목차
- Sparse Representation
- Distributed representation
- CBOW(Continuous Bag of Words)
- Skip-gram
원-핫 벡터는 단어 간 유사도를 계산할 수 없다는 단점이 있습니다. 단어 간 유사도를 반영할 수 있도록 단어의 의미를 벡터화 할 필요가 있었습니다.
그중 대표적인 방법이 Word2Vec입니다.
Sparse Representation
원-핫 인코딩을 통해 나온 원-핫 벡터가 Sparse Representation이며, sparse vector라 하였습니다.
sparse vector 문제점이 단어 간 유사성을 표현할 수 없다는 단점이 있었고, 이를 위한 대안으로 단어의 의미를 다차원 공간에 벡터화하는 방법을 찾았습니다.
이를 distributed representation(분산 표현) 이라고 합니다. distributed representation을 이용해 단어의 유사도를 벡터화하는 작업이 워드 임베딩 과정에 속합니다. 그래서 이렇게 표현된 벡터 또한 임베딩 벡터라고 합니다.
저차원을 가지므로 dense vector에도 속합니다.
Distributed representation
distributed representation은 '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다'라는 가정을 갖습니다.
- 강아지는 귀엽다
- 강아지는 예쁘다
- 강아지는 애교가 많다
등의 문장이 있으면 강아지, 예쁘다, 귀엽다, 애교 등이 비슷한 의미를 가졌다고 가설을 세웁니다.
이렇게 단어를 학습하고 벡터에 단어의 의미를 여러 차원으로 분산하여 표현합니다.
그리고 원-핫 벡터처럼 단어 집합이 크지 않으므로 상대적으로 저차원입니다.
요약하면 sparse 표현이 고차원에 각 차원이 분리된 표현 방법이었다면, distributed 표현은 단어 의미를 여러 차원(상대적으로 저차원)에다가 분산하여 표현합니다.
이런 표현 방법을 통해 단어 간 유사도를 계산할 수 있습니다.
CBOW(Continuous Bag of Words)
Word2Vec에는 CBOW(Continuous Bag of Words)와 Skip-Gram 두 가지 방식이 있습니다.
CBOW는 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법입니다.
반대로, Skip-Gram은 중간에 있는 단어로 주변 단어들을 예측하는 방법입니다.
메커니즘 자체는 거의 동일하다고 합니다.
Word2Vec는 NNLM의 느린 학습 속도와 정확도를 개선하여 탄생하였으며, Word2Vec(CBOW)은 워드 임베딩 자체가 목적이므로 다음 단어가 아닌 중심 단어를 예측하게 하여 학습합니다.
중심 단어를 예측하게 하므로서 NNLM이 예측 단어의 이전 단어들만을 참고하였던 것과는 달리, Word2Vec은 예측 단어의 전, 후 단어들을 모두 참고합니다.
예문 : "The fat cat sat on the mat"
예를 들어 korpus에 위와 같은 문장이 있다고 해봅시다.
가운데 단어를 예측하는 것이 CBOW입니다.
{"The", "fat", "cat", "on", "the", "mat"}으로부터 sat를 예측하는 것은 CBOW가 하는 일입니다.
이때 예측해야하는 단어 sat을 center word라 하고, 예측에 사용되는 단어를 context word라고 합니다.
중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지 범위를 window라고 합니다.
window가 2이고 예측하고자 하는 중심 단어가 sat이면 앞의 두 단어인 fat, cat, 그리고 뒤의 두 단어인 on, the를 참고합니다.
window 크기가 n이라면 참고 단어의 개수는 2n입니다.
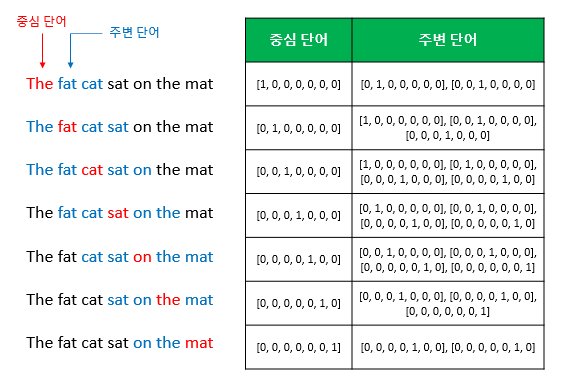
window 크기를 정했다면 winodw를 움직이며 학습을 위한 데이터셋을 만들 수 있고, 이 방법을 sliding window라고 합니다.
위 그림은 CBOW를 위한 전체 데이터 셋을 보여줍니다.
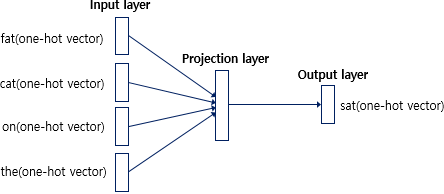
CBOW를 도식화하면 위와 같습니다. 입력층(Input layer)의 입력으로 앞, 뒤로 사용자가 정한 window 크기 범위 안에 있는 주변 단어들의 원-핫 벡터가 들어가게 됩니다.
