[논문 리뷰] FinTextQA: A Dataset for Long-form Financial Question Answering


논문 리뷰
- Title: FinTextQA - A Dataset for Long-form Financial Question Answering
이 논문은 ACL 2024에 게재된 논문입니다. 최근에 읽은 금융 쪽 QA 논문 중 가장 탄탄하고 실험도 의미 있는 논문인 듯 하여 흥미롭게 읽었습니다.
개요
이 논문은 금융 도메인에 특화된 장문형 질의응답(LFQA) 데이터셋인 FinTextQA를 소개하고, RAG 기반 LFQA 시스템을 통한 종합적인 벤치마킹을 수행한 연구입니다.
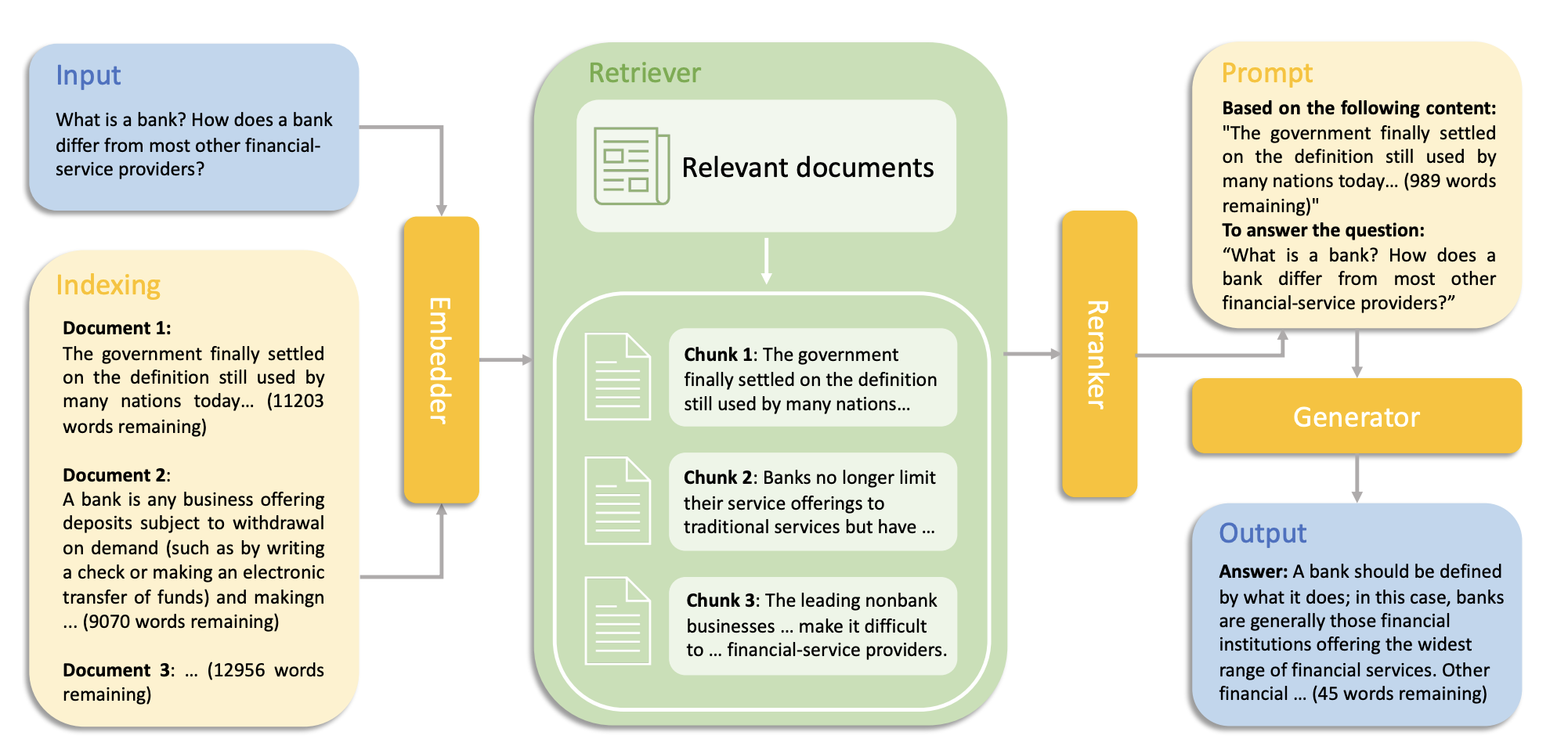
주요 기여점
1. 새로운 데이터셋 구축
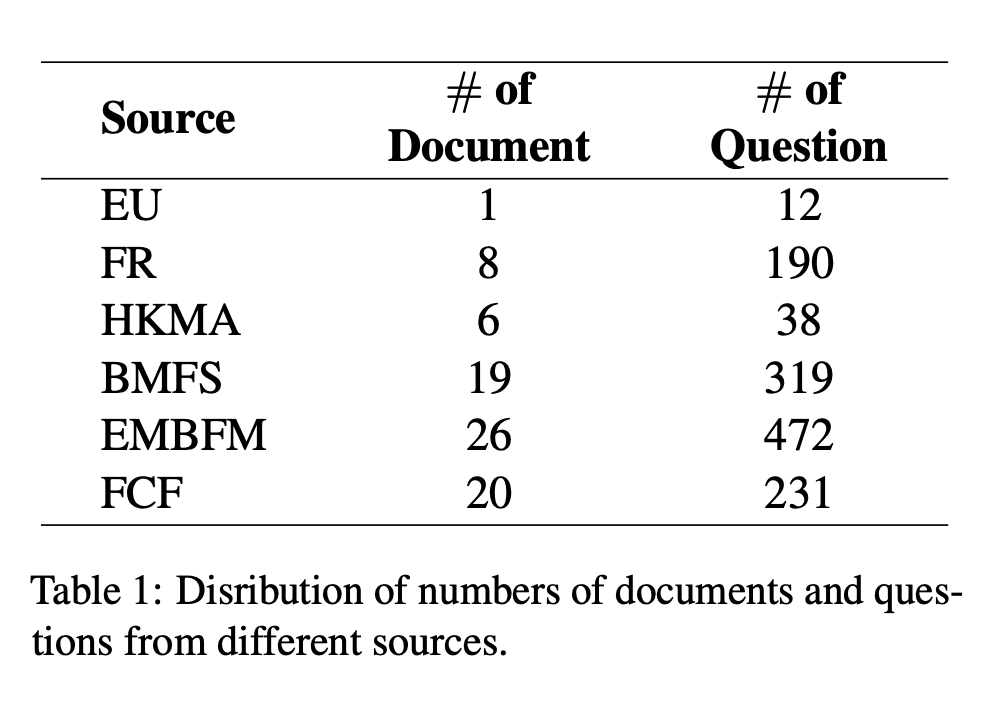
데이터셋을 구성할 때, 체계적으로 접근을 하였습니다.
- 1,262개의 고품질 QA 쌍으로 구성된 금융 LFQA 데이터셋 구축
- 금융 교과서(80.98%)와 정부기관 정책/규제 문서(19.02%)에서 추출
- 평균 질문 길이: 28.5단어, 답변 길이: 75단어, 문서 길이: 19,779.5단어
이러한 데이터 분포는 실제 금융 업무에서 교과서적인 지식과 규제 지식의 비중을 반영하여, 향후 데이터셋 확장 시 균형 조정이 필요함을 시사했습니다.
