soft prompt로 대체하였습니다.
특히, class 의 이름은 를 포함하는 클래스 이름으로 변환되고, 모든 클래스에서 공유되는 개의 학습 가능한 토큰 시퀀스가 앞에 붙습니다.
각 클래스에 대한 full prompt는 클립의 텍스트 인코더에서 처리되어 text embedding 을 계산하고, class posteriors 는 위의 수식으로부터 얻어집니다.
타겟 데이터셋에 프롬프트를 적응시키기 위해, CoOp은 공유된 학습 가능한 토큰을 작은 레이블이 지정된 데이터 집합에 최적화하여 cross-entropy를 최소화합니다.
Robust Prompt Tuning
이 작업에선 CoOp의 prompt tuning 프레임워크를 사용하여 noisy label에 대한 강건성을 보여주었습니다. 여기선 generalized cross-entropy (GCE)를 사용했을 때 더 강건성이 강화됨을 말합니다.
GCE는 일 때, 표준 CE와 동일하고 일 때, MAE와 동일합니다. (논문에서는 x가 0일 때, CE와 같다고 하는데, 오타 같습니다.) 하이퍼파라미터인 는 robust MAE loss와 CE loss 사이에서 robust에 trade-off를 컨트롤합니다.
가장 적절한 는 GCE 논문에서도 0.7이 가장 좋다고 했는데, 이 친구들도 조절해가며 실험했는진 모르겠지만 교차 검증을 통해 0.7이 자기들도 가장 좋았다고 말하고 있습니다.
Experimental Settings
Dataset. OxfordPets, Food101, DTD, UCF101, Flowers102, FGVCAircraf, Caltech101, ImageNet 사용
Backbone. 텍스트 인코더로 Transformer를 시각 인코더 ResNet-50 또는 Vit-B/32를 사용하여 사전 학습된 CLIP model을 채택합니다.
Optimization. 32 배치 사이즈, 50 에포크, SGD와 모멘텀 계수 0.9, lr 0.002
Prompt Tuning Is Robust to Noisy Labels
여기서부터는 figure와 table 그 자체로의 결과 위주입니다.

Linear probe보다 Prompt tuning이 더 좋으며, GCE를 썼을 때 더 robust합니다. 오른쪽으로 갈수록 Noise rate가 높아지니 이에 따라 비교해보시면 됩니다.
Question: Why is prompt tuning for CLIP-like vision-language models more robust than traditional transfer learning against noisy labels?
Robustness Attribution
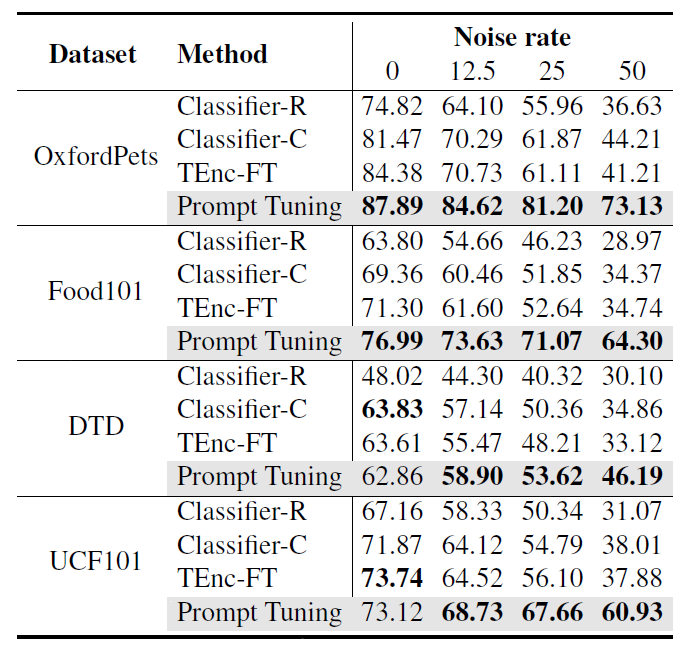
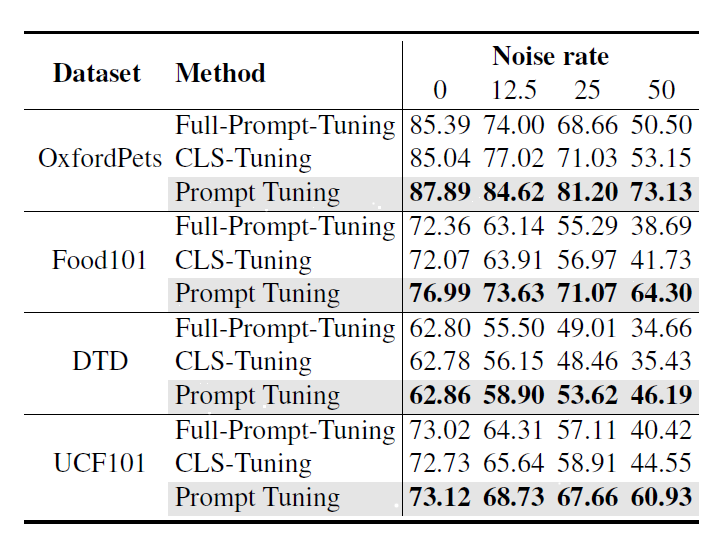
Prompt Tuning 기법이 더 robust합니다.