출력층(Output layer)에서 예측하고자 하는 중간 단어의 원-핫 벡터가 필요합니다.
Word2Vec은 딥러닝 모델(Deep Learning Model)은 아닙니다. 딥러닝은 Input layer와 Output layer 사이에 Hidden layer의 개수가 충분히 쌓은 Neural network를 학습할 때를 의미합니다.
Word2Vec는 하나의 Hidden layer만 존재합니다. 이렇게 Hidden layer가 1개만 존재할 경우, Deep Neural Network이 아닌 Shallow Neural Network라 부릅니다.
Word2Vec는 활성화 함수가 존재하지 않으며, lookup table이라는 연산을 담당하는 층으로 일반적인 은닉층과 구분하기 위해 projection layer라고 부릅니다.
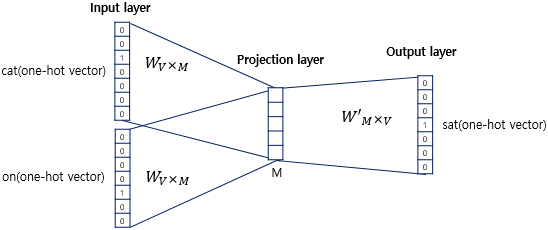
CBOW의 Neural network을 확대하여 동작 메커니즘을 보겠습니다!
이 그림에서 주목해야 할 점은 두 가지가 있습니다.
첫 번째로 projection layer의 크기는 M입니다. CBOW에서 projection layer의 크기 M은 임베딩하고 난 벡터의 차원입니다.
즉, 위 그림에서 projection layer 크기는 M=5이기 때문에 CBOW를 수행하고나서 얻는 각 단어의 임베딩 벡터의 차원은 5가 됩니다.
두 번째로 Input, projection layer 사이의 가중치 W는 V x M 행렬입니다.
여기서 V는 단어 집합의 크기를 의미합니다.
V : 단어 집합의 크기
M : 단어 임베딩 벡터의 차원
즉, 위의 그림처럼 원-핫 벡터의 차원이 7이고, M은 5라면 가중치 W는 7x5 matrix이며, W'는 5x7 matrix가 됩니다.
중요한 점은 W와 W'는 서로 transpose한 관계가 아니고 서로 다른 행렬이라는 점입니다.
인공 신경망 훈련 전 이 가중치 행렬 W와 W'는 대게 굉장히 작은 랜덤 값을 가지게 됩니다.
CBOW는 context word로부터 center word를 정확히 맞추기 위해 W와 W'를 학습해가는 구조입니다!
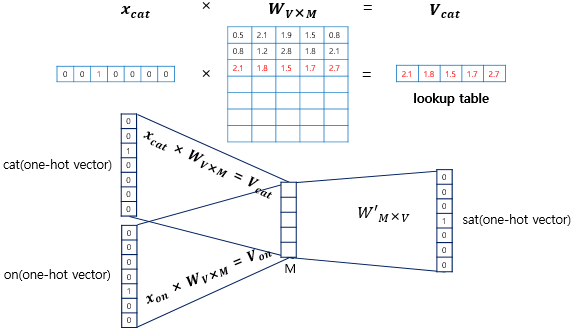
위 그림을 보면 원-핫 벡터는 x이고, input vector와 가중치 W 행렬의 곱은 사실 W 행렬의 i번째 행을 그대로 읽어오는 것(lookup)과 동일합니다.
이 작업을 룩업 테이블(lookup table)이라고 부릅니다!
CBOW의 목적은 W와 W'를 잘 훈련 시키는 것이 목적인데, 여기서 lookup 해온 W의 각 행벡터가 사실 Word2Vec를 수행한 후의 각 단어의 M 차원의 크기를 갖는 임베딩 벡터이기 때문입니다.
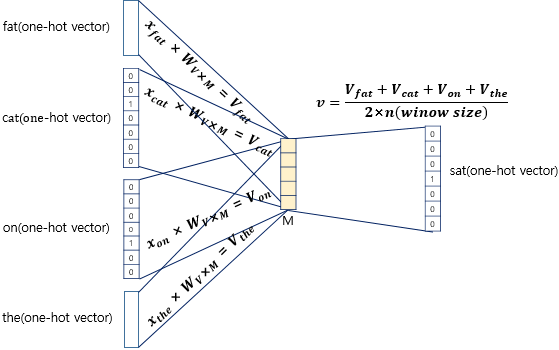
이렇게 각 주변 단어의 원-핫 벡터에 대해서 가중치 W가 곱해서 생겨진 Output Vector은 projection layer에서 만나 이 벡터들의 평균인 벡터를 구하게 됩니다.