2. 데이터 품질 보장
- 5단계 인간 주석 과정을 통한 엄격한 품질 관리
- 정책/규제 데이터에 대한 2단계 검증 프로세스:
- 증거 식별 (Evidence identification)
- 관련성 평가 (Relevance evaluation)
3. 종합적인 벤치마킹
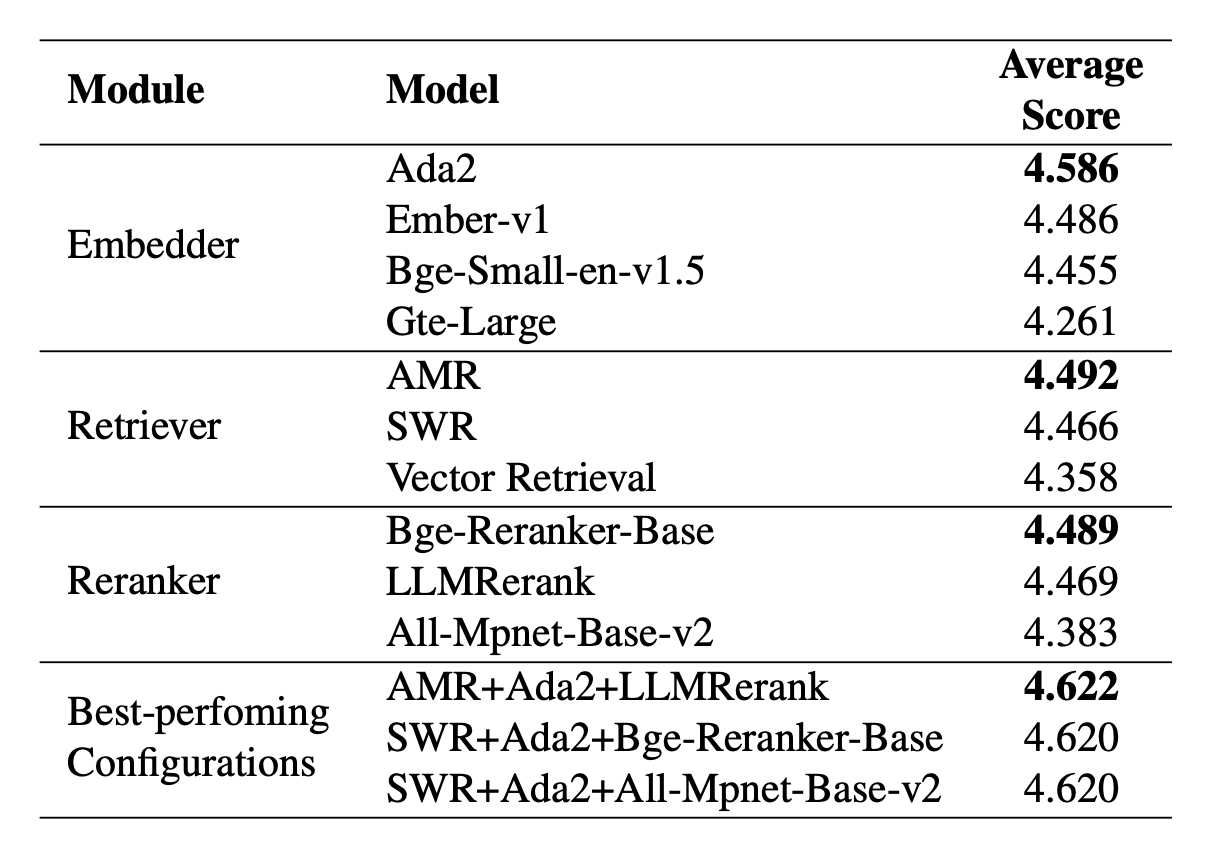
RAG 시스템의 모듈별 성능 분석을 진행했는데,
- RAG 기반 모듈형 시스템 구축 및 평가
- 4개 모듈(embedder, retriever, reranker, generator)의 다양한 조합 테스트
- 인간 평가, 자동 메트릭, GPT-4 점수를 활용한 다면적 평가
Auto Merging Retrieval(AMR)의 계층적 문서 구조화가 금융 도메인의 복잡한 문서에서 효과적임을 입증했습니다. 이는 금융 문서의 특성상 개념 간 연관성이 중요하다는 점을 시사합니다.