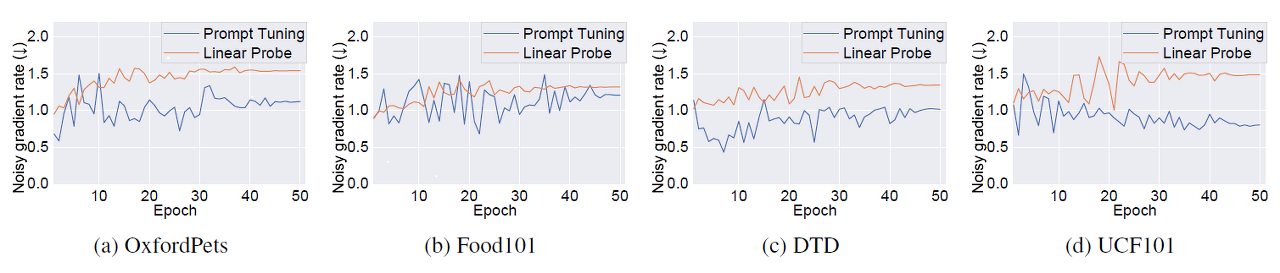
이 figure는 gradient flow를 보여줍니다. Prompt Tuning이 더 안정성 있게 빠르게 수렴하는 것을 볼 수 있습니다.
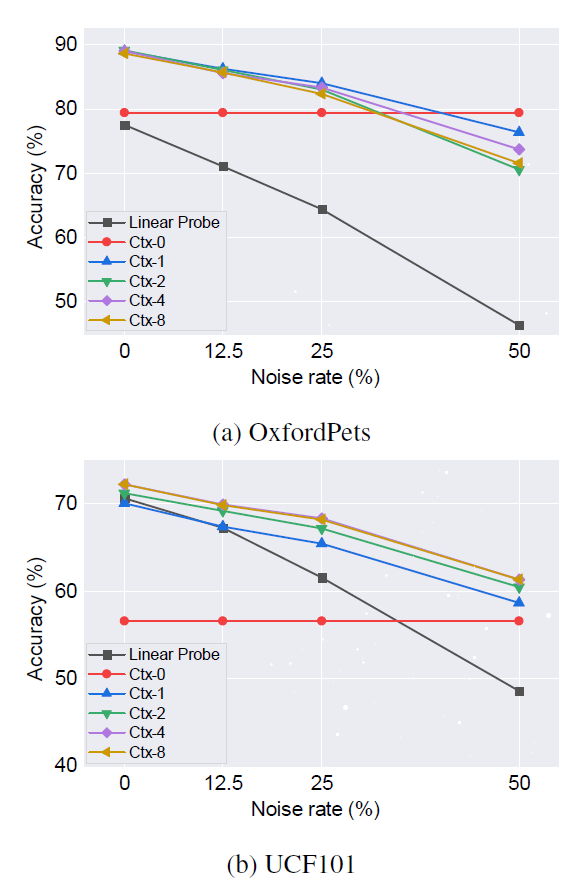
해당 figure는 context length에 따른 강건성을 비교합니다 Ctx-0이 baseline이라고 보시면 됩니다.
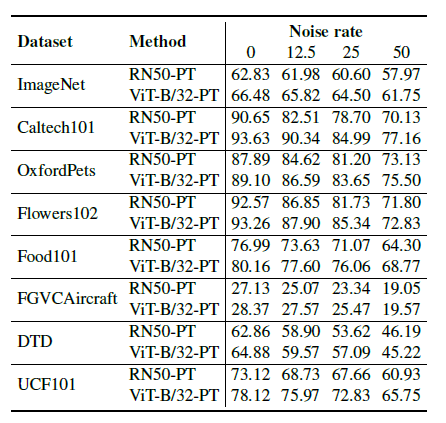
backbone에 따라서도 동일한 결과를 보여주는지 실험합니다.
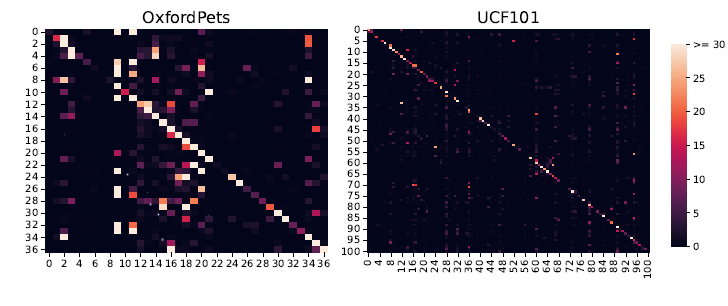
이건 좀 더 확인이 필요한데, random하게 준 것과 더 challenge하게 주었다는 confusion label noise에 대한 차이입니다.