앞서 window 크기가 n이라면 input vecter의 개수는 2n이므로 평균을 구할 때는 2n개의 Output vector에 대해 평균을 구합니다.
projection layer에서 vector의 평균을 구하는 부분은 CBOW와 Skip-Gram과 다른 차이점이기도 하빈다. Skip-Gram은 입력이 center word 하나 이기 때문에 projection layer에서 벡터의 평균을 구하지 않습니다.
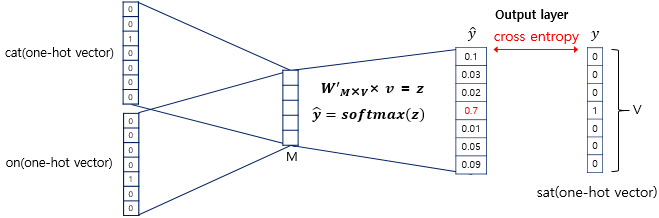
여기서 구한 평균 벡터는 두 번째 가중치 행렬 W'와 곱해집니다.
곱셈의 결과로는 원-핫 벡터들과 차원이 동일한 V로 동일한 벡터가 나옵니다.
이 vector에서는 softmax 함수를 취합니다. softmax function으로 인한 출력값이 0, 1 사이의 실수로 그리고 각 원소의 합이 1이 되는 상태로 바뀝니다.
이렇게 나온 벡터를 score vector라 부릅니다.
score vector의 j번째 인덱스가 가진 0과 1 사이의 값은 j번째 단어가 center word일 확률을 나타냅니다.
그리고 이 스코어 벡터는 우리가 실제로 값을 알고있는 벡터인 중심 단어 원-핫 벡터의 값에 가까워져야 합니다.
score vector을 y-hat이라 하겠습니다. 중심 단어가 y이면 이 두 벡터의 값을 줄이기 위해 CBOW는 loss function으로 cross-entropy 함수를 사용합니다.
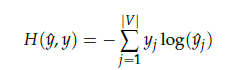
cross-entropy 함수에 실제 중심 단어인 원-핫 벡터와 스코어 벡터를 입력값으로 넣고, 이를 식으로 표현하면 위와 같습니다.
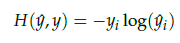
그런데 y가 원-핫 벡터라면 식을 위처럼 간소화 시킬 수 있습니다. 이 식이 loss function으로 적합한 이유는 c를 center word에서 1을 가진 차원의 값의 인덱스라고 한다면, y-hat(c)=1는 y-hat이 y를 정확하게 예측한 경우가 됩니다.
이를 식에 대입하면 -1log(1)=0이 되기 떄문에, 결과적으로 y-hat이 y를 정확하게 예측한 경우의 cross-entropy의 값은 0이 됩니다.
즉,
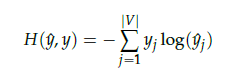
가 최소가 되는 방향으로 학습을 해야합니다.
이제 Back Propagation을 수행하면 W와 W'이 학습되는데, 학습이 다 되면 M차원의 크기를 갖는 W의 행이나 W'의 열로부터 어떤 것을 임베딩 벡터로 사용할지 결정하면 됩니다.
W, W'의 평균치를 갖고 임베딩 벡터를 선택하기도 합니다.
Skip-gram
Skip-gram은 CBOW를 이해했다면 메커니즘 자체는 동일하므로 쉽게 이해할 수 있습니다.
앞서 CBOW에서는 center word를 예측했지만, Skip-gram은 center word에서 context word를 예측합니다.
앞서 언급한 예문을 다시 데려오겠습니다. window=2입니다.
예문 : "The fat cat sat on the mat"
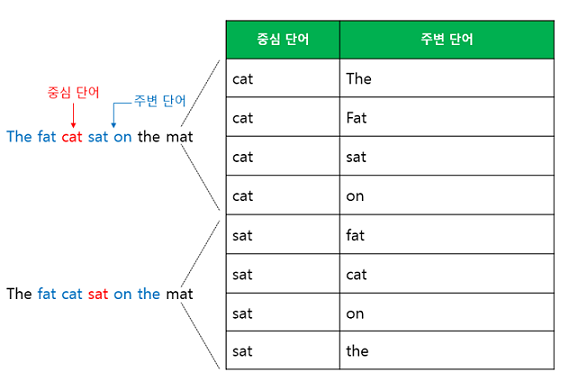
이를 도식화하면
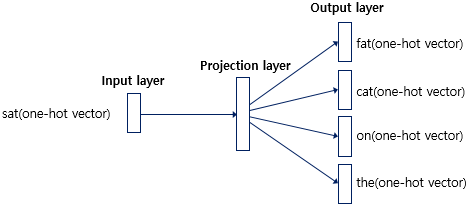
위와 같습니다.
center word에서 context word를 예측하므로 projection layer에서 vector의 평균을 구할 필요가 없습니다.
논문에서 성능 비교시, Skip-gram이 CBOW보다 더 좋은 성능을 갖는다고 합니다.