4. GPT-4 기반 평가 프롬프트 체계성

평가 프롬프트 구조:
Score 1: 전체적 품질 (도움성, 관련성, 정확성, 깊이, 창의성)
Score 2: 질문-컨텍스트 관련성
Score 3: 컨텍스트-답변 관련성방법론적 기여:
- 다면적 평가: 단순 정확도를 넘어 5가지 차원의 종합 평가
- 편향 방지: 길이, 모델명, 순서에 의한 편향 최소화 지침 포함
- 객관성 강조: "Be as objective as possible" 명시
=> 분석 의의: 이러한 체계적 평가 방법론은 향후 금융 AI 시스템 평가의 표준이 될 수 있으며, 특히 LFQA 태스크에서 자동 메트릭의 한계를 보완하는 효과적인 접근법을 제시합니다.
주요 실험 결과
최적 구성
가장 효과적인 시스템 구성:
- Embedder: Ada2
- Retriever: Auto Merging Retrieval (AMR)
- Reranker: Bge-Reranker-Base
- Generator: Baichuan2-7B
생성 모델 성능
- Baichuan2-7B가 GPT-3.5-turbo와 유사한 정확도 점수를 달성
- 파인튜닝된 모델들이 답변하지 못하는 질문 수는 감소했지만, 전반적 성능 향상은 제한적
노이즈 내성
- 문서 수가 증가할수록 성능이 감소하는 경향
- 컨텍스트 단어 수가 약 34,000단어에 도달하면 추가 문서의 영향이 미미해짐
데이터셋 특징
질문 유형 분포
- "What"으로 시작하는 질문: 36.98%
- "How"로 시작하는 질문: 19.63%
- "Why"로 시작하는 질문: 12.59%
포괄적 범위
6가지 질문 유형을 포함:
- 다회전 질문 (Multi-turn)
- 비교 분석 (Comparative)
- 수치 추론 (Numerical)
- 도메인 지식 (Domain knowledge)
- 개방형 질문 (Open-minded)
- 인과관계 분석 (Cause and Effect)
평가 방법론
다층적 평가 체계
- 자동 메트릭: ROUGE-1, ROUGE-2, ROUGE-L, BLEU
- GPT-4 기반 평가: 도움성, 관련성, 정확성, 깊이, 창의성 평가
- 인간 평가: 3명의 주석자에 의한 순위 평가
한계점
데이터 규모
- AI 생성 대용량 데이터셋 대비 상대적으로 작은 규모
- 실제 응용에서의 일반화 가능성에 대한 우려
저작권 제약
- 고품질 데이터 획득의 어려움
- 저작권 제약으로 인한 데이터 공유 제한
종합 평가
장점
✅ 도메인 특화: 금융 분야 최초의 LFQA 데이터셋
✅ 고품질 데이터: 엄격한 인간 검증 과정
✅ 종합적 벤치마킹: 다양한 모델 조합에 대한 체계적 평가
✅ 실용적 기여: 금융 QA 시스템 개발을 위한 기반 제공
개선 필요사항
❌ 규모 확장: 더 많은 QA 쌍 필요
❌ 다양성 증대: 더 다양한 출처로부터의 데이터 수집 필요
❌ 최신성: 시간에 따른 데이터 업데이트 방안 모색 필요
결론
FinTextQA는 금융 도메인 LFQA 연구의 중요한 이정표를 제시하며, RAG 기반 시스템의 체계적 평가를 통해 실용적인 벤치마크를 제공합니다. 데이터 규모의 한계에도 불구하고, 고품질 데이터와 종합적 평가 방법론을 통해 향후 금융 AI 시스템 개발에 기여할 것으로 평가됩니다.
또한, 단순한 데이터셋 제공을 넘어 시스템적 설계, 방법론적 엄밀성, 실용적 적용성을 모두 고려한 종합적 연구임을 보여줍니다. 특히 모듈별 성능 분석과 컨텍스트 최적화 연구는 실제 금융 AI 시스템 구축에 직접적인 가이드라인을 제공한다는 점에서 높은 실용적 가치를 가집니다.