이에 따른 각 클래스에 대한 맞춤 빈도를 보여주는 confusion matrix 결과입니다.
Application to Unsupervised Prompt Tuning
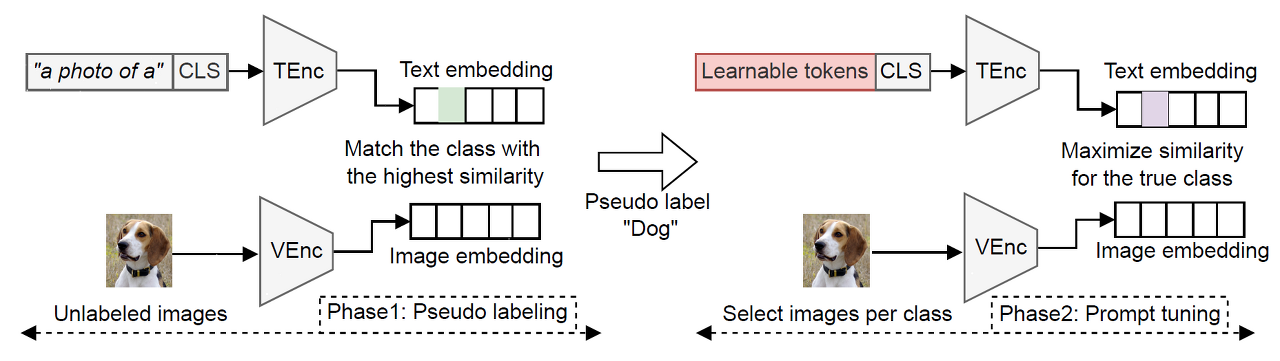
unsupervised prompt tuning의 파이프라인입니다. 2가지 단계로 나뉘어져 있는데, pseudo labeling과 prompt tuning phase입니다.
학습을 하기 위해 "a photo og a " 템플릿과 CLIP으로 zero-shot transfer하여 타겟 데이터셋을 pseudo labeling합니다. 그 다음에는 그후 학습 때, pseudo label로부터 각 클래스마다 샘플을 뽑습니다. 마지막으로 고른 pseud-labeled 샘플을 사용하여 learnable prompt representation을 최적화합니다.
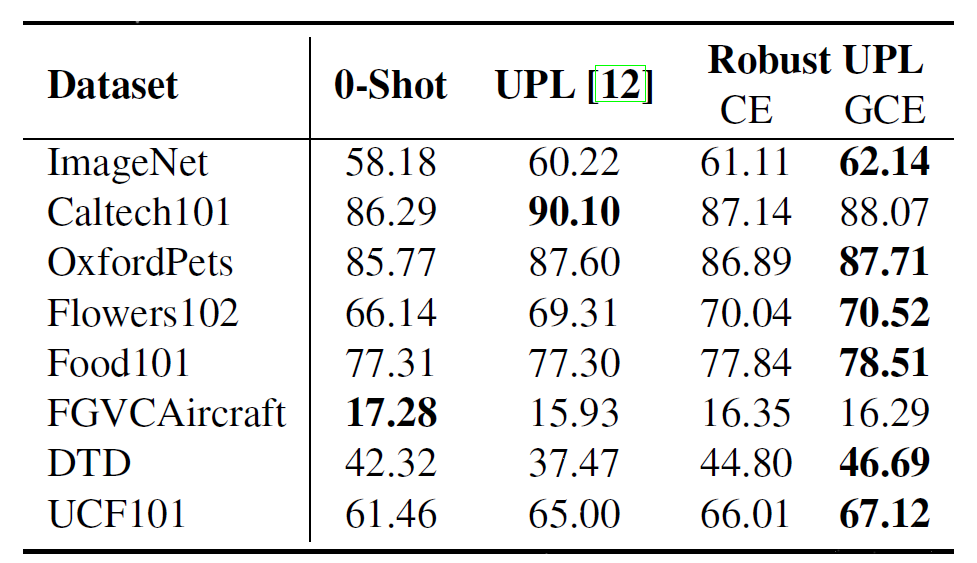
CLIP zero-shot 분류와 UPL(Unsupervised Prompt learning)과 CE를 사용한 UPL, GCE를 사용한 UPL의 비교입니다.
Conclusion
이 논문에서는 대규모 vision-language model의 prompt tuning을 위한 label noiser에 대한 robustness의 포괄적인 연구를 진행하였습니다.
노이즈에 대한 강건성이 클래스 임베딩에 부과된 구조에 기인하였음을 입증하였고, 라벨 노이즈에 의해 gradient가 줄여서 과적합을 방지하였습니다. 다른 모델 구성과 backbone, context length를 설정하여 실험하였습니다.
마지막으로 다양성을 올바른 예측보다 더 우선시하는 새로운 견고한 비지도 프롬프트 튜닝 접근 방식을 제안할 수 있었습니다. 이는 transfer performance를 향상 시키기 위함이라 생각할 수 있습니다.
