시퀀스를 슬라이싱하는 방법을 익히기
파이썬의 슬라이싱은 시퀀스(리스트, 튜플, 문자열 등)의 일부를 효율적으로 가져오거나 수정할 수 있는 강력한 기능입니다. 하지만 제대로 이해하지 못하면 혼란스럽고 버그를 만들어낼 수 있습니다.
1. 기본 슬라이싱 문법
슬라이싱의 기본 형태는 somelist[start:end]입니다.
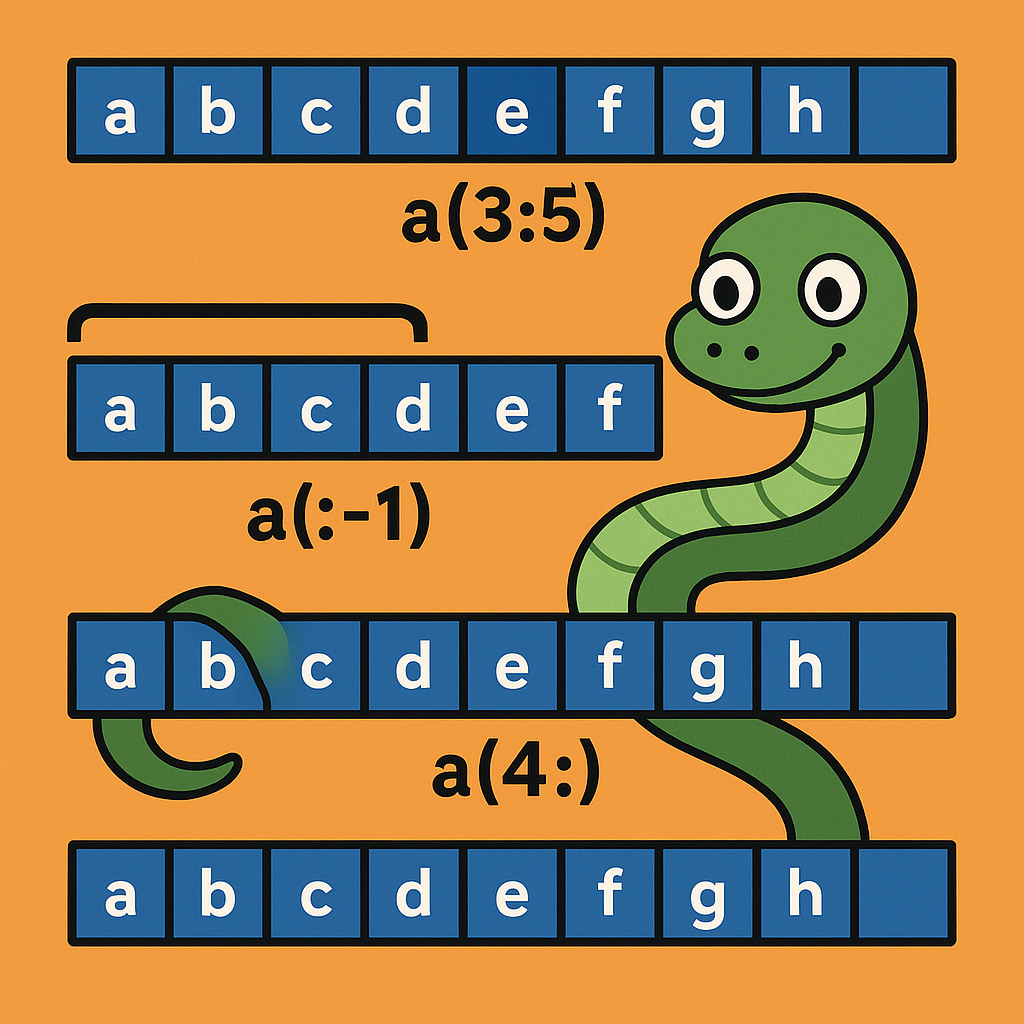
a = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
print('가운데 2개: ', a[3:5]) # ['d', 'e']
print('마지막을 제외한 나머지:', a[1:7]) # ['b', 'c', 'd', 'e', 'f', 'g']핵심 원리:
start인덱스는 포함됩니다end인덱스는 제외됩니다 (end 바로 앞까지만)a[3:5]는 인덱스 3, 4번째 요소를 가져옵니다 (5번째는 제외)
2. 생략 가능한 인덱스들
# 시작 인덱스 생략 (처음부터)
assert a[:5] == a[0:5] # ['a', 'b', 'c', 'd', 'e']
# 끝 인덱스 생략 (끝까지)
assert a[5:] == a[5:len(a)] # ['f', 'g', 'h']
# 둘 다 생략 (전체 복사)
a[:] # ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']가독성 향상을 위한 규칙:
- 처음부터 슬라이싱할 때는
a[:5]처럼 0을 생략하세요 - 끝까지 슬라이싱할 때는
a[4:]처럼 len()을 생략하세요
3. 음수 인덱스 활용
a[:-1] # ['a', 'b', 'c', 'd', 'e', 'f', 'g'] (마지막 요소 제외)
a[-3:] # ['f', 'g', 'h'] (뒤에서 3개)
a[2:-1] # ['c', 'd', 'e', 'f', 'g'] (인덱스 2부터 마지막 전까지)
a[-3:-1] # ['f', 'g'] (뒤에서 3번째부터 마지막 전까지)음수 인덱스의 장점:
- 리스트 길이를 몰라도 뒤에서부터 접근 가능
a[-1]은 마지막 요소,a[-2]는 마지막에서 두 번째 요소
4. 경계를 벗어나는 인덱스 처리
first_twenty_items = a[:20] # 리스트가 8개 요소만 있어도 에러 없음
last_twenty_items = a[-20:] # 마찬가지로 에러 없음슬라이싱의 안전성:
- 일반 인덱싱(
a)은 IndexError를 발생시키지만 - 슬라이싱(
a[:20])은 가능한 범위 내에서만 동작하므로 안전합니다 - 이는 사용자 입력이나 동적 데이터를 다룰 때 매우 유용합니다
5. 슬라이싱과 원본 리스트의 관계
b = a[3:]
print('이전:', b) # ['d', 'e', 'f', 'g', 'h']
b[1] = 99
print('이후:', b) # ['d', 99, 'f', 'g', 'h']
print('변화 없음:', a) # ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']중요한 개념: 새로운 리스트 생성
- 슬라이싱은 새로운 리스트 객체를 만듭니다
- 원본 리스트
a는 영향받지 않습니다 - 이는 데이터를 안전하게 복사하고 수정할 때 유용합니다
6. 슬라이스 할당 (Slice Assignment)
6-1. 같은 길이로 교체
print('이전:', a) # ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
a[2:7] = [99, 22, 14]
print('이후:', a) # ['a', 'b', 99, 22, 14, 'h']6-2. 다른 길이로 교체 (리스트 크기 변경)
print('이전:', a) # ['a', 'b', 99, 22, 14, 'h']
a[2:3] = [47, 11] # 1개 요소를 2개로 교체
print('이후:', a) # ['a', 'b', 47, 11, 22, 14, 'h']슬라이스 할당의 특징:
- 할당하는 요소의 개수가 달라도 됩니다
- 리스트의 크기가 동적으로 조정됩니다
- 이는 리스트 중간에 여러 요소를 삽입하거나 제거할 때 매우 효율적입니다
7. 얕은 복사 vs 참조
7-1. 얕은 복사 만들기
b = a[:] # 전체 슬라이싱으로 복사
assert b == a and b is not a # 내용은 같지만 다른 객체7-2. 기존 리스트 내용 전체 교체
b = a # 같은 객체를 참조
print('이전 a:', a)
print('이전 b:', b)
a[:] = [101, 102, 103] # 기존 리스트 객체의 내용만 교체
assert a is b # 여전히 같은 리스트 객체
print('이후 a:', a) # [101, 102, 103]
print('이후 b:', b) # [101, 102, 103] (같은 객체이므로 동일한 변화)중요한 차이점:
b = a[:]: 새로운 리스트 생성 (얕은 복사)b = a: 같은 리스트를 참조a[:] = [...]: 기존 리스트 객체의 내용만 교체
8. 실제 활용 예시와 베스트 프랙티스
# 1. 안전한 리스트 복사
original = [1, 2, 3, 4, 5]
backup = original[:] # 원본을 안전하게 보관
# 2. 리스트의 특정 부분만 처리
def process_middle_items(items):
middle = items[1:-1] # 첫 번째와 마지막 제외
return [x * 2 for x in middle]
# 3. 대용량 데이터의 청크 처리
def process_in_chunks(data, chunk_size=100):
for i in range(0, len(data), chunk_size):
chunk = data[i:i+chunk_size] # 경계를 벗어나도 안전
yield process_chunk(chunk)최종 정리
슬라이싱은 파이썬에서 시퀀스를 다루는 가장 pythonic한 방법입니다.
- 간결하고 표현력이 좋습니다:
a[2:-1]은 의도가 명확합니다- 경계 안전성: 인덱스 범위를 벗어나도 예외가 발생하지 않습니다
- 유연한 할당: 다른 길이의 시퀀스로도 교체 가능합니다
- 메모리 효율성: 새로운 객체 생성 vs 기존 객체 수정을 명확히 구분할 수 있습니다
슬라이싱을 제대로 익히면 리스트 조작 코드가 훨씬 깔끔하고 읽기 쉬워집니다.

AI/ML Engineer